
OpenClaw 的 JSON 之殇:格式一错,Agent 全线崩溃
本文探讨了OpenClaw系统中结构化JSON输出的关键作用和优化方法。主要内容包括: JSON解析的重要性:OpenClaw的Skill调度完全依赖LLM输出的结构化JSON,格式错误会导致整个任务链中断。 关键应用场景:任务路由、Skill间数据传递和Heartbeat任务执行都依赖稳定的JSON格式。 输出不稳定原因:LLM本质是文字接龙,容易出现多余文字、格式错误等问题。 优化方案: 设计
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
聊聊OpenClaw可能在哪里依赖结构化JSON?
一、JSON解析失败的致命后果
OpenClaw的Skill调度依赖LLM输出结构化JSON——格式出错,任务直接中断。
说人话就是: 想象你在指挥一个交响乐团,每个乐手都需要按照精确的乐谱演奏。如果你给小提琴手的指令是"拉点好听的",而不是具体的音符和节奏,整个乐团就会混乱。在OpenClaw中,LLM就是那个需要给出精确"乐谱"(JSON)的指挥家,一旦格式出错,整个执行链就会崩溃。
这和普通问答完全不同:问答格式出错你重问一遍就好,但在Agent的执行链里,一个解析失败会让整条流程卡死。
稳定输出JSON的核心是三件事同时做对:Prompt里给明格式要求 + 具体示例 + 强约束语言,然后在解析层做好兜底——因为LLM不是数据库,它永远有一定概率给你格式略有偏差的输出。
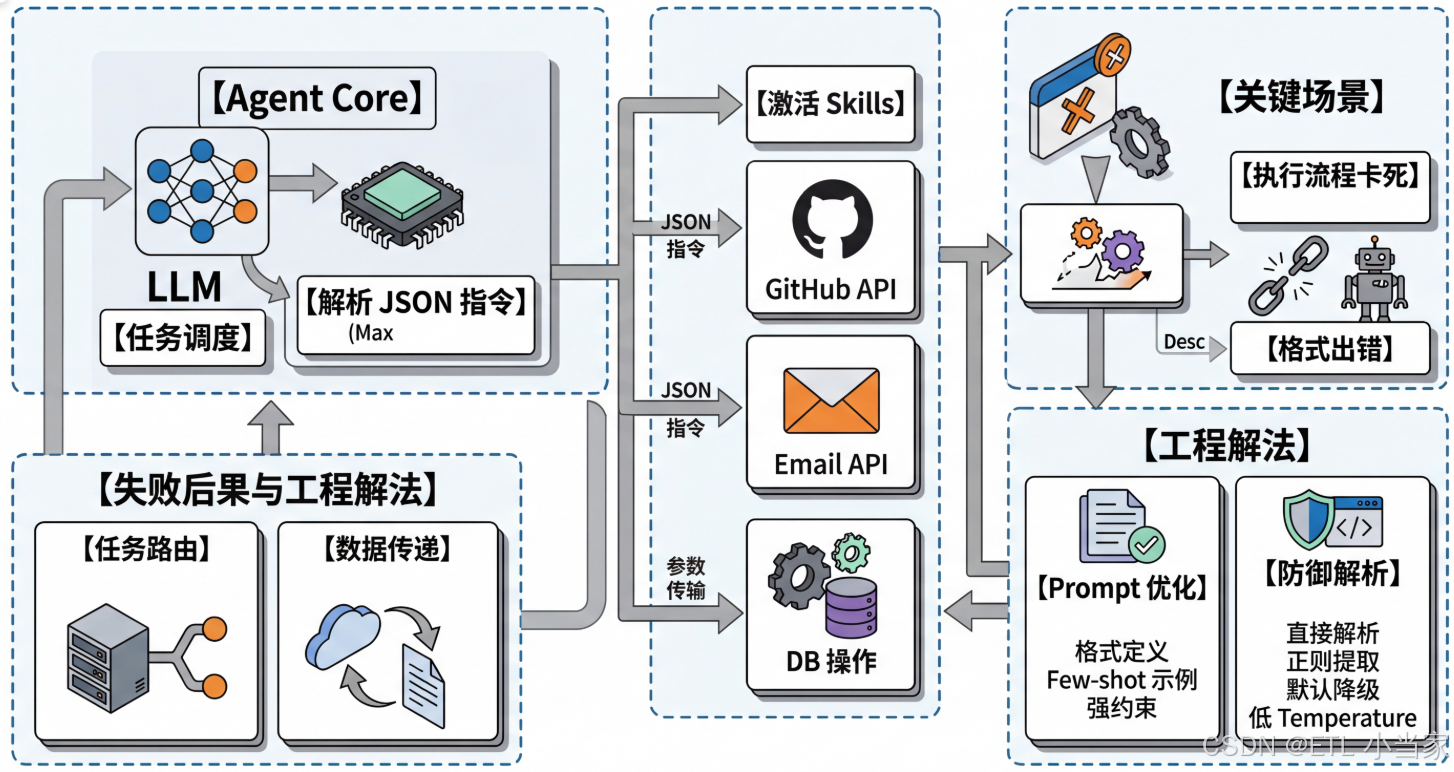
