- @qq_38853759
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
笔者上一篇博文详细介绍了tingsboard的快速部署,本次教程让整个页面动起来,快速完成一个完整动态页面的开源物联网平台智慧农业的案例,手把手每一步都有图示,附带模拟数据的shell脚本,方便没有硬件的读者也可以迅速完成实践。

本周调研了三个开源物联网平台,RT-Thread、ThingsBoard、Kaa,并大致从技术栈、使用等方面做了对比,并对其做了个人总结,欢迎物联网界大佬提出更宝贵的意见,在此表示感谢

目标是仅使用视觉输入就能导航并到达用户指定目标的机器人,对于此类问题的解决办法一般有两种。基于地图的导航算法或者SLAM系统与最先进的物体检测或图像识别模型的局限性深度卷积神经网络(cnn)与强化学习(RL)相结合的方法优势 深度强化学习(DRL)确实允许以自然的方式管理视觉和运动之间的关系,并且它在无地图视觉导航和许多其他机器人任务中显示出令人印象深刻的结果。局限 在目标驱动的视觉导航中

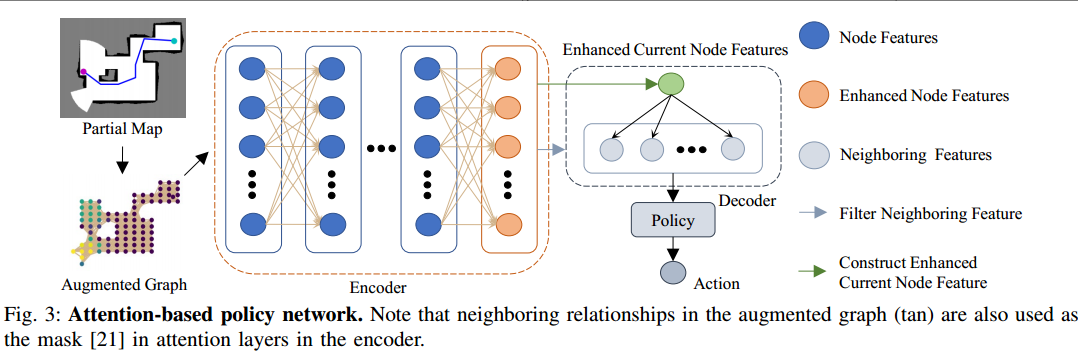
基于深度强化学习(DRL)的ARE方法,在注意力机制的加持下,允许智能体在不同的空间尺度上推理局部地图中不同区域的依赖关系,从而允许智能体在不需要优化长路径的情况下有效地对空间非近视决策进行排序。首先将自主探索表述为覆盖已知可穿越区域的无碰撞图上的顺序决策问题,其中一个节点是机器人的当前位置。然后,使用基于注意力的神经网络选择机器人当前位置的一个相邻节点作为机器人的下一个视点。
强化学习是以奖励作为目标的机器学习方法,其思路仿照生物的经验学习方法,其没有标签数据,所以奖励是非常重要的指标,强化学习方向的最终目标是将总奖励最大化,奖励的建模设计引导整个强化学习的走向。其基础概念包含策略、动作、状态、价值函数等,配有迷宫实例进行结合讲述。

