




- @csdncjh
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
分布式锁看门狗防止死锁redission实现依赖<!--整合redission框架start--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>&...
某台服务器的es的8300,8200端口需要指定白名单访问,需要在不影响服务器上其他服务的前提下(因为是历史项目),完善防火墙配置。首先梳理发现,这两个端口是docker映射出来的端口,开启防火墙。发现防火墙无法限制端口。

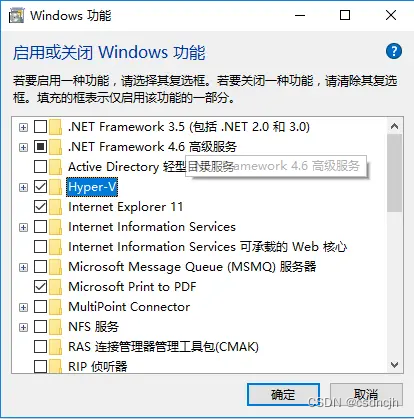
Win10 下是否开启硬件虚拟化技术,在控制面板,启用 window 功能,找到 Hyper-V 选项,点勾选确认。
需求:由于一些公共组件例如redis,elasticsearch会有漏洞扫出,用户需要安全加固,使用升级组件方式加固,需要大量时间,并且所有客户端都需要更新,代价太大。因此统一针对组件的端口设置ip白名单,减少维护成本。cenos6和centos7的配置方式略有不同,因此分别总结。......
MyBatis-Plus是MyBatis的增强工具,提供CRUD、条件构造器、性能分析等特性,简化开发。在MybatisPlus的基础上增加更多的模板功能,站在巨人的肩膀上。MybatisPlusPro是一个 MybatisPlus的增强工具,在 MybatisPlus的基础上只做增强不做改变,为简化开发、提高效率而生。

一直想优雅地再JavaEE程序中方便地使用集成在spring上的工具,以前的方法是用如下的方式硬编码。private staticApplicationContext applicationContext;static {String path2 = AppUtils.class.getResource("/applicationContext.xml").toString();String pa

yum 主要功能是更方便的添加/删除/更新RPM 包,自动解决包的倚赖性问题,便于管理大量系统的更新问题。 yum 可以同时配置多个资源库(Repository),简洁的配置文件(/etc/yum.conf),自动解决增加或删除rpm 包时遇到的依赖性问题,保持与RPM 数据库的一致性。yum 的配置文件分为两部分:main 和repositorymain 部分定义了全局配置选项,整个yum 配
注意:因为现在最新版的mongodb不兼容win7,对windows系统的最低要求是win10。所以win7系统要安装mongodb数据库必须考虑使用旧版安装。

ClickHouse是俄罗斯最大的搜素引擎Yandex于2016年开源的列式数据库管理系统,使用C++ 语言编写, 主要应用于OLAP场景。使用理由在大数据量的情况下,能以很低的延迟返回查询结果。笔者注: 在单机亿级数据量的场景下可以达到毫秒级的查询性能,单机能处理百亿的数据量, 聚合、计数、求和等统计操作的性能是MySQL的100倍。

ES的安装下载地址:https://www.elastic.co/downloads/past-releases/elasticsearch-2-4-3»启动»cd......./elasticsearch-2-4-3»bin/elasticsearch»bin/elasticsearch-d(后台运行)ES安装验证:http://your ip...
