




- @shanguicsdn000
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
阅读是技术人员提升专业能力的有效方式之一,特别是对于从事网络安全行业的人员,广泛的知识储备会更有利于应对各种突发的安全事件。如果您对当下流行的热点技术或不断发展的新兴技术感兴趣,本文所推荐的8本书籍非常值得您阅读!这些书突破了传统思想的界限,深入研究了当前网络安全领域的新兴技术趋势,可以为网络安全人员的能力成长提供灵感和启示。作者:Bruce Schneier出版时间:2023年。

目前全球的经济形势非常艰难,很多人开始尝试从事第二职业或做副业赚钱,作为一名开发者,我们拥有一套独特的技能,这是非常棒的优势,如果你知道从哪里开始,赚钱将不会是一件很难的事,从现在开始,行动起来吧。

大家在工作中是不是经常要做各种分析,但又常常遇到无从下手,抓不住重点,搞不清关键数据的情况。俗话说“工欲善其事,必先利其器。”一个好用的数据分析模型,能给我们提供一种视角和思维框架,从而帮我们理清分析逻辑,提高分析准确性。那老李研究数据分析也很多年了,今天特意为大家整理出了8大常用数据分析模型,帮助大家快速提高数据分析能力。

在安装好MySQL数据库使用一段时间后,会产生许多的数据库和数据。那这些数据库的数据文件存放在本地文件夹的什么位置呢,下面这篇文章回来详细的回答这个问题,往下看看吧。一、默认位置一般来说MySQL数据库的数据文件都是存放在data文件夹之中,但是根据使用的存储引擎不同,产生的一些文件也略有差异。(1)如果使用InnoDB存储引擎的话,会产生.frm、ibdata1、.ibd这三个不同类型的数据文件

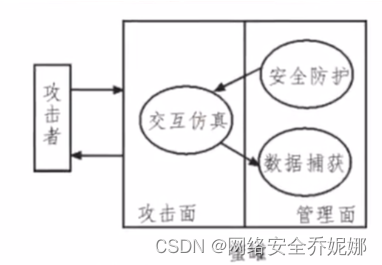
蜜罐是一种主动防御技术,通过主动的暴露一些漏洞、设置一些诱饵来引诱攻击者进行攻击,从而可以对攻击行为进行捕获和分析。是一款开源的基于 Golang 开发的跨平台多功能主动诱导型蜜罐平台,为了企业安全做出了精心的打造。
需要上述路线图对应的网络安全配套视频、源码以及更多网络安全相关书籍&面试题等内容可在文章后方领取。该部分主攻蓝队的防御,即更容易被大家理解的网络安全工程师。如果你对网络安全入门感兴趣,那么你需要的话可以点击这里。如果你对网络安全入门感兴趣,那么你需要的话可以点击这里。或者扫描下方csdn官方合作二维码获取哦!或者扫描下方csdn官方合作二维码获取哦!高亮显示 注释/PHP/ASP 区域。启动 No

在安装好MySQL数据库使用一段时间后,会产生许多的数据库和数据。那这些数据库的数据文件存放在本地文件夹的什么位置呢,下面这篇文章回来详细的回答这个问题,往下看看吧。一、默认位置一般来说MySQL数据库的数据文件都是存放在data文件夹之中,但是根据使用的存储引擎不同,产生的一些文件也略有差异。(1)如果使用InnoDB存储引擎的话,会产生.frm、ibdata1、.ibd这三个不同类型的数据文件
linux系统中一切皆文件/bin是binary的缩写,这个目录存放着最经常使用的命令,通过上方桌面可以看到bin文件夹有个箭头,是链接到 /usr/bin下,相当于快捷方式,进入/bin和/usr/bin下是一模一样的/sbins就是super User的意思,这里存放的是系统管理员使用的系统管理程序。/home存放普通用户的主目录,在Linux中每个用户都有一个自己的目录,一版该目录名是以用户

(1) Fine-Tuning(标准微调)优点:简单易用:直接在预训练模型上进行微调。适应性强:可以针对特定任务调整整个模型的参数。效果显著:通常能显著提高模型在特定任务上的表现。缺点:计算成本高:需要调整模型的大量参数。数据需求较高:为了有效微调,通常需要较多的标注数据。适用场景:当有足够的标注数据和计算资源时,适用于大多数NLP任务。优点:参数高效:只修改或优化模型的一小部分参数。节省计算资源

ollama不仅支持运行预构建的模型,还提供了灵活的工具来导入和自定义您自己的模型。无论是从GGUF格式导入还是进行模型的个性化设置,ollama都能满足您的需求。您还可以通过自定义提示来调整模型的行为。接着,创建一个Modelfile# 设置创造性更高的温度参数# 设置系统消息SYSTEM """你是超级马里奥,以马里奥的身份回答问题。"""这样,您就能按照自己的需求定制模型了。ollama提供
