




- @a910247
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
人工智能的研究和应用涵盖了多个方面,如机器人、语言识别、图像识别、自然语言处理、专家系统、机器学习等。其目标是让计算机和机器能够执行各种高级功能,如查看、理解和翻译口语和书面语言,分析数据,提出建议,甚至进行推理、学习和行动等通常需要人类智力或超出人类分析能力的数据规模的任务。作为牵引互联网、大数据、云计算、区块链等技术加速创新的集成性技术,人工智能正融入经济社会发展的各领域全过程,推动数字经济迅

支持向量机(Support Vector Machine,SVM)是由等人于1990年提出的一种监督学习算法。它的核心思想是通过在特征空间中找到一个最优的超平面来进行分类,使得两个类别的样本之间的间隔最大化。SVM 在分类、回归分析、异常检测等领域都有着广泛的应用。SVM 在高维空间中可以非常高效地进行分类,适用于数据维度较高的情况,如文本分类、图像分类等。SVM 的目标是最大化分类边界的间隔,因

最后,再通过**urllib.request.urlretrieve()**的方法来下载我们所需内容,并在我们安装Python路劲的文件中,只需打开文件夹即可查看哦。然后定义我们要访问的地址,模拟浏览器发送请求,获取返回内容,...

哈希算法常用于存储用户密码。而不是直接存储密码本身,系统通常会将密码哈希后存储。当用户登录时,系统会对用户提供的密码进行哈希,并将其与存储的哈希值进行比较,而不是明文密码。常用的密码哈希算法包括SHA-256和bcrypt。数字签名使用哈希算法来确保数据的完整性和认证。发送方使用私钥对消息进行哈希,并将哈希值与私钥一起签名。接收方使用发送方的公钥验证签名,并通过哈希比较确保消息的完整性。哈希算法用

它的核心思想是通过训练模型来识别数据中的模式和规律,然后利用这些模型进行预测和决策。3. 训练:训练模型是指使用已知数据来调整模型的参数,使其能够更好地适应数据中的模式和规律。5. 预测和决策:训练好的模型可以用于进行预测和决策,根据输入数据生成输出结果。总的来说,机器学习通过让计算机系统从数据中学习,使其能够自动发现数据中的模式和规律,并利用这些知识进行预测和决策,从而实现各种人工智能应用。这些

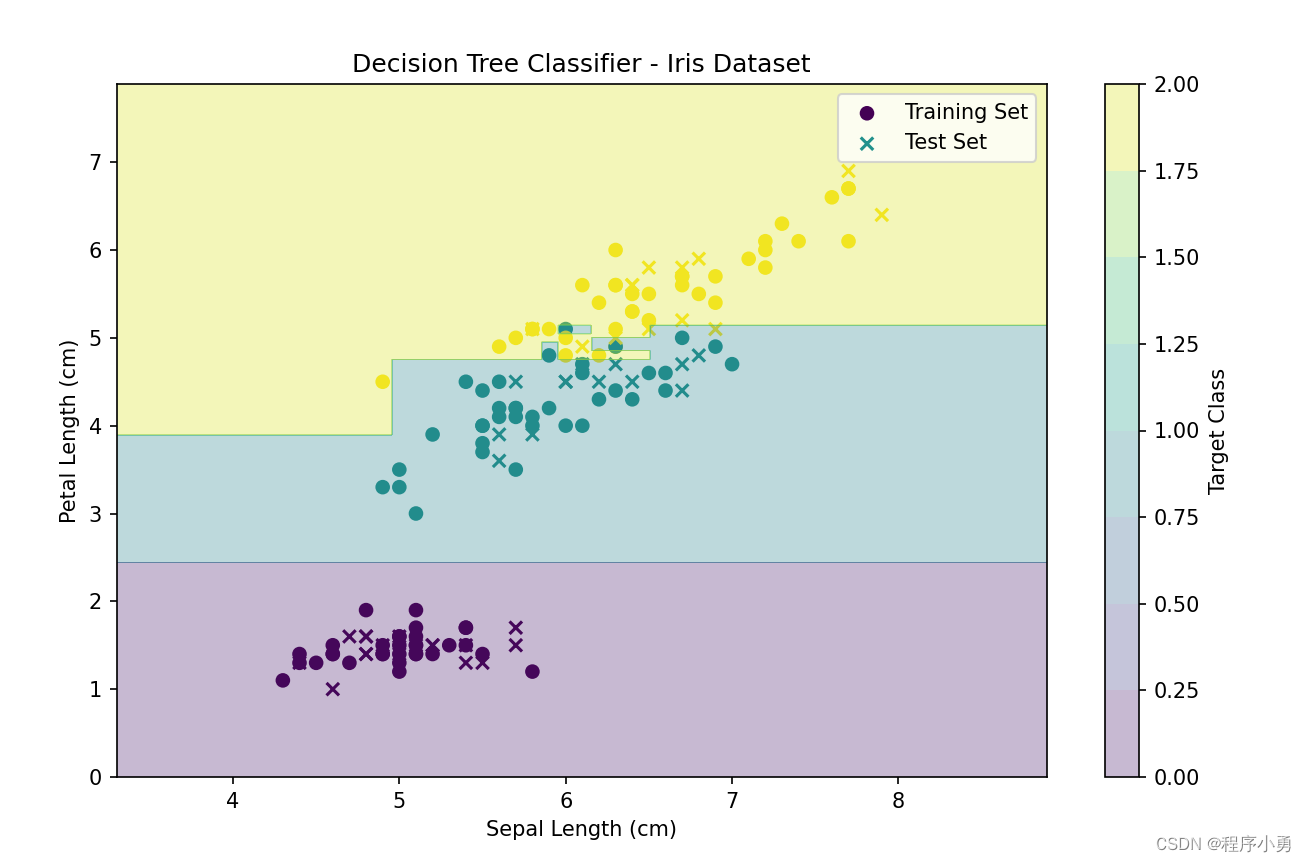
决策树是一种经典的机器学习算法,用于解决分类和回归问题。它的基本思想是通过对数据集中的特征进行递归划分,构建一系列的决策规则,从而生成一个树状结构。在决策树中,每个内部节点表示对输入特征的一个测试,每个分支代表一个测试结果,而每个叶子节点表示一个类别或输出值。决策树的发展历史可以追溯到20世纪50年代和60年代。最早的决策树算法是ID3(Iterative Dichotomiser 3),由Ros
在预训练阶段,LLM模型通过无监督学习从大规模的文本数据中学习语言的统计特征和语义信息。LLM模型是一种用于自然语言处理的语言模型,它是基于预训练的深度学习模型。LLM代表"Language Learning Model",它的目标是通过大规模的文本数据来学习语言的表示和语义理解。在应用阶段,LLM模型可以用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。LLM模型的优点是能够学习到

