




- @sjxgghg
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
介绍了Python项目中确保正确导入模块的两种方法。首先推荐使用Path(__file__).resolve()获取脚本绝对路径并添加到sys.path,避免因目录切换导致的相对路径问题。其次针对VSCode中无法跳转源码的问题,提出在.vscode/settings.json中配置python.analysis.extraPaths来指定源码路径,这样既能保证代码运行正常,又能支持编辑器中的源码
本文分享了在Mac mini M4(16G内存)上部署大模型的经验。模型推理推荐使用Ollama,其底层基于llama.cpp但提供了更友好的API接口和模型管理功能,适合快速部署。vLLM暂不支持Mac的MPS加速。模型微调建议采用Unsloth框架,相比LLamaFactory具有内存占用小、微调快的优势。
将大规模专利数据存入MySQL数据库的实践。从使用Pandas读取专利数据开始,详细说明了如何将中文属性名映射为英文,并生成创建数据库表的SQL语句。

本文介绍了在Windows系统上配置WSL(Linux子系统)并安装Claude Code(CC)的过程。首先通过wsl --install命令安装WSL,并配置VSCode的WSL插件。然后尝试直接安装Linux版CC失败后,改为安装Windows桌面版CC,使其能在终端和VSCode中使用。接着通过修改WSL的.bashrc文件,实现在WSL中使用Windows版的CC,但发现VSCode插件
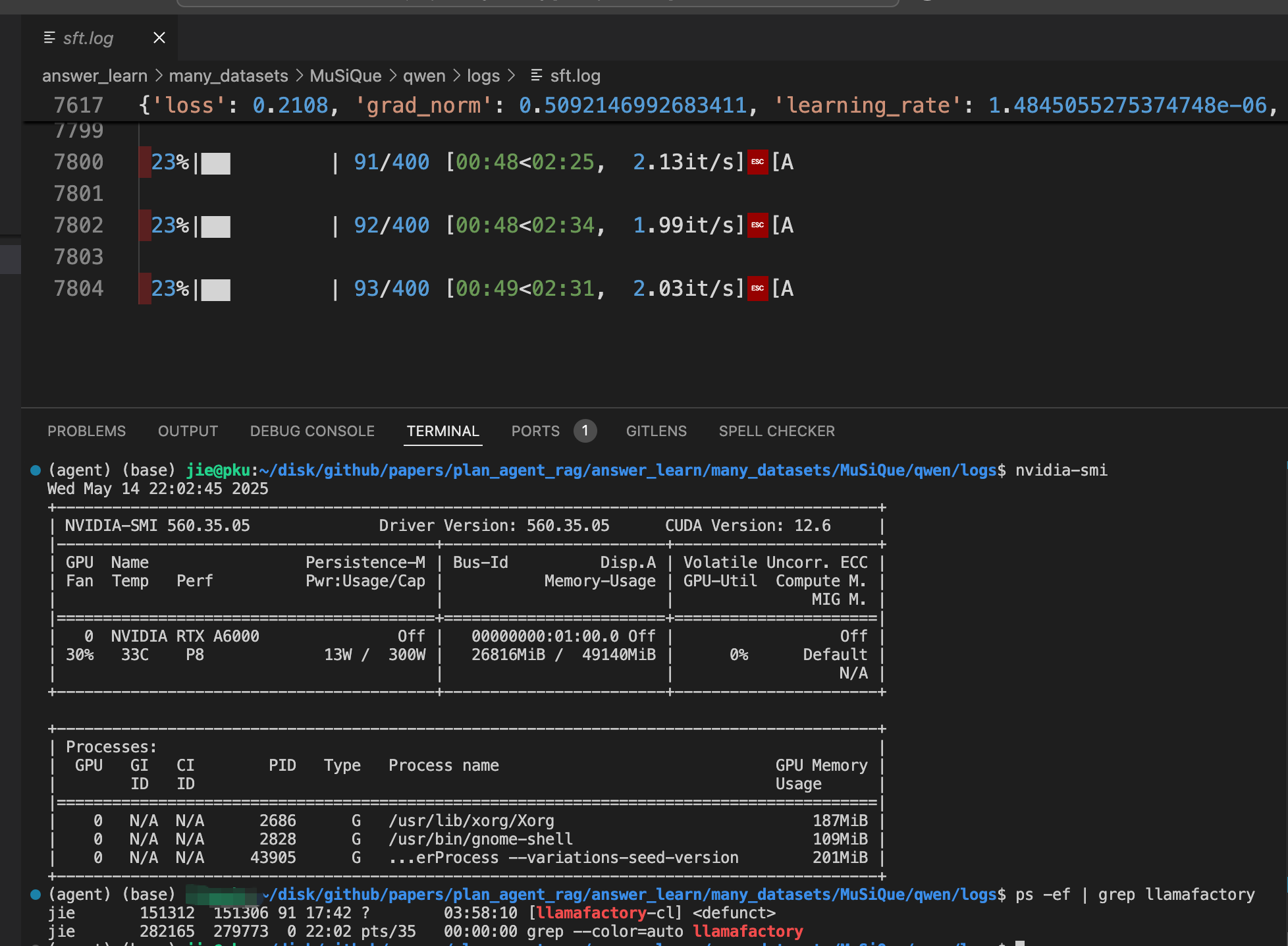
手动恢复训练可通过修改resume_from_checkpoint参数实现,但为减轻手动负担,编写了自动恢复训练的Shell脚本。
使用 Python 协程优化 DeepSeek API 调用的可行性。在本地通过 llamafactory + vLLM 部署 DeepSeek 后,异步调用的加速效果明显提升。

本文针对LLaMA-Factory的vllm推理脚本存在的两个痛点进行了优化:1)多数据集注册繁琐问题;2)切换数据集需重复加载模型问题。通过重构vllm_infer函数,将LLM对象作为参数传入而非内部创建,实现了模型单次加载多次使用的优化方案。代码实现包含两部分:1)vllm_infer.py负责处理数据集加载、批量推理和结果保存;2)主脚本完成模型初始化、参数设置并遍历数据集进行推理。该方案
本文详细介绍了使用sglang在本地部署Qwen3.5模型的全过程,包括环境准备、启动命令解析、Claude Code配置及常见问题解决方案。重点阐述了sglang的高效推理能力,提供了详细的参数配置说明,并分享了通过LiteLLM实现OpenAI格式转换的技巧。文章还记录了Docker部署方案和A3B-GPTQ-Int4模型部署失败的经验教训,最终推荐了Qwen3.5-9B作为稳定可用的本地部署
本文介绍了在Windows系统上配置WSL(Linux子系统)并安装Claude Code(CC)的过程。首先通过wsl --install命令安装WSL,并配置VSCode的WSL插件。然后尝试直接安装Linux版CC失败后,改为安装Windows桌面版CC,使其能在终端和VSCode中使用。接着通过修改WSL的.bashrc文件,实现在WSL中使用Windows版的CC,但发现VSCode插件
前一篇文章 [大模型预训练代码实战教程],介绍了大模型预训练的过程。有监督微调与预训练的代码流程基本一致,唯一的区别就是不对用户输入部分计算loss。本篇相比前一篇大模型预训练的文章,主要介绍如何把指令部分对应的label设置为-100。
