
写文章




- @weixin_46556352
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
人工智能 —— 知识图谱
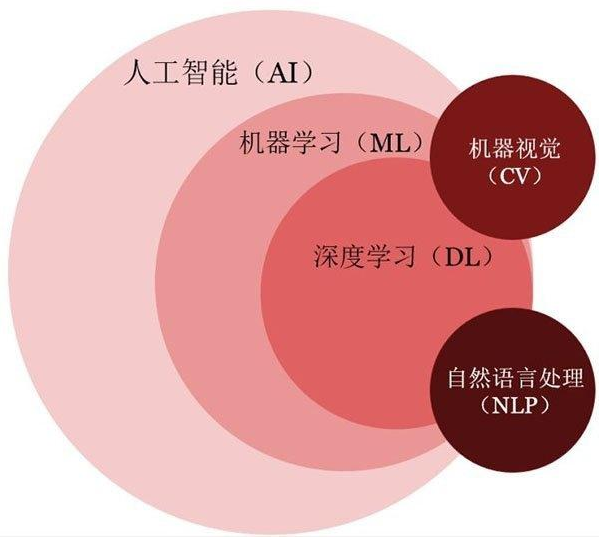
初学者刚开始学习人工智能时,面对铺天盖地的概念,如,人工智能、机器学习、深度学习、计算机视觉等等,一时间可能就被这些“高深”的名称给唬住了,不知道如何下手。又或者有些同学在学习了很长时间后,问他学习的是人工智能的哪一方面,都不能清晰地回答出来,只能回答个大概,也基本上是名词堆砌。所以本篇文章的目的就是理清人工智能方面的概念,与人类智慧进行类比,让你直观感受到什么是人工智能,人工智能在做什么事,是怎
Python项目打包, docker build构建docker镜像, Docker Compose (Docker编配)
将本地Python项目打包构建docker镜像,并在docker中运行【流程1-8】8、Docker Compose (Docker编配)附录: 其他常用docker命令。

pyttsx4文本到语音转换库的基本使用
pyttsx4是 Python 中的文本到语音转换库。与其他库不同,它可以离线工作,并且与 Python 2 和 3 兼容。
人工智能 —— 知识图谱
初学者刚开始学习人工智能时,面对铺天盖地的概念,如,人工智能、机器学习、深度学习、计算机视觉等等,一时间可能就被这些“高深”的名称给唬住了,不知道如何下手。又或者有些同学在学习了很长时间后,问他学习的是人工智能的哪一方面,都不能清晰地回答出来,只能回答个大概,也基本上是名词堆砌。所以本篇文章的目的就是理清人工智能方面的概念,与人类智慧进行类比,让你直观感受到什么是人工智能,人工智能在做什么事,是怎
Python项目打包, docker build构建docker镜像, Docker Compose (Docker编配)
将本地Python项目打包构建docker镜像,并在docker中运行【流程1-8】8、Docker Compose (Docker编配)附录: 其他常用docker命令。
深度学习框架-keras
深度学习框架-keras
transformer模型构建
transformer模型构建