




- @Yaoyao2024
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
测试时训练(Test-Time Training),这是一种通用的方法,用于提高预测模型在训练数据和测试数据来自不同分布时的性能。将单个未标记的测试样本转化为一个自监督学习问题,在做出预测之前更新模型参数。这种方法也自然地扩展到在线流数据 (online stream) 。方法在各种旨在评估对分布偏移鲁棒性的图像分类基准上取得了改进。
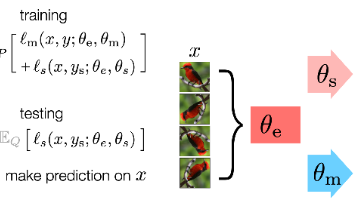
在解决大部分深度学习和机器学习问题时,解决思路通常来源于:判别模型和生成模型。也就是说,这两种模型的方法,给许多实际问题提供了基础的概念框架和思考方向。基于这两种模型的特征、方法、应用场景的不同,其实也可以很容易将其区分开来:比如上图右侧,将一个图片样本(内容为猫或者狗)区分开来,这就是判别模型所需要做的。
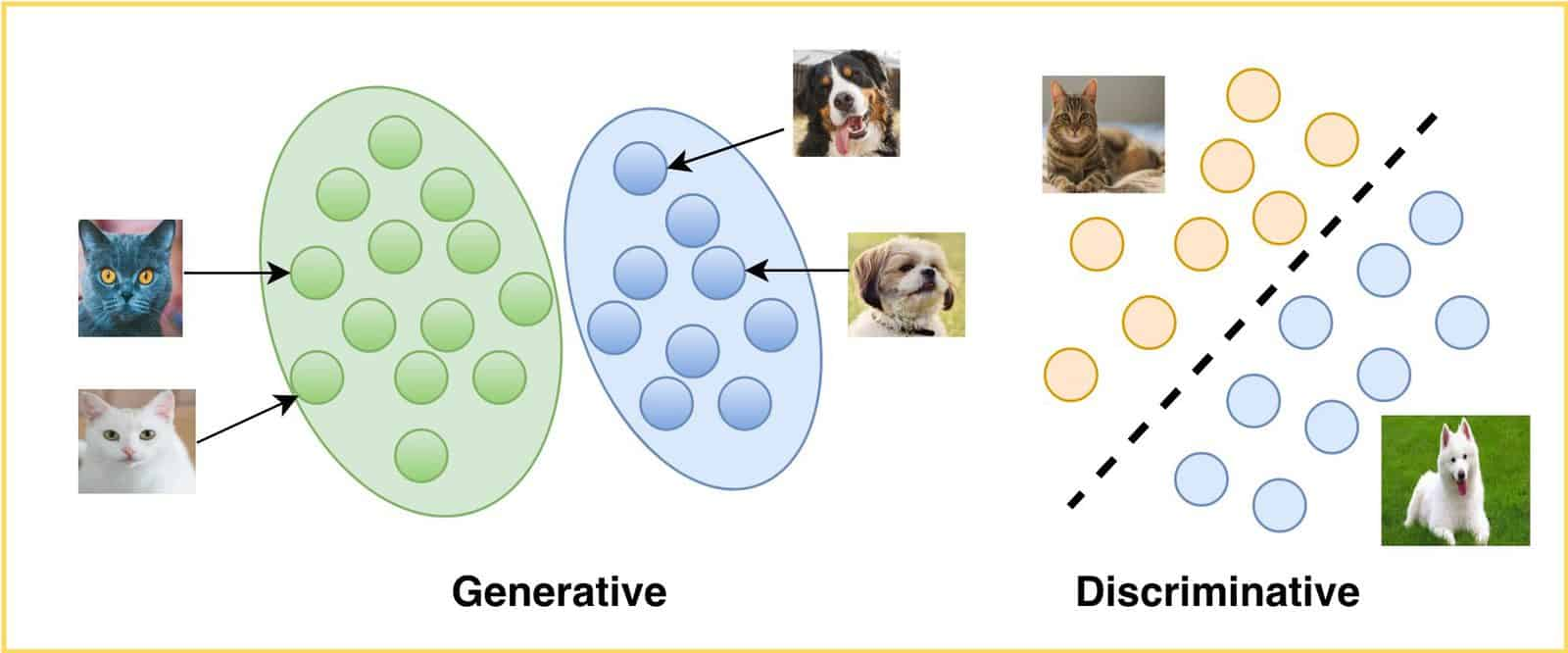
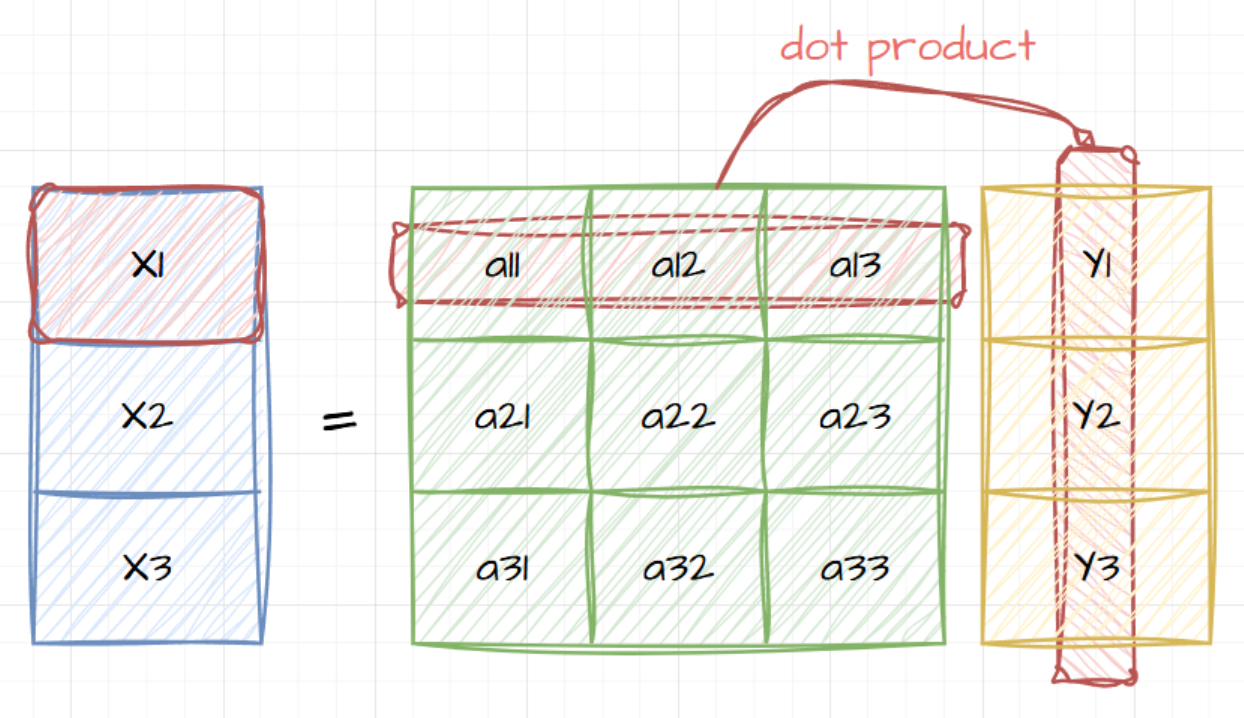
点积内积外积哈达玛积(Hadamard Product矩阵乘法这篇博客,我将结合这三种操作在深度学习中的运用,来讲解一下这三种操作的区别。对比总结表运算数学符号代码实现(PyTorch)输入要求输出规则矩阵乘法ABABA @ B或前列=后行行列点积求和点积(内积)u⋅vu⋅v同维向量标量外积u⊗vu⊗v任意两向量矩阵(( \mathbf{u} \mathbf{v}^T ))哈达玛积A∘BA∘BA
组合优化是运筹学中的核心领域,专注于在离散对象的有限集合中寻找“最佳”组合方式。这类问题普遍存在于现实世界,从物流路径规划到金融资产配置,再到算法设计,其核心挑战是如何在“组合爆炸”的庞杂解空间中高效锁定最优解。
yolov8 opencv模型部署(C++ 版)win10下 yolov8 tensorrt模型部署✨使用opencv推理yolov8模型,仅依赖opencv,无需其他库,以yolov8s为例子,注意:使用opencv4.8.1!使用opencv4.8.1!使用opencv4.8.1!如果你使用别的版本,例如opencv4.5,可能会出现错误至于怎么安装yolov8、训练模型、导出onnx博客中都

