- @m0_63437643
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
因此,分布式缓存作为分布式架构的重要组件,当一个缓存服务节点挂掉,可以马上切换到另外的缓存服务节点,以保证系统能正常运行。希望大家通过这个笔记,既有在技术上的精进和能力上的增长,也能在面试中更加从容地应对,真正通过这些学习和准备得到实实在在的回报和收获,多拿offer,涨薪翻倍!而在缓存中间件中,Redis以兼具缓存和数据库的优点,适用范围更广,很多人更愿意使用,memcache也只能望其项背。添

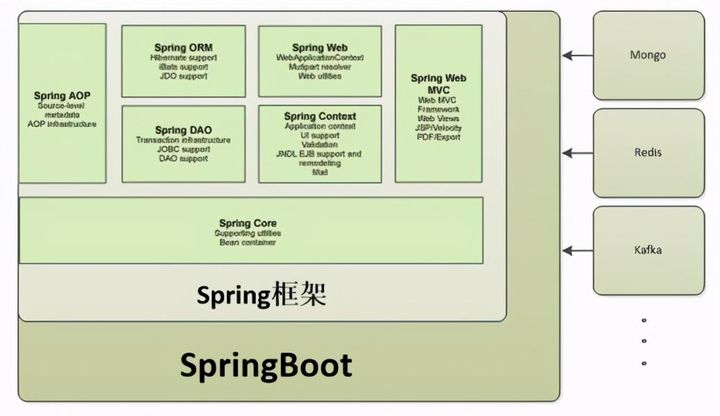
(3)赠送配套源代码,方便操作上手,助力你地spring学习,快来使用Spring和Spring Boot搭建属于自己的应用!今天给大家带来的是:[美] 克雷格·沃斯(Craig Walls) 著,张卫滨,吴国浩 译的 《Spring实战(第6版)》,也是最新的一版,本书是关于Spring核心特性的指南,延续了前几个版本一贯的清晰风格,带领你亲自动手,逐步构建出一个以数据库作为支撑的Web应用。第

缓存一般用来保存一些进程被存取的对象或数据,通过缓存来存取对象或数据要比在磁盘上存取快很多,前者是内存,后者是磁盘、Memcached是一种纯内存缓存系统,把经常存取的对象或数据缓存在memcached的内存中,这些被缓存的数据被程序通过API的方式被读取,memcached里面的数据就像一张巨大的hash表,数据以key-value对的方式存在。Memcached通过缓存经常被存取的对象或数据,

前言互联网世界中,网络协议的重要性不言而喻。很多人都知道,网络协议中的五层模型或者七层模型,这些在操作系统中,那都是“必考题”。上学的时候,无论是死记硬背,还是各种小抄,总得把下面这个图记下来。踏入工作,走进 web 开发“不归路”,发现还是不能落下它。计算机网络相关的知识点是在面试过程中开发者经常被问到。当然可能这一块知识点与前面的操作系统、数据库相比较比重可能没那么高。但是优秀的你,一定是想做
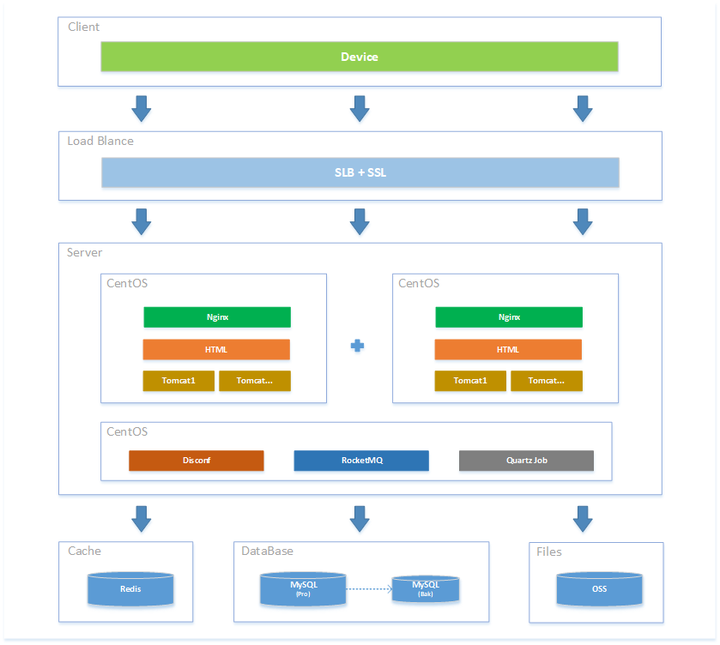
负载均衡主要工作是分发请求到源服务器,另一个作用也是为了保护源服务器,不暴露服务器真实IP,大幅度降低服务器被DDoS攻击的风险,可参考《被人DDoS攻击了,分析一下原理和防护》 一文。有资源的公司,动不动就能获得千万级甚至更高级别的融资,业务方向众多,若还只是用高可用架构,所有的业务模块都臃肿在一个项目里,不论是代码管理还是人员管理上,都是巨大的资源消耗。创业公司刚起步,资金可能也就百来万,搞微
缓存一般用来保存一些进程被存取的对象或数据,通过缓存来存取对象或数据要比在磁盘上存取快很多,前者是内存,后者是磁盘、Memcached是一种纯内存缓存系统,把经常存取的对象或数据缓存在memcached的内存中,这些被缓存的数据被程序通过API的方式被读取,memcached里面的数据就像一张巨大的hash表,数据以key-value对的方式存在。Memcached通过缓存经常被存取的对象或数据,
本章将对SpringBoot配置文件中的数据加密做自定义开发. 在SpringBoot开发过程中配置文件是明文存放在application.yml或者application.properties文件中,这种配置方式会带来一定的安全隐患,本章将对这个问题提出一个简单的解决方案。上述代码为基本的加密解密工具,加下来需要在配置文件中确定哪些配置是需要进行解密的,本例将采用自定义前缀+后缀的方式进行匹配,
辛辛苦苦三个月,每天都遨游在知识的海洋当中,不知不觉已经把云原生Kubernetes给搞透了,并且拿到了阿里架构高级岗!那我就不藏着掖着了,直接把这个PDF分享出来给大家共同钻研!说实话,是真的有点佩服自己的毅力和吸收能力,人要是狠起来自己都害怕!看完来此评论,看谁更强!微信公众号获取联系方式。

