




- @bullnfresh
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
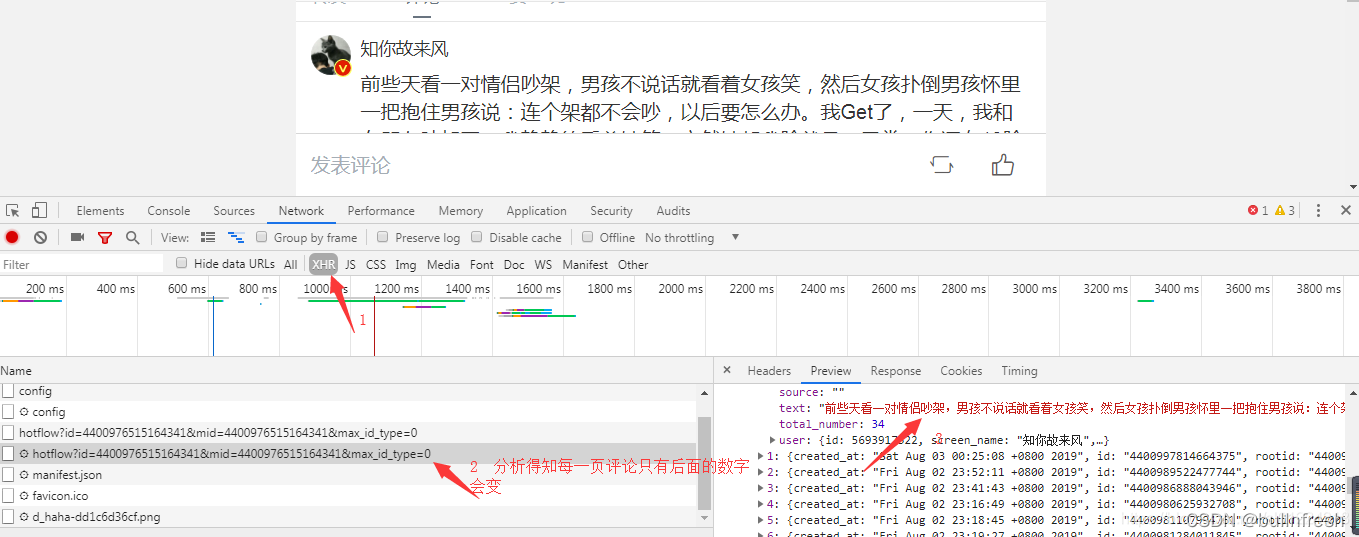
一、非结构化文本的爬取微博上有一篇关于“#学校里的男生有多温柔#”的话题,点进去一看感觉评论很真实,于是想把评论给爬下来看一看,并生成词云。刚开始思路是通过网页端微博爬取,通过开发者工具查看分析后,发现并没有看到相关评论。百度搜索之后得知web做了一些反爬虫策略,不太容易爬取(踩了相当时间的坑)。但是微博手机端相对容易些,于是转战手机端获取该评论链接,然后使用谷歌浏览器登录该链接,一阵分析后,发现
新闻数据有20个主题,有10万多篇文章,每篇文章对应不同的主题,要求是任意输入一篇新的文章,模型输出这篇文章属于哪个主题。一、 算法原理1. 朴素贝叶斯方法朴素贝叶斯方法涉及一些概率论知识,我们先来复习一下。联合概率:包含多个条件,并且所有的条件同时成立的概率,公式为:P(AB)=P(A)*P(B)条件概率:事件A在另一个事件B已经发生的前提下发生的概率,记作P(A|B),如果有多个条件,那记作:
在NLP中,用来判断一句话是否符合正确的语法,广泛应用于信息检索、等重要任务中。),虽然可解释性强、易于理解,但存在泛化能力差等问题。随着深度学习技术的发展,相关技术也应用到语言模型中,如神经网络语言模型(Neural Network Language Model模型)。
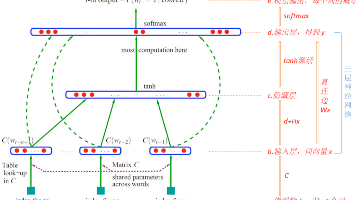
在NLP中,用来判断一句话是否符合正确的语法,广泛应用于信息检索、等重要任务中。),虽然可解释性强、易于理解,但存在泛化能力差等问题。随着深度学习技术的发展,相关技术也应用到语言模型中,如神经网络语言模型(Neural Network Language Model模型)。
新闻数据有20个主题,有10万多篇文章,每篇文章对应不同的主题,要求是任意输入一篇新的文章,模型输出这篇文章属于哪个主题。一、 算法原理1. 朴素贝叶斯方法朴素贝叶斯方法涉及一些概率论知识,我们先来复习一下。联合概率:包含多个条件,并且所有的条件同时成立的概率,公式为:P(AB)=P(A)*P(B)条件概率:事件A在另一个事件B已经发生的前提下发生的概率,记作P(A|B),如果有多个条件,那记作:
Bert模型是谷歌2018年10月底公布的,反响巨大,效果不错,在各大比赛上面出类拔萃,它的提出主要是针对word2vec等模型的不足,在之前的预训练模型(包括word2vec,ELMo等)都会生成词向量,这种类别的预训练模型属于domain transfer。而近一两年提出的ULMFiT,GPT,BERT等都属于模型迁移,说白了BERT 模型是将预训练模型和下游任务模型结合在一起的,核心目的就是
市面上语音识别技术原理已经有很多很多了,然而很多程序员兄弟们想研究的时候却看的头大,一堆的什么转mfcc,然后获取音素啥的,对于非专业音频研究者或非科班出生的程序员来说,完全跟天书一样。最近在研究相关的实现,并且学习了keras和tensorflow等。用keras做了几个项目之后,开始着手研究语音识别的功能,在网上下载了一下语音的训练文件,语料和代码已上传到了:链接: https://pan.b