在之前的学习中,我自以为我对张量、矩阵、数组,已经十分清楚。就在近期我打算再好好学习一下张量各个操作的过程极其原理的时候,才发现之前的自己或许根本没有弄清楚张量到底是个啥?为什么呢?我发现我学习的过程中发现对张量的各个操作有种说不上来的不明白。我问了自己很久,到底是哪一点让自己感受到这种“不舒适”的学习感?我向来是一个喜欢追根溯源,刨根问底的人。于是我问我自己这个问题区分这两个概念:[x,y,z]
爱因斯坦求和约定(Einstein Summation,简称einsum)是一种简洁且功能强大的符号表示法,用于指定复杂的张量运算。在深度学习领域,特别是在 PyTorch 库中,提供了一种灵活的方式来执行各种张量操作,例如矩阵乘法、点积、批量计算、外积、规约(reduction)、重塑(reshaping)或转置(transposing)等等。在上篇文章中我们介绍了张量关于”积“的各种操作【深度
最近在训练模型的时候遇到一个问题,当输入相同的时候,每次经过模型得到的结果并不完全一致。比如使用Early-Stopping,总训练轮数并不完全一致。这是因为现在的深度学习框架有一定的随机性(具体原因暂时还没了解,因为我这里其实load是预训练权重,但是仍然存在随机性在模型训练过程中,随机性可能来自多个方面,如数据的随机打乱、模型初始化、随机优化算法中的随机性等。随机性会导致每次训练结果不一致,不
最近好不容易用服务器把模型跑起来了,美滋滋地看他一轮一轮训练,感觉应该没啥问题,想着一个晚上训练完肯定没问题!结果第二条早上来一看:main()这不是说我显存不够了吗!使用nvidia-smi命令查看服务器显卡使用情况:没错,我用的就是0号显卡,难道是实验室师兄师姐在训练模型?不应该呀!这个显存占用量和我模型训练的显存占用量极为相似,何况师兄师姐他们训练模型之前肯定会查看显卡的使用情况的!

部署yolo项目,是我这几个月以来做的事情,最近打算把这几个月试过的方法,踩过的坑,以博客的形式,分享一下。关于下面动态中讲到的如何用opencv部署,我在上一篇博客中已经详细讲到了:【yolov8部署实战】VS2019环境下使用C++和OpenCV环境部署yolo项目|含详细注释源码。这篇博客主要讲讲使用onnxruntime部署主要参考:https://github.com/Amyheart/