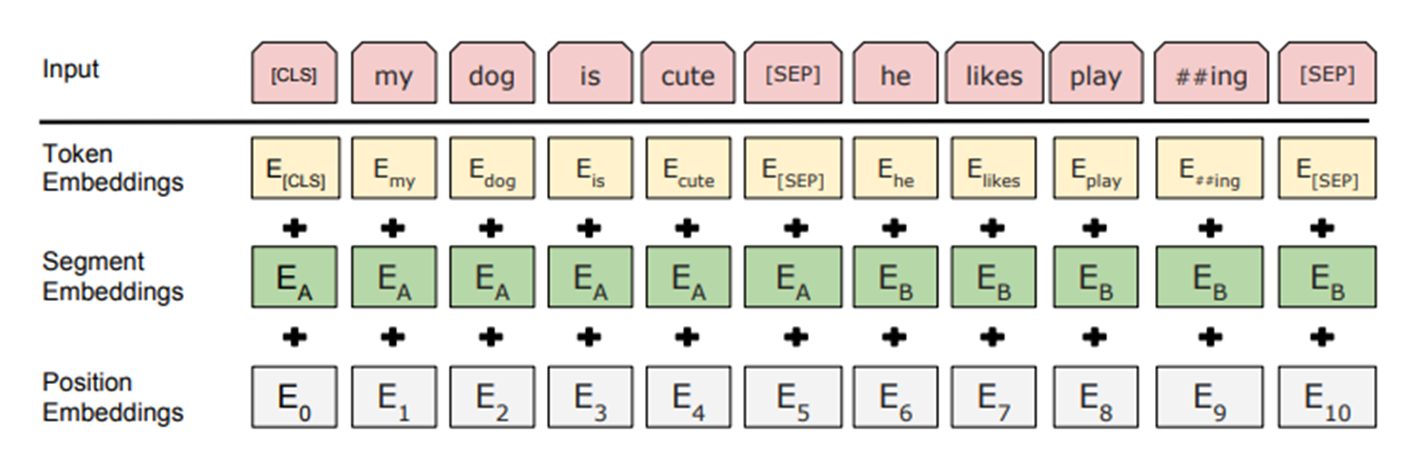
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练模型,它是自然语言处理(NLP)领域的重大里程碑,被认为是当前的State-of-the-Art模型之一。BERT的设计理念和结构基于Transformer模型,通过无监督学习方式进行训练,并且能够适配各种NLP任务。预训练模型是指在大规模文本数据上进行大量无监督训
MobileNet是一个轻量级的卷积神经网络,可以在算力有限、内存有限的情况下保证比较优秀的识别效果,MobileNet可以为嵌入式设备深度学习提供有效的保障,本文摒弃了传统的概念介绍和论文分析,采用举例解释和代码工程同步展示的方式撰写,代码工程采用keras,通过测试可以运行。
HomeRobot:开放词汇移动操作 (OVMM) 挑战赛的目标是创建一个平台,使研究人员能够开发能够导航陌生环境、操作新颖对象以及从封闭对象类别转向开放词汇自然语言的代理。该挑战赛旨在利用机器学习、计算机视觉、自然语言和机器人技术的最新进展,促进具体人工智能的跨领域研究。本文复现了habitat具身智能挑战赛的实验,希望可以帮到相关研究人员。

目标是仅使用视觉输入就能导航并到达用户指定目标的机器人,对于此类问题的解决办法一般有两种。基于地图的导航算法或者SLAM系统与最先进的物体检测或图像识别模型的局限性深度卷积神经网络(cnn)与强化学习(RL)相结合的方法优势 深度强化学习(DRL)确实允许以自然的方式管理视觉和运动之间的关系,并且它在无地图视觉导航和许多其他机器人任务中显示出令人印象深刻的结果。局限 在目标驱动的视觉导航中
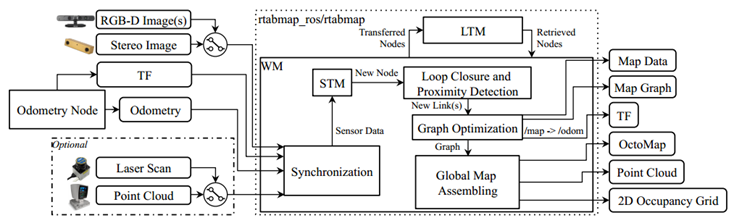
RGB-D的视觉传感器数据输入SM内存块,本内存块对传感器的观测数据进行数据降维、特征提取、位姿计算后,加入STM内存块,在STM内存块添加时序相邻的节点若相似度较高,则对两个节点进行权重更新的融合计算,当STM区满后,挑选最早加入STM的节点移出,并加入到WM进行后续的闭环检测搜索节点储备,WM中的闭环检测涉及词袋模型和贝叶斯滤波,视觉词袋用于计算两个节点之间的相似度,贝叶斯滤波器维护节点之间的