
OpenClaw Skill 与 OpenAI Function Calling 深度对比:一文看懂本质差异
本文对比了OpenAI Function Calling和OpenClaw Skill的核心差异。Function Calling通过JSON Schema定义结构化接口,由LLM决定调用时机并生成参数,开发者代码负责执行;而Skill通过自然语言说明书传递领域知识,LLM自行决定如何调用底层工具完成任务。前者强调可靠性和精确性,适合确定性任务;后者更具灵活性,适合复杂场景。两者可混合使用,底层用
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
OpenClaw Skill和OpenAI Function Calling有何异同?
by @Laizhuocheng
一、核心差异:接口 vs 知识
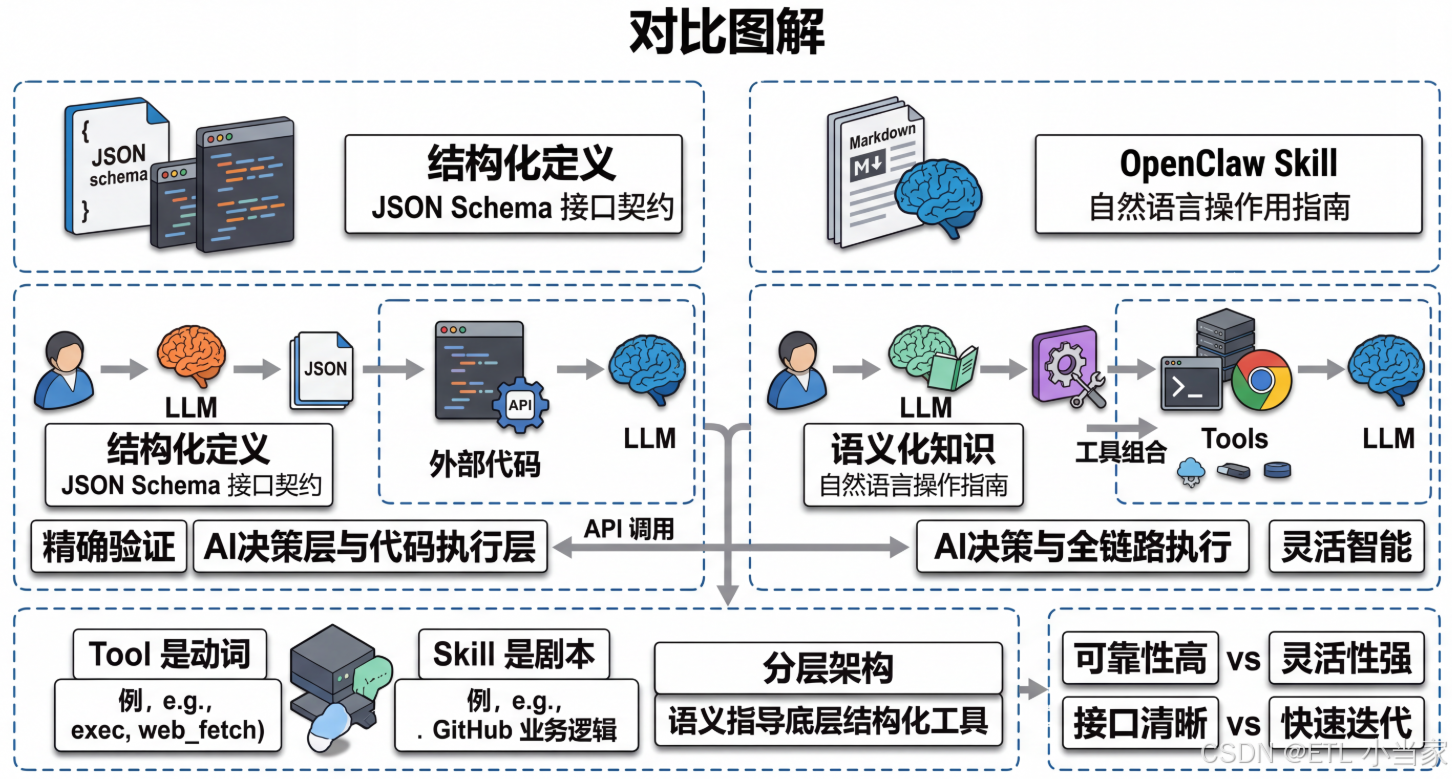
OpenAI Function Calling是你用JSON Schema定义一个函数接口,让LLM决定何时调用它并生成参数;OpenClaw Skill是你用自然语言写一份操作说明书,让LLM读懂后自己决定怎么用底层工具完成任务——前者定义的是"接口",后者传递的是"知识"。
说人话就是: 想象你要教别人做菜。Function Calling就像给厨师一张精确的食谱卡片:“材料:鸡蛋2个、番茄1个;步骤:1.打蛋 2.切番茄 3.炒蛋 4.加番茄”。而Skill就像给朋友一本烹饪指南:“番茄炒蛋的做法有很多种,关键是要掌握火候和调味。如果你喜欢酸甜口味,可以多放番茄;如果喜欢嫩滑口感,蛋要快速翻炒…”。
Function Calling是结构化的:你告诉模型"有一个叫get_weather的函数,接受city参数,返回天气数据"。模型只负责在合适的时候生成调用指令,实际执行由你的代码完成。
Skill是语义化的:你告诉模型"这是一份关于如何操作GitHub的说明,包括什么时候该用它、怎么用gh CLI命令、遇到问题怎么处理"。模型读懂说明后,用它已有的Tool(如exec)自行执行操作。
二、机制对比:谁在"执行"?
