- @zfw_