




- @wangleigiser
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在实现最优compaction策略时,我们必须考虑多个因素。一种方法是回收重复记录占用的空间,减少空间开销,但这会产生由不断重写表导致的更高的写放大。替代方案是避免连续重写数据,而这又增加了读放大(在读取期间协调关联到相同键的数据记录的开销)和空间放大(因为冗余记录会被保存更长时间)。读放大:由为了检索数据而需要读取多个表所引起。写放大: 由compaction过程中不断进行的重写所引起。空间放大
4. 《Offer来了:Java面试核心知识点精讲(框架篇)(博文视点出品)》 https://item.jd.com/12868220.html。2. 《Offer来了:Java面试核心知识点精讲(第2版)(博文视点出品)》https://item.jd.com/13200939.html。示例命令表示扩容系统盘的第一个分区,/dev/vdb是数据盘,1是分区编号,/dev/vda和1之间需要空
我们的分区号设置为" (1-4, 默认1): 1",因此这里的名称为"/dev/vdb"+“1”= “/dev/vdb1”2. 《Offer来了:Java面试核心知识点精讲(第2版)(博文视点出品)》https://item.jd.com/13200939.html。4. 《Offer来了:Java面试核心知识点精讲(框架篇)(博文视点出品)》https://item.jd.com/1286822
Apache Doris2.0 基于Apache Doris向量化MPP引擎,增加了倒排索引和半结构化JSON数据支持,更好地满足日志存储、检索、分析需求。说明:建表语句中的 …是特殊语法,用于声明可以自动感知数据结构的变化。可以看下新增的log_type字段已经被自动识别。

想要更全面了解Spark内核和应用实战,可以购买我的新书。《图解Spark 大数据快速分析实战》(王磊)【摘要 书评 试读】- 京东图书1 什么是数据倾斜数据倾斜是指某些任务对应分区上的数据显著多于其他任务对应分区上的数据,从而导致这部分分区上数据的处理速度成为处理整个数据集的瓶颈。在Spark中,同一Stage内不同的任务可以并行执行,而不同Stage之间的任务可以串行执行。如图所示,假设一个S
在实现最优compaction策略时,我们必须考虑多个因素。一种方法是回收重复记录占用的空间,减少空间开销,但这会产生由不断重写表导致的更高的写放大。替代方案是避免连续重写数据,而这又增加了读放大(在读取期间协调关联到相同键的数据记录的开销)和空间放大(因为冗余记录会被保存更长时间)。读放大:由为了检索数据而需要读取多个表所引起。写放大: 由compaction过程中不断进行的重写所引起。空间放大
【代码】Java Stream Load写入数据到Doris。

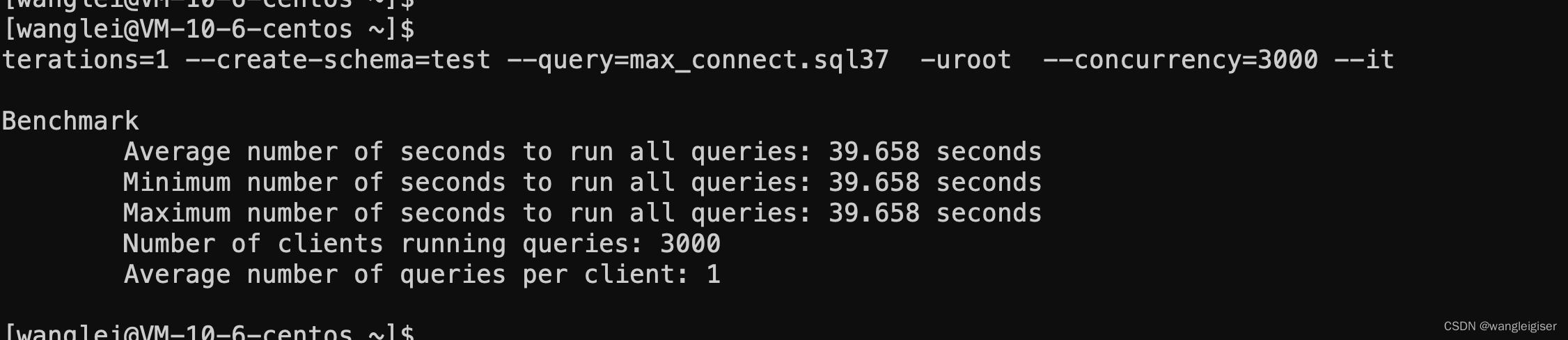
针对这种情况需要调整Doris最大连接数,具体做法如下。用户在使用Doris的时候,当访问用户过多时会报。
大数据时代的 10 个重大变化:从数据资源到数据资产;从基于知识到基于数据;从统计学到数据科学;从复杂算法到简单算法;从业务数据化到数据业务化;从目标驱动型到数据驱动型;从以战略为中心到以数据为中心;从不接受到接受数据的复杂性;从小众参与到大众协同...
Doris针对不同的应用场景提供了不同的数据模型,分别为:明细模型,主键模型和聚合模型。明细模型:明细数据存储(日志分析、行为分析)主键模型:相同key的数据覆盖更新(订单状态、用户状态)聚合模型:相同key列value列合并(报表统计、指标计算)