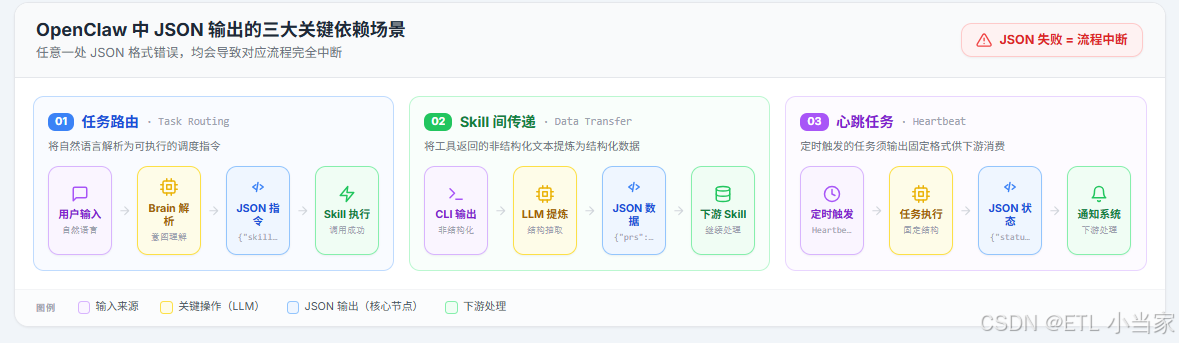
二、OpenClaw里JSON依赖的关键场景
在OpenClaw的执行流程里,JSON输出失败的后果是具体的,不是抽象的格式问题:
1. 任务路由(Task Routing)
用户说"帮我看一下有哪些open的PR",Brain需要把这句话解析成结构化的调度指令——要激活哪个Skill、传什么参数。这个解析结果是JSON,格式错了,Skill就没法被调用。
用户输入 → Brain解析 → {"skill": "github", "action": "list_prs", "args": {"state": "open"}} → Skill执行
2. Skill间数据传递
某个Skill执行完后,往往需要把工具返回的非结构化文本(命令行输出、网页内容)提炼成结构化数据,传给下一个Skill继续处理。这个"提炼"同样依赖LLM输出稳定的JSON。
GitHub CLI输出 → LLM提炼 → {"prs": [{"id": 42, "title": "...", "status": "open"}]} → 下一个Skill处理
3. Heartbeat任务执行
定时触发的Heartbeat任务通常有固定的输出结构(执行了什么、状态如何、下一步是什么),如果输出格式随机变化,下游的处理逻辑就无法写。
Heartbeat检查 → {"task": "email_check", "status": "completed", "result": {"count": 5}} → 通知系统处理
每一个箭头上标着JSON的地方,都是一个潜在的失败点。
三、为什么LLM输出JSON会不稳定?
