




- @DrLai
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
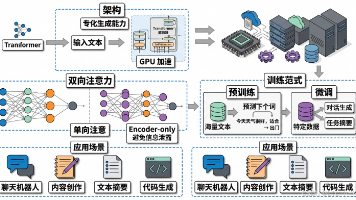
本文介绍了Decoder-only架构及其在GPT系列模型中的应用。这种架构专注于自回归文本生成,通过单向注意力机制预测序列中的下一个词,模拟人类写作过程。文章对比了Decoder-only与Encoder-only架构的特点,分析了GPT的训练方式(自回归语言建模+微调)及其在聊天机器人、内容创作等场景的应用。同时指出了该架构的优势(强大的生成能力)与挑战(可能产生幻觉),并探讨了GPT系列演进
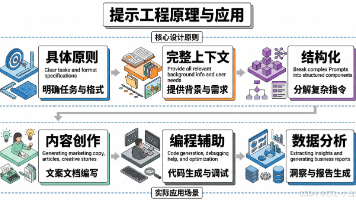
Prompt工程(Prompt Engineering)是一种**通过精心设计和优化输入提示词(Prompt)来引导大语言模型产生高质量输出的技术**。它就像是与AI对话的艺术——你问得越清楚、越具体,AI回答得就越准确、越有用。
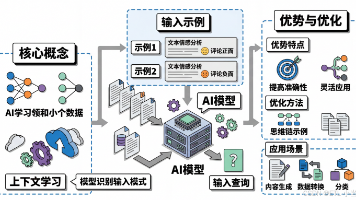
思维链(Chain-of-Thought, CoT)是一种**引导大语言模型通过中间推理步骤来解决问题**的提示技术。它要求AI不仅给出最终答案,还要展示完整的思考过程,就像人类解题时会写出详细的步骤一样。
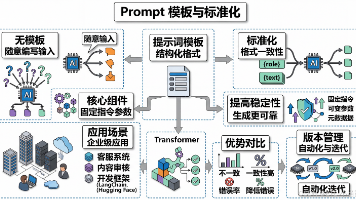
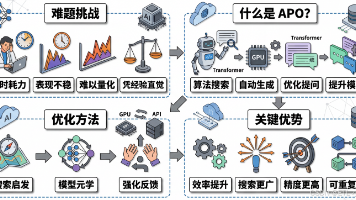
本文介绍了Prompt模板的概念、核心组件及应用价值。Prompt模板是一种预定义的提示词结构化格式,通过固定指令和可变参数确保AI处理任务的一致性。相比随意编写的Prompt,模板化方法能显著提高稳定性(一致性提升11%)、降低错误率(7%降幅)并提升开发效率(3倍)。文章详细解析了模板的三大核心组件(固定指令、可变参数、元数据)和常见模式,列举了企业客服、内容审核等典型应用场景。同时指出模板化
想象你是一位厨师,想要找到最完美的蛋糕配方。传统方法是凭经验不断尝试不同的配料比例,这既耗时又可能错过最佳组合。现在假设你有一台智能烤箱,它能够自动测试成千上万种配方组合,通过数据分析快速找到最优解——这正是自动Prompt优化在AI领域的作用。
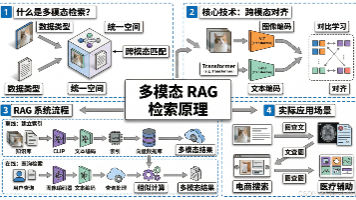
想象这样一个场景:你打开电商App,看到一件很眼熟的衣服,但不知道叫什么名字。你拍了张照片上传,系统不仅找出了相似的商品图片,还告诉你这件衣服叫"oversized针织开衫",材质是"羊绒混纺",适合"秋冬季节穿搭"。
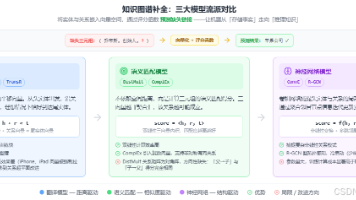
本文系统介绍了知识图谱补全(KGC)技术,主要内容包括: 问题定义:KGC旨在预测知识图谱中缺失的三元组关系,解决传统图谱实体语义理解不足的问题。 核心方法: 基于翻译的模型(如TransE):将关系视为实体间的向量平移 基于语义匹配的模型(如DistMult):通过相似度计算评估关系 基于神经网络的模型(如ConvE):利用神经网络捕捉复杂模式 应用价值:可提升电商商品属性补全、医疗辅助诊断、搜
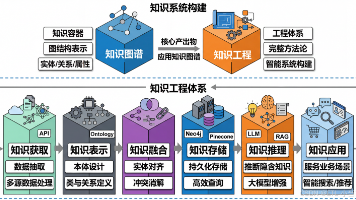
本文系统介绍了知识工程与知识图谱的区别及构建完整知识体系的方法。知识图谱作为知识的"容器",专注于图结构存储;而知识工程是一套方法论,涵盖知识获取、表示、融合、存储、推理和应用全流程。文章通过电商案例,详细阐述了知识工程的六大环节:从多源数据抽取知识,设计本体模型,解决数据冲突,选择存储方案,进行知识推理,到最终业务应用。最后对比了两者的优劣势,并展望了结合大模型的发展趋势。知
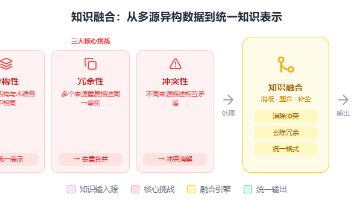
知识融合是将多个异构知识源的信息进行统一整合,消除冲突并补充缺失,形成一致完整的知识表示。其核心流程包括模式对齐(统一术语和结构)、实体对齐(识别相同实体)、冲突消解(解决信息矛盾)和知识补全(整合互补信息)。关键技术涵盖字符串相似度计算、属性匹配、结构分析和深度学习嵌入等。虽然能提升信息完整性和准确性,但面临技术复杂度高、计算量大、数据质量依赖源等挑战。适用于需要整合多源数据的智能系统,如搜索引
AI Agent(智能体)是一种能够自主感知环境、制定计划并采取行动的人工智能系统,与传统AI工具不同,它能主动拆解任务、调用工具并持续优化。AI Agent具备感知、规划、工具使用和记忆反思等核心能力,不同于单轮反应的聊天AI,它能进行多轮自主思考。典型应用包括个人效率、软件开发、企业服务和创意生产等领域。技术架构上采用ReAct模式(思考与行动交替)或多Agent协作方式,通过协调者分配任务给