论后端未来发展及学习路线。 在未来,后端技术开发将继续受到技术和市场需求的变化和挑战。未来后端技术开发的趋势和方向。应该逐步学习掌握后端开发技术,以下我将详细介绍学习路线以及学习资料推荐:

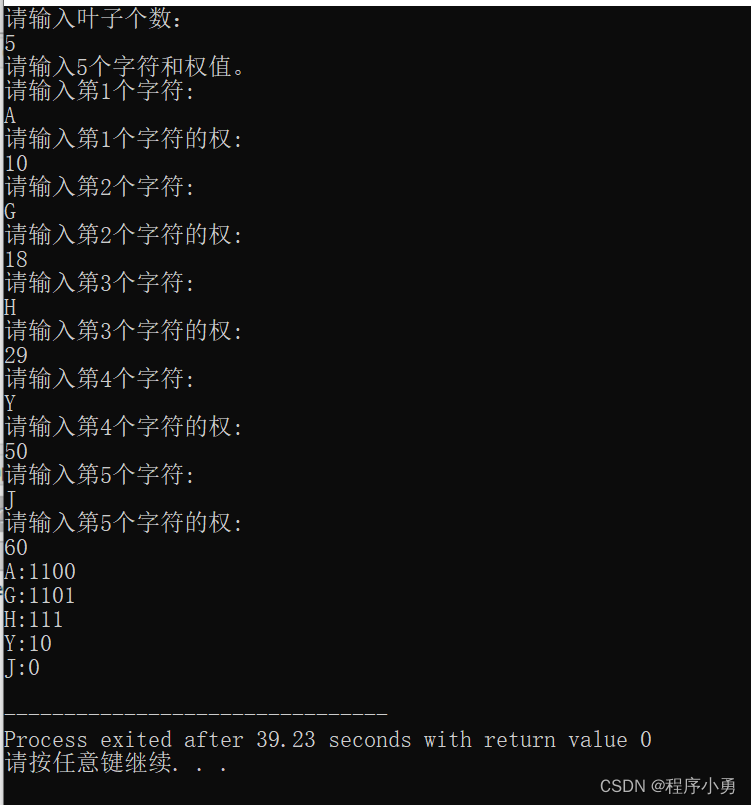
哈夫曼编码是一种可变字长编码(Variable Length Coding)的一种方法,通过根据不同字符出现的频率来构建一颗具有最小编码长度的二叉树。该树的构建和遍历规则使得出现频率高的字符获得较短的编码,而出现频率低的字符获得较长的编码,从而达到对数据进行高效压缩的目的。
Android 是一个由 Google 开发的移动操作系统,它主要用于智能手机和平板电脑。Android 是目前全球使用最广泛的移动操作系统,因其开放性、灵活性和可定制性而受到用户和开发者的喜爱。
