




- @SiArch
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在深度学习领域,TensorFlow 和 PyTorch 是目前最主流的两种框架,分别由 Google 和 Facebook(现 Meta)开发。对于初学者而言,选择哪个框架作为入门往往令人困惑。本文将从多个维度对比这两种框架,并提供可执行的代码示例,帮助读者更好地理解和选择。
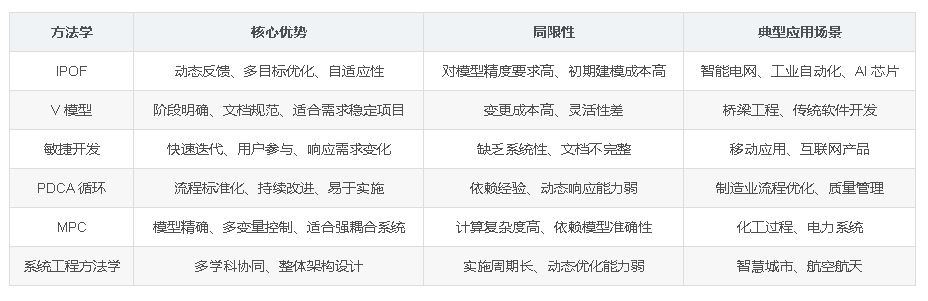
在复杂多变的现代系统工程与工业领域,IPOF(Input-Process-Output-Feedback)方法学凭借其闭环反馈机制,展现出独特优势,广泛应用于各类动态优化场景。本文将深入探讨 IPOF 方法学的理论基础、实际应用案例,并与其他典型方法学进行比较分析。
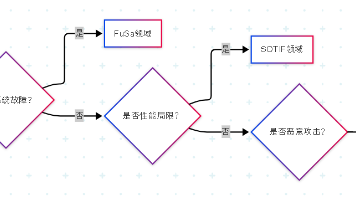
智能汽车三重安全技术解析 随着汽车电子化程度提升,现代智能汽车面临功能安全(FuSa)、预期功能安全(SOTIF)和网络安全三大核心挑战。本文深入剖析了这三重防护体系: 功能安全(FuSa):通过ISO 26262标准预防电子系统随机故障,采用ASIL等级评估风险,典型案例包括双核锁步架构的ESP系统。 预期功能安全(SOTIF):解决系统无故障但性能不足的问题,依赖场景仿真和AI训练,如特斯拉的
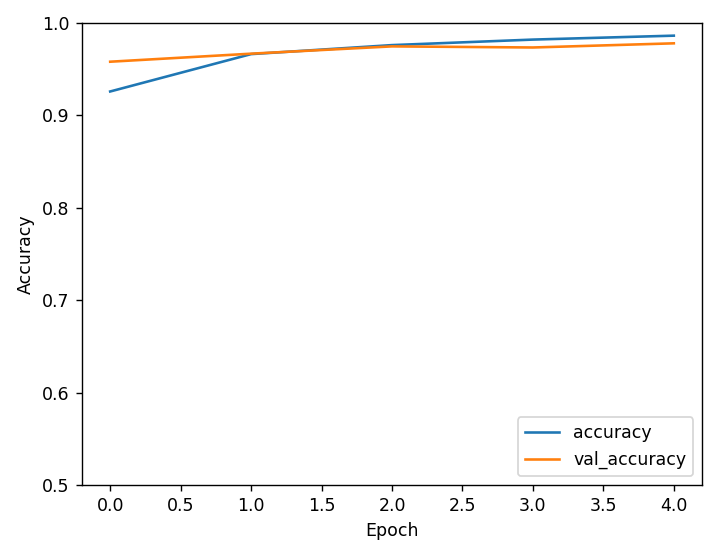
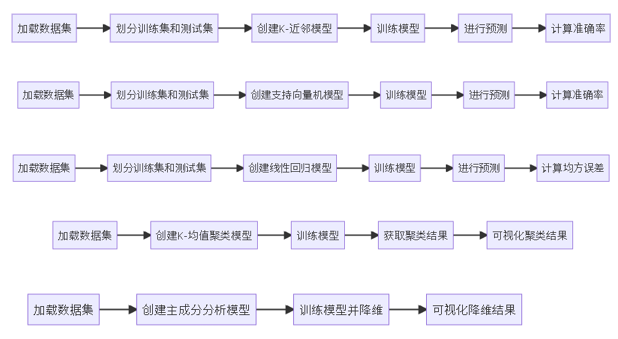
继上一篇, 我们接下来介绍人工智能常用的机器学习库。在数据分析和预测建模领域,Scikit-learn 是一个功能强大且易于使用的 Python 机器学习库。本文将通过几个示例,介绍如何使用 Scikit-learn 进行监督学习(分类和回归)以及无监督学习(聚类和降维)。
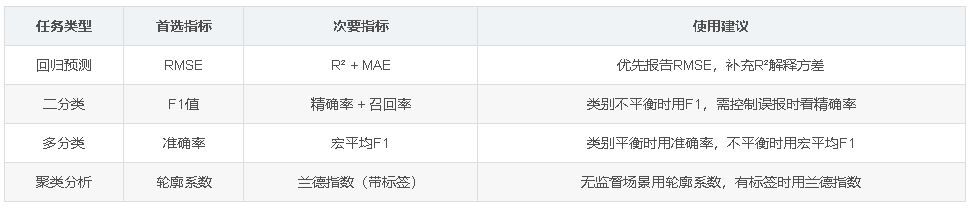
机器学习任务中,不同任务类型(如回归、分类、聚类)使用不同的评估指标来衡量模型性能。在回归任务中,常用指标包括平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R²)。MAE对异常值不敏感,RMSE放大大误差,R²反映模型拟合程度。分类任务中,常用指标有准确率、精确率、召回率和F1值,分别关注整体正确率、预测正类的准确性、正类样本的覆盖率以及精确率与召回率的平衡。聚类任务中,轮廓系数和兰德
自动驾驶系统是数学工具链的集大成者。从传感器数据的多维空间映射到控制指令的生成,每一步都隐藏着线性代数、微积分、概率论和优化理论的精妙配合。本文将构建一个数学模型完整的自动驾驶案例,结合Python代码实现。

机器学习任务中,不同任务类型(如回归、分类、聚类)使用不同的评估指标来衡量模型性能。在回归任务中,常用指标包括平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R²)。MAE对异常值不敏感,RMSE放大大误差,R²反映模型拟合程度。分类任务中,常用指标有准确率、精确率、召回率和F1值,分别关注整体正确率、预测正类的准确性、正类样本的覆盖率以及精确率与召回率的平衡。聚类任务中,轮廓系数和兰德
继上一篇, 我们接下来介绍人工智能常用的机器学习库。在数据分析和预测建模领域,Scikit-learn 是一个功能强大且易于使用的 Python 机器学习库。本文将通过几个示例,介绍如何使用 Scikit-learn 进行监督学习(分类和回归)以及无监督学习(聚类和降维)。
IPO是基础的线性处理模型,适用于简单、静态的任务。IPOF通过反馈机制形成闭环,使系统具备自适应能力,适用于需要动态调整、持续优化的复杂场景(如控制系统、机器学习、智能交互等)。反馈环节是IPOF的核心创新,它连接了输出与输入,让系统能够根据实际结果优化行为,是现代智能系统设计的重要方法学。

在复杂多变的现代系统工程与工业领域,IPOF(Input-Process-Output-Feedback)方法学凭借其闭环反馈机制,展现出独特优势,广泛应用于各类动态优化场景。本文将深入探讨 IPOF 方法学的理论基础、实际应用案例,并与其他典型方法学进行比较分析。