这是两者最根本的区别。
OpenAI Function Calling的流程:
用户请求 → LLM推理 → 生成函数调用 → 你的代码执行 → 返回结果 → LLM生成最终回答
LLM在这里做的事情是:决定调用什么,生成参数。真正的执行(查数据库、调API)发生在你自己的代码里,LLM看不到也控制不了具体的实现。
OpenClaw Skill的流程:
用户请求 → LLM读取Skill说明 → LLM决定调用哪些Tool → LLM生成Tool调用 → Tool执行 → 返回结果 → LLM生成最终回答
LLM在这里做的事情是:读懂说明书,然后自己决定调用哪些底层Tool,按什么顺序执行。Skill本身不是可执行代码,它是写给LLM看的自然语言指导。
三、定义方式的差异
这个差异在格式上一眼就能看出来。
Function Calling(OpenAI风格):
{
"name": "get_github_prs",
"description": "Get open pull requests for a repository",
"parameters": {
"type": "object",
"properties": {
"repo": {
"type": "string",
"description": "Repository in owner/name format"
},
"state": {
"type": "string",
"enum": ["open", "closed", "all"]
}
},
"required": ["repo"]
}
}
特点:
- 严格的JSON Schema
- 有类型定义,有枚举值
- 机器可以验证参数是否合法
- 接口契约明确
OpenClaw Skill(SKILL.md格式):
---
name: github
description: Interact with GitHub — review PRs, create issues, check CI status, and manage branches.
---
## When to use
Use when the user mentions GitHub, pull requests, code review, or asks to merge / create / close branches.
## How to use
1. Use `gh` CLI for most operations
2. Always confirm before merging or deleting branches
3. If `gh` is not installed, tell the user to install it first
特点:
- 纯自然语言
- 没有类型系统,没有参数验证
- LLM读懂这段文字后,自己决定怎么用exec Tool去运行gh命令
- 包含场景判断和最佳实践
四、各自的优势和局限
| 维度 | Function Calling | OpenClaw Skill |
|---|---|---|
| 定义方式 | JSON Schema(结构化) | Markdown自然语言(语义化) |
| 执行者 | 你的代码 | LLM自行调用底层Tool |
| 参数验证 | 有类型系统,机器可验证 | 无,依赖LLM理解 |
| 适合场景 | 接口清晰、需要确定性的操作 | 复杂多步骤、需要判断的任务 |
| 扩展方式 | 增加新函数定义 | 增加新Skill文件 |
| 错误处理 | 代码层精确捕获 | LLM自行判断,非确定性 |
| 可测试性 | 单元测试友好 | 难以穷举测试 |
Function Calling的优势:可靠性
- 函数定义是机器可读的,参数类型有约束
- 执行结果可以精确捕获和处理
- 错误边界清晰,便于调试和监控
- 性能可预测,不会出现意外的LLM行为
Skill的优势:灵活性
- 不需要预先枚举所有可能的参数和场景
- LLM可以根据上下文灵活解读说明书
- 处理各种未预料到的情况
- 开发成本低,自然语言比JSON Schema更容易编写和维护

五、两者并不互斥
一个关键事实:OpenClaw底层仍然在使用类似Function Calling的机制——exec、web_fetch、browser这些Tool,都是以结构化方式暴露给LLM的能力接口。
Skill是在这些Tool之上加了一层"领域知识":它告诉LLM在具体的业务场景下(比如操作GitHub),该如何组合使用这些底层Tool。
可以把它理解成两层抽象:
- Tool是动词(能做什么)
- Skill是剧本(在什么场景下按什么顺序用这些动词)
实际工作流程示例
当用户说"帮我看看GitHub上有没有新的PR":
Function Calling方式:
- LLM识别需要调用
get_github_prs函数 - 生成参数:
{"repo": "myorg/myproject", "state": "open"} - 你的代码执行GitHub API调用
- 返回PR列表给LLM
- LLM生成最终回答
OpenClaw Skill方式:
- LLM读取github Skill说明
- 决定使用
execTool运行gh pr list --repo myorg/myproject - 执行命令获取PR列表
- LLM直接处理输出并生成回答
六、开发哲学的差异
Function Calling和Skill的差异,折射出两种不同的AI应用开发哲学。
Function Calling代表的哲学:
“AI作为决策层,代码作为执行层”
- 职责清晰分离
- 需要开发者为每种能力预先写好执行代码
- 适合传统软件工程思维
- 强调可靠性和可维护性
Skill代表的哲学:
“AI既是决策层也是执行层”
- 开发者只需写说明,AI负责从理解到执行的全链路
- 代价是引入了不确定性
- 适合敏捷开发和快速迭代
- 强调灵活性和开发效率
七、未来趋势与选择建议
随着LLM能力的持续提升,我们可能会看到越来越多的系统向Skill这种范式迁移——因为用自然语言写说明,远比维护大量JSON Schema更低成本,也更容易被非专业开发者参与贡献。ClawHub上超过3000个社区贡献的Skill已经在验证这个方向。
选择建议
选择Function Calling当:
- 任务接口清晰、参数明确
- 对可靠性要求极高(金融、医疗等场景)
- 需要精确的错误处理和监控
- 团队有较强的工程能力
选择OpenClaw Skill当:
- 任务复杂、涉及多步骤协调
- 需要处理模糊或变化的需求
- 开发资源有限,追求快速迭代
- 希望降低非技术用户的参与门槛
混合使用策略
实际上,最好的方案往往是混合使用:
- 核心能力用Function Calling保证可靠性
- 复杂场景用Skill提供灵活性
- 底层Tool保持结构化,上层Skill提供语义指导
这种分层架构既能享受LLM的智能,又能保持系统的可控性,是当前AI Agent开发的最佳实践。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 18
18 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)