




- @m0_63181360
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
相邻矩阵(了解就行,不用太关注)两者区别——基于用户与基于物品。协同过滤(基于用户)协同过滤(基于物品)

回归分析定义:案例:线性回归预备知识:定义:一元线性回归:如何找出最佳的一元线性回归模型:案例:python实现:多元线性回归案例:线性回归的优缺点:逻辑回归(解决分类问题)案例:定义:python实现:案例:逻辑回归优点:逻辑回归缺点:(解决分类问题)

今天在虚拟机上安装了mongo,但是使用DG进行连接的时候报错:java.rmi.ConnectException: Connection refused to host: 127.0.0.1。这个问题很奇怪,DG测试连接可以通过,但是确认配置进行连接后显示正常,数据库可以被查询一部分,但是写操作被禁止,执行写操作就报错没有连接上。忘记截图了,就看看文字吧。

Apache Spark 是一个开源的分布式计算系统,专为快速计算而设计。它建立在 Hadoop MapReduce 之上,扩展了 MapReduce 模型以有效地使用更多类型的计算,包括批处理、交互式查询、流处理和机器学习。Spark 提供了多种编程语言的 API,如 Scala、Java、Python 和 R,以及用于数据处理的高级抽象,如 RDD(弹性分布式数据集)、DataFrame 和