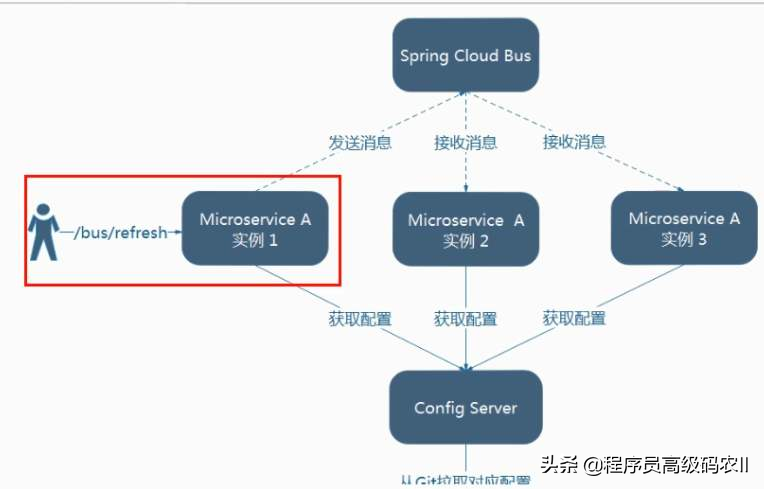
如何集成 BuSSpring Cloud Bus致力于提供分布式消息总线的功能。目前,Spring Cloud Bus支持使用AMQP协议(如Kafka、Rabbit等)消息代理作为通道。本节将演示如何集成Spring Cloud Bus。初始化应用首先在micro-weather-config-client、micro-weather-config-server应用的基础上,重新创建一个新的应用
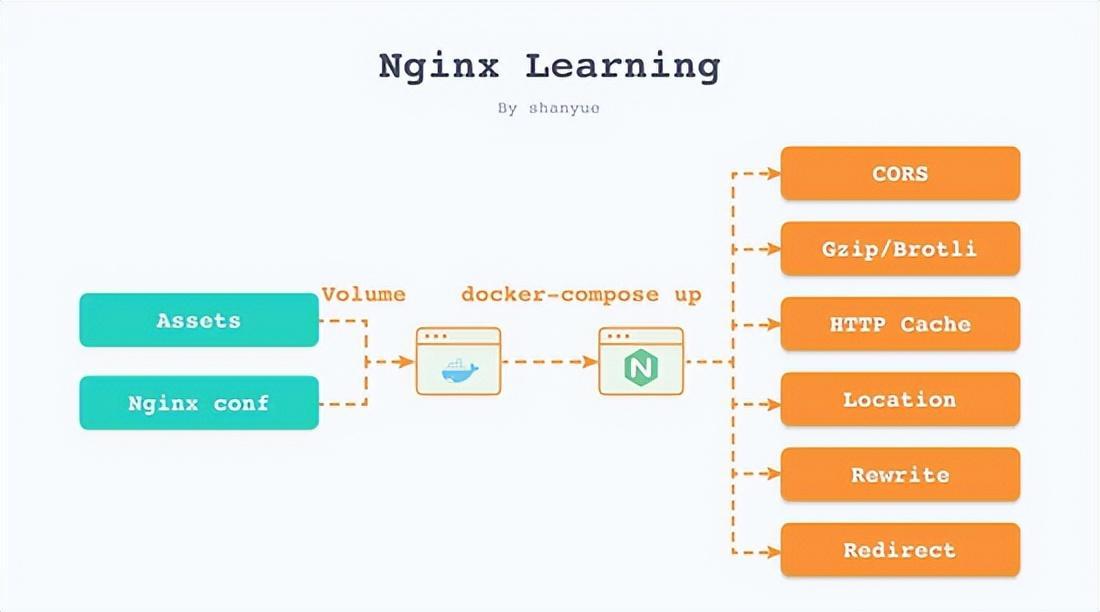
# http://localhost:8120/test1 ok # http://localhost:8120/test1/ ok # http://localhost:8120/test18 ok # http://localhost:8120/test28 not ok location /test1 { # 可通过查看响应头来判断是否成功返回 add_header X-Config B;