




- @2301_76161259
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LangChain 1.0和LangGraph 1.0正式发布,标志着AI应用开发进入工程化时代。LangChain作为高层抽象框架,适合快速构建简单线性任务和标准RAG系统;LangGraph作为底层运行时引擎,专为复杂、有状态、多智能体协作的生产级系统设计。开发者可根据任务复杂度选择使用,实现从概念验证到生产部署的平滑过渡。

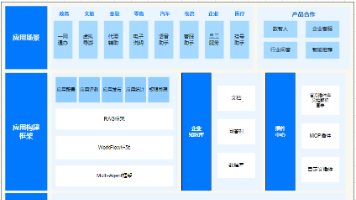
智能体开发平台由RAG、Workflow和Agent三大技术支柱构成,分别解决知识边界、流程边界和自主程度边界问题。平台核心价值是将大模型不确定性约束在确定的业务框架内,构建企业级数字员工。当前面临三大支柱协同、工具调用稳定性和复杂场景鲁棒性等技术深水区。未来将向评估体系标准化、能力模块化及人机协同设计演进,真正成为产业智能化的基础设施。
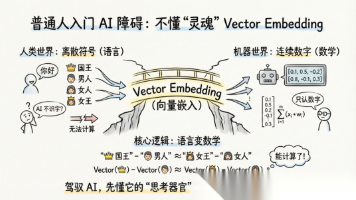
本文揭示了一个关键认知:AI并不"识字",它只处理数字。Vector Embedding是将人类语言转换为数字坐标的核心技术,使AI能通过计算向量距离理解语义关系。文章用"标本盒里的蝴蝶"生动比喻这一原理,指出掌握"坐标思维"是高效使用AI的关键。理解这一底层逻辑,能帮助用户从表层使用转向深度驾驭AI,大幅提升效率,构建AI时代的竞争优势。
本文介绍了Dify、Coze、ChatWiki和FastGPT这四大智能体平台,它们各有特色,适合不同层次的用户。Dify是一款开源的大语言模型应用开发平台,融合了后端即服务和LLMOps理念,支持多种LLMs和推理提供商;Coze是一个可视化AI应用开发平台,提供灵活的工作流设计和丰富的插件工具;ChatWiki是一款开源的知识库AI问答系统,基于LLM和RAG技术,支持Graph RAG;Fa
LangChain 1.0和LangGraph 1.0正式发布,标志着AI应用开发进入工程化时代。LangChain作为高层抽象框架,适合快速构建简单线性任务和标准RAG系统;LangGraph作为底层运行时引擎,专为复杂、有状态、多智能体协作的生产级系统设计。开发者可根据任务复杂度选择使用,实现从概念验证到生产部署的平滑过渡。
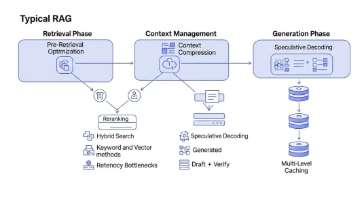
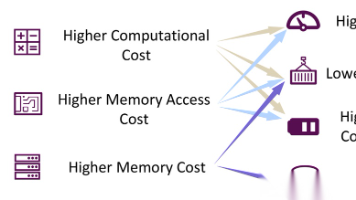
大规模RAG系统延迟优化需跳出局部思维,采用系统级改造策略。文章提出多层次优化方案:检索阶段采用多级召回与混合检索;上下文管理通过重排序与压缩技术;生成阶段利用高效推理框架与量化技术;系统级层面实施多级缓存与智能路由。只有将各环节有机结合,才能构建真正低延迟、高吞吐的RAG系统,避免"头痛医头脚痛医脚"的优化陷阱。
本文详细解析了大语言模型(LLM)的推理优化技术,指出模型大小、注意力机制和解码机制是影响推理效率的三大因素。从数据、模型和系统三个维度介绍了优化方法:输入压缩、输出组织、高效结构设计、模型压缩及推理引擎优化等,有效解决LLM推理中的高延迟、低吞吐和高存储问题,提升模型实际应用性能。
文章介绍了使用腾讯IMA工具构建精简AI知识库的实践指南。强调知识库应"精"而非"多",建议为不同主题创建小型专业库。详细解释了RAG技术原理,分析了AI知识库的常见问题如幻觉和不精准检索,并提出了针对性解决方案。展望了未来多语种平行文本知识库的发展方向,指出AI知识库将改变传统研究方式,特别适合查缺补漏和文献整理。
Coze是一个AI应用开发平台,允许用户无需编程基础通过拖拽方式创建智能体。它提供灵活的工作流设计、丰富的插件和知识库支持,用户可自定义插件并管理数据。此外,Coze还具备持久记忆能力,方便AI交互。文章以创建朋友圈文案生成器为例,详细介绍了使用Coze搭建智能体的过程,旨在帮助新手快速上手AI开发。

一句话总结:传统编程和 Workflow 都是人在做决策、提前设计好所有逻辑,而 Agent 是 AI 在做决策,能够解决原有写程序不能解决的问题,因此更容易做出差异化的体验,也因此更适合作为下一代的用户交互新范式。就像目前大家都在用的coding agent 一样,未来会有更多面向不同领域的agent涌现。
