




- @qq407155634
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这些以“节点(Vertex)”和“边(Edge)”为核心的非结构化数据,正成为挖掘复杂关系的关键。Spark GraphX作为分布式图计算的“瑞士军刀”,凭借其与Spark生态的深度集成(支持从数据加载、图处理到机器学习的全流程),已成为处理大规模图数据的首选工具。GraphX是Spark专为图计算设计的分布式框架,其核心设计哲学是“将图数据与集合数据统一抽象”,既支持传统图操作(如邻接遍历、子图

Apache Flink的架构设计通过“分层解耦+模块化”的思想,实现了高可靠、高吞吐、低延迟的实时计算能力。其运行流程的关键在于“将用户逻辑转换为分布式任务,并通过资源管理与任务调度高效执行”。云原生支持:深度集成K8s,实现更细粒度的资源弹性(如基于指标自动扩缩容);AI与流计算融合:通过内置的机器学习推理能力(如Flink ML),在流处理过程中实时执行模型预测;统一批流处理:Flink 1

spring boot2项目升级到spring boot3 jdk8升级到17

AI方向的专用名词特别多,很容易混在一起,文本梳理下从机器学习到AI大模型发展历程和专业名词。下面按照概念的层次关系依次梳理。
Broker端则会针对每个\维护一个序列号(SN),只有当对应的SequenceNumber = SN+1时,Broker才会接收消息,同时将SN更新为SN+1。通过预分配ID就容易避免,客户端每次提交订单都需要携带一个提前获取的订单id,当服务端检查有重复的订单id时,就可以拒绝。如果改为提前分配好ID, 客户端将ID与数据一同发送给服务端,服务端进行ID验证,检查这个ID是否已经处理过了。这个
spring boot2项目升级到spring boot3 jdk8升级到17
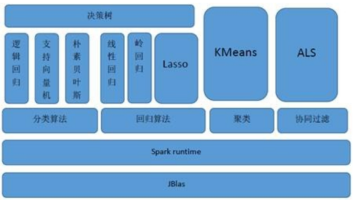
通过这个模型可以对输入对象的特征向量预测或对对象的类标进行分类。2、从通信的角度讲,如果使用 Hadoop 的 MapReduce 计算框架,由于是通过heartbeat 的方式来进行的通信和传递数据,会导致非常慢的执行速度,而 Spark 具有出色而高效的 Akka 和 Netty 通信系统,通信效率极高。线性回归是利用称为线性回归方程的函数对一个或多个自变量和因变量之间关系进行建模的一种回归分
AI方向的专用名词特别多,很容易混在一起,文本梳理下从机器学习到AI大模型发展历程和专业名词。下面按照概念的层次关系依次梳理。
1991年,Bill Inmon在《Building the Data Warehouse》中首次明确定义了数据仓库:"面向主题的、集成的、非易失的且随时间变化的数据集合,用于支持管理决策"。概念的诞生源于企业对数据价值的深度挖掘需求。在1980年代,随着OLTP(联机事务处理)系统在企业中的普及,传统关系型数据库在处理海量数据分析时显露出明显瓶颈:事务处理与分析查询的冲突、数据孤岛现象严重、历史
SQL Agent的作用就是将自然语言,转成sql语句,然后执行得到结果,又叫NL2SQL。其中主要的问题是大模型不知道数据库结构,但企业的数据库信息又不能暴露出去。就需要将企业数据库信息以提示词的形式发送给大模型。其中会有个最大的问题: 这个问题涉及哪些表,这些表的关系是什么,如何让大模型理解一些特定的统计术语?