LLM本质上是文字接龙,它不"理解"JSON是一种格式,只是学到了"在某些上下文下接下来应该输出这样排列的字符"。最常见的不稳定来源:
- 多余的文字:在JSON前后添加解释性文字
- Markdown代码块:用```json包裹JSON
- 字段缺失:忘记某些必需字段
- 类型错误:字符串写成数字,对象写成数组
- 格式不完整:缺少逗号、括号不匹配
这些问题都有对应的工程解法,但根子在Prompt设计上。
四、一个好Prompt的四个要素
以OpenClaw里任务路由这个场景为例,Prompt需要同时做对四件事:
1. 明确说明输出格式,给完整结构定义
不能只说"以JSON输出"——要把每个字段的类型、含义、约束值都写出来:
请严格按照以下JSON格式输出,不要添加任何其他文字、注释或Markdown代码块:
{
"skill": "string,要激活的Skill名称,只能是:github / notion / gmail / calendar",
"action": "string,具体操作",
"args": {
"key": "value"
},
"confidence": "number,0到1之间"
}
2. Few-shot示例比说明更有效
LLM对格式的"学习"很大程度上靠具体例子,而不是抽象描述:
示例输入:帮我看一下有哪些open的PR
示例输出:{"skill": "github", "action": "list_prs", "args": {"state": "open"}, "confidence": 0.95}
示例输入:把今天的日程发给我
示例输出:{"skill": "calendar", "action": "get_today", "args": {}, "confidence": 0.92}
3. 把最重要的约束用最直接的语言说出来
重要规则:
- 只输出JSON,没有任何其他文字
- 不要使用```json代码块包裹
- skill字段只能是上面列出的四个值之一
- 无法确定时,confidence设置为0.5以下,但仍然必须输出完整JSON
4. 低Temperature
格式约束清晰的Prompt配上低Temperature(0.0-0.1),是获得稳定结构化输出的最可靠组合。Temperature控制"创意程度"——输出JSON时你不需要创意,只需要准确。
五、在Skill的SKILL.md里怎么写
OpenClaw里最自然的格式约束位置是直接写在Skill的说明文档里。Brain读取Skill指令时,格式要求就已经进了上下文:
## Output Format
Always return your analysis as a single JSON object. No text before or after.
{
"action": "create_issue | close_pr | list_prs | check_ci",
"target": "repo name or PR number",
"args": {},
"reason": "one sentence explanation"
}
## Example
User: "Check if the login fix PR passed CI"
Output: {"action": "check_ci", "target": "42", "args": {}, "reason": "User wants CI status for PR #42"}
这样做的好处是格式约束和Skill的操作说明放在一起,不需要在Gateway层额外写Prompt——谁负责这个Skill的行为,谁就负责它的输出格式。
六、解析层的兜底处理
即使Prompt设计得再好,也不能假设LLM 100%遵守格式。OpenClaw这类Agent框架在接收LLM输出时,必须做防御性解析:
function parseSkillOutput(rawOutput) {
// 第一步:尝试直接解析
try {
return JSON.parse(rawOutput);
} catch (e) {
// 第二步:提取JSON块(处理有多余文字的情况)
const jsonMatch = rawOutput.match(/\{[\s\S]*\}/);
if (jsonMatch) {
try {
return JSON.parse(jsonMatch[0]);
} catch (e2) {
return handleParseFailure(rawOutput);
}
}
return handleParseFailure(rawOutput);
}
}
function handleParseFailure(rawOutput) {
// 记录原始输出,方便回头调整Prompt
console.error("JSON解析失败,原始输出:", rawOutput);
// 返回安全默认值,让任务优雅降级而不是直接崩溃
return { skill: "unknown", action: null, args: {}, confidence: 0 };
}
三层处理对应三种常见情况:
- 纯净JSON:直接解析成功
- 带多余文字的JSON:提取JSON块后解析
- 完全无法解析的输出:返回安全默认值
最后一种返回confidence: 0,让上游知道这次解析没有意义,可以选择重试或人工确认。
七、Prompt设计的演进路径
实际项目里,结构化输出的Prompt需要迭代。一个典型的演进路径:
| 版本 | 问题 | 改进 |
|---|---|---|
| v1 | 只说"输出JSON" | 解析成功率约60% |
| v2 | 添加具体格式说明 | 提升到75% |
| v3 | 加入Few-shot示例 | 提升到85% |
| v4 | 强化约束语言 | 提升到92% |
| v5 | 配合低Temperature | 达到95%+ |
大多数人会在v1就认为"LLM不稳定"然后放弃,但从v1到v5的差距完全可以通过工程手段弥补。清晰的格式说明通常可以把解析成功率从60%左右推到95%以上,配合解析兜底和重试,实际可用率可以接近99%。
八、深层思考:Agent工程的核心能力
从OpenClaw的视角来看,结构化JSON输出不是一个Prompt技巧问题,而是一个系统可靠性问题。
Skill的执行链越长,中间任何一个JSON解析失败的影响就越大——它不只是让这一步失败,而是让整条链路失败。这就是为什么Agent工程里对结构化输出的要求远比普通LLM应用严格得多。
一个能稳定输出结构化数据的Agent,才能真正接入下游系统,成为自动化流程里可信赖的一环。Prompt工程在Agent场景里最重要的能力,不是"让AI给出更好的答案",而是"让AI以可预期的格式给出答案"——这是Agent工程师和普通AI用户的核心能力分界线之一。
在Agent时代,可靠性比创造力更重要。你的LLM可以不够聪明,但必须足够可靠。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 18
18 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)