今天在虚拟机上安装了mongo,但是使用DG进行连接的时候报错:java.rmi.ConnectException: Connection refused to host: 127.0.0.1。这个问题很奇怪,DG测试连接可以通过,但是确认配置进行连接后显示正常,数据库可以被查询一部分,但是写操作被禁止,执行写操作就报错没有连接上。忘记截图了,就看看文字吧。
回归分析定义:案例:线性回归预备知识:定义:一元线性回归:如何找出最佳的一元线性回归模型:案例:python实现:多元线性回归案例:线性回归的优缺点:逻辑回归(解决分类问题)案例:定义:python实现:案例:逻辑回归优点:逻辑回归缺点:(解决分类问题)
概述图中延伸的分支的宽度对应数据流量的大小,通常应用于能源、材料成分、金融等数据的可视化分析。桑基图最明显的特征就是,始末端的分支宽度总和相等,即所有主支宽度的总和应与所有分出去的分支宽度的总和相等,保持能量的平衡。:桑基图可以显示不同节点之间的流量量级,通过箭头的宽度来表示。:桑基图可以使用颜色来编码不同的节点或流动路径,以帮助用户更好地理解和区分不同的实体或类别。选择合适的布局方式,使得节点和
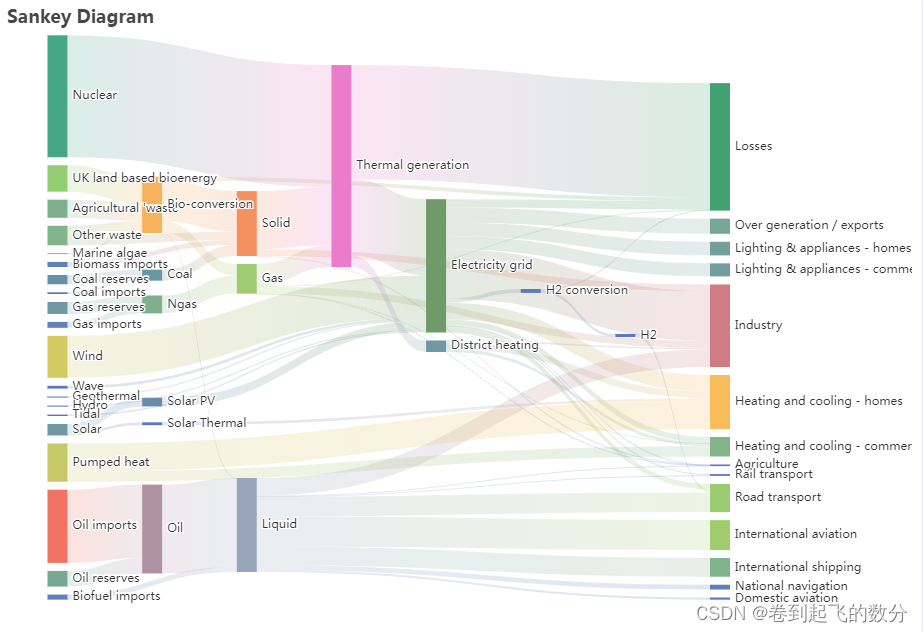
