




- @weixin_46530492
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【代码】Claude code源码安装。
【代码】Claude code源码安装。
负责模型的下载、加载和运行,还自带本地API,不用手动配置,是目前新手最省事的方案,没有之一。官方地址下载速度很慢,建议使用如下网址下载。查看ollama版本。
是一个开源的分布式大数据处理引擎,最初由加州大学伯克利分校。为核心特点,可用于大规模数据的处理、分析和机器学习等场景。软件基金会,如今已成为。
定期对数据仓库进行评估和优化,根据业务需求的变化和数据使用情况,调整数据仓库的架构、数据模型和数据处理流程,提高数据仓库的性能和可用性。管理数据仓库的元数据,包括数据定义、数据来源、数据转换规则、数据使用情况等。将转换后的数据加载到数据仓库的目标表中。致力于实现实体的统一,以商业要素资产化为核心,实现全域链接、标签萃取、立体画像,让数据融通而非以孤岛存在,为精准的用户画像提供基础。致力于实现数据的

【代码】数据库SQL Server时间函数Datetime。

vscode的安装不再赘述,可以看另一篇文章。vscode的安装并配置c语言环境安装vscode平台的插件MySQL和MySQL Syntax安装方式:点击扩展,直接查找下载即可vscode链接mysql下载插件成功后,vscode会出现mysql图标。点击并进入。点击右上角加号,之后会出现“connect”进入之后,点击“USER”一行的加号写一个小程序验证一下create database B
【代码】mysql设置允许其他IP访问。
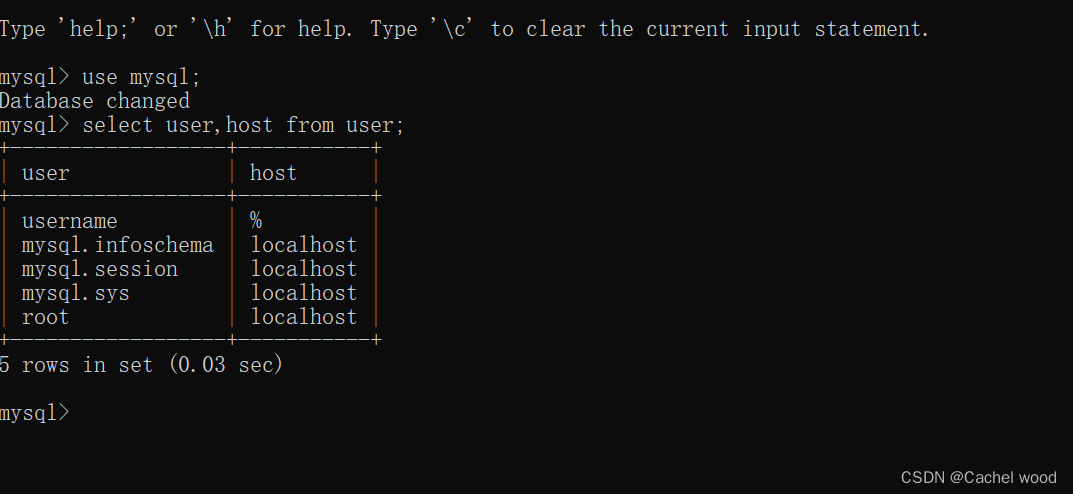
【代码】mysql设置允许其他IP访问。
1.请写出下列广义表的深度和长度。(1)A=()(2)B=(a)(3)C=(a,b,C)(4)D=(a,(A),(a,(b,(c,C))),d)(5)E=(a,(b,c),(d,(e),(f,(g))))(1)A = ()\\(2)B = ( a )\\(3)C = ( a, b, C)\\(4)D = ( a, (A), (a, (b, (c, C))), d )\\(5)E = ( a, (