




- @zoubaihan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
查看缺失值和重复值在这里说一下哪些算缺失值。比如某一列明明该有一个数,但是却压根就没有数。这会导致程序运行的时候报错,提示无法转换NaN(Not a Number)。天池给的这数据集里缺失值特别多,刚开始跑程序的时候到处都报错NaN。所以查看一下缺失值情况是必要的,下面代码用来查看缺失值和重复值:missing=data_all.isnull().sum()missing=missing[miss
背景介绍这两天开始研究天池上面的数据挖掘入门比赛:二手车交易价格预测。本来觉得是一个比较简单的项目吧,套用一下keras解决波士顿房价回归预测的模型,写一个简单的神经网络把数据输入进去,就可以了。因此我一直以为深度学习的基本步骤是:(1)数据准备(2)模型选择&模型开发(3)模型评估(evaluate)(4)模型预测(5)模型调优(调参)万万没想到啊,这个二手车交易价格预测,要想预测得准确
目前,RAG中的Chunking技术已经从传统的固定分块发展到更加智能的分块策略。Late Chunking和Agentic Chunking代表了两种不同的技术路线:前者通过改变嵌入流程来保留上下文信息,后者通过LLM的智能判断来优化分块策略。从实际应用效果来看,这些方法在提高检索准确性和生成质量方面取得了显著成果。例如,Late Chunking在柏林示例中将相似度从0.708提升到0.825
在传统的语言模型(如 GPT、T5)生成过程中,我们常常只看到“输入-输出”模式:给出问题,模型直接给答案。想一下题意,然后做拆解,接着逐步推理,最后才得到答案。这种“分步骤思考”的过程,其实就是“思维链(Chain of Thought, CoT)思维链通过引导语言模型像人类一样“分步骤地思考”,极大提升了模型处理**多步推理任务(multi-step reasoning)**的能力,特别在数学
模型微调不仅是模型“听懂你”的第一步,更是企业打造私有智能体的核心环节。懂得 Prompt 是入门,会微调,才是真正走向 AI 工程师的开始。大模型微调技术已经成为人工智能领域的核心技术之一,它使预训练模型能够更好地适应各种特定任务和领域。从全量微调到参数高效微调,再到指令微调,技术的不断进步使我们能够在资源有限的情况下获得更好的模型性能。在实际应用中,选择合适的微调技术需要综合考虑模型大小、数据
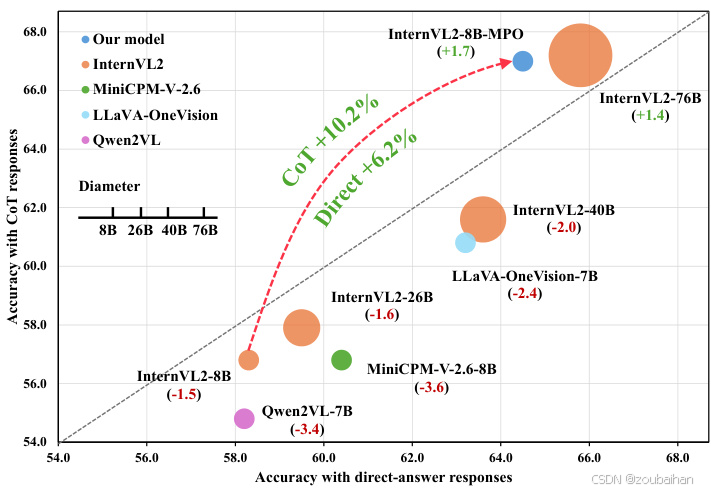
多模态大语言模型(MLLMs)在预训练和监督微调(SFT)的训练范式下,已经在多个领域和任务中取得了显著成就。然而,这些模型在链式思考(CoT)推理方面的表现却不尽如人意,尤其是在处理多模态数据时。为了克服这一挑战,上海人工智能实验室的研究团队提出了一种基于混合偏好优化(MPO)的新方法,旨在通过自动化偏好数据构建管道和创新的训练策略,提升MLLMs的多模态推理能力。
解决前端接收服务器发送的数据时EventSource的onmessage不执行的问题

解决前端接收服务器发送的数据时EventSource的onmessage不执行的问题
问题在VSCode新建了一个项目,用VSCode运行Python代码时,发现有如下几个选项:直接点击这个三角形的话,默认执行的是第一项Run Code。但如果Python代码需要依赖于指定的虚拟环境,直接点击Run Code运行的话,会发现代码的输出结果是在控制台的Output框里面,而非Terminal框,此时就会报错环境问题:看了一下,我已经在Settings里面通过Select Python
问题重述vmware里面设置共享文件夹,但是mnt/hgfs这个目录要么就没有,要么就是permission denied,命令加sudo也没用。网上说的chomd 777那些解决办法都没用。解决方法用这个博客内容可以解决:解决VMware中共享文件夹hgfs的权限问题或者这个CSDN写的也可以:VMware虚拟机中共享文件夹hgfs缺失或权限有问题打不开上述博客要求查看自己的uid和gid,可以