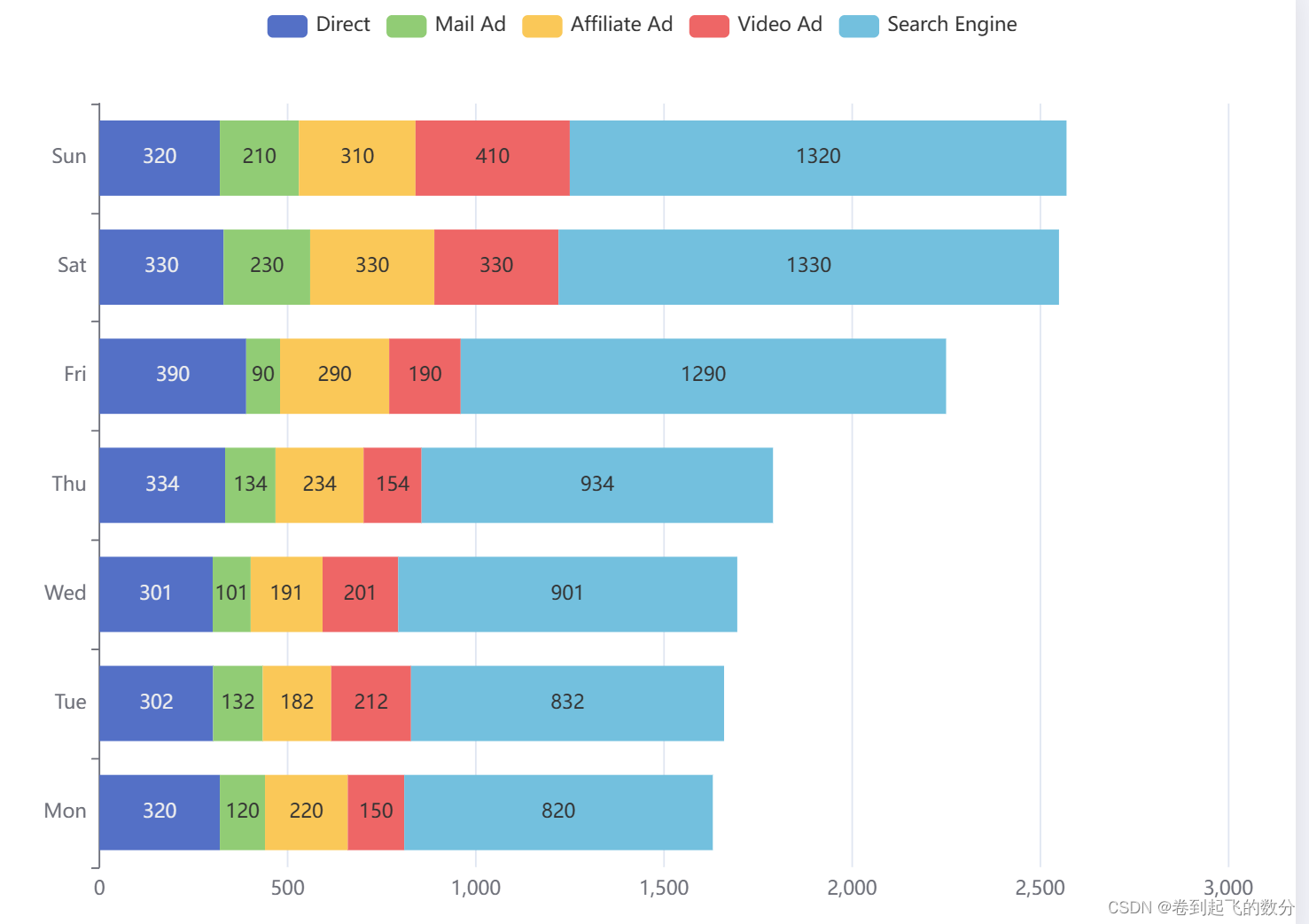
下面定义了五种数据,分别定义了五个不太的名字来设定,再分别在各个数据下设定stack(名称为total)更改为三列,即设置三个不同的stack名称(total,total11,total22)即在series中将设置stack即可。其他设置与普通柱状图相同,语法:相同名称的数据会堆叠起来,不同则会新生成一列。数据堆叠,同个类目轴上系列配置相同的。相同(相同的堆叠,不同的新生成一列)stack名称相
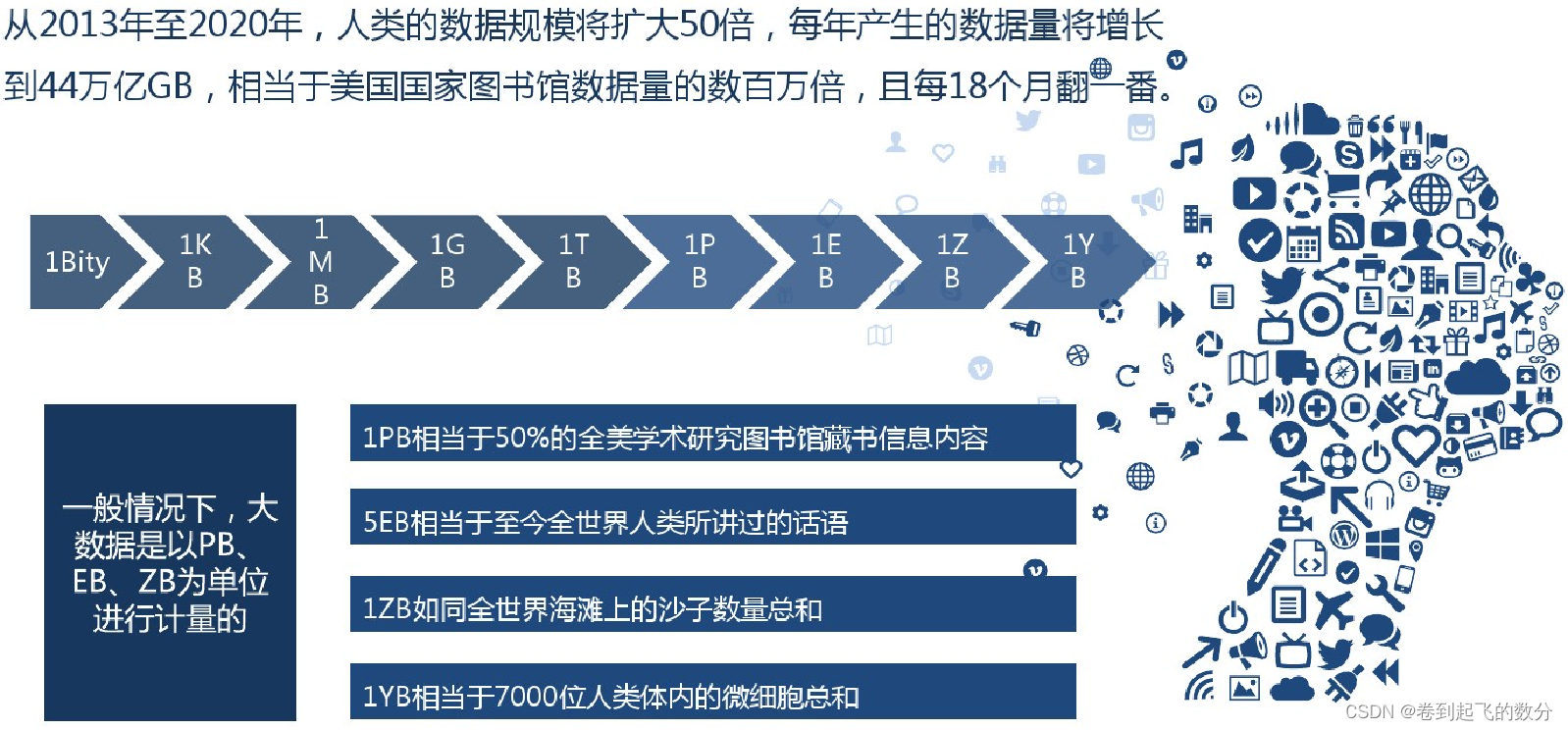
数据挖掘是从数据中,发现其有用的信息,从而帮助我们做出决策(广义角度)。数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识,寻找其规律的技术,结合统计学、机器学习和人工智能技术的综合的过程(技术角度)
1.回归2.分类。机器学习算法最普通分类:分类算法的定义:分类算法的应用:分类器实现分类:分类器的构建标准:概率模型:贝叶斯公式:朴素贝叶斯算法(朴素贝叶斯分类器):案例:注意:python实现:KNN算法空间向量模型:KNN的定义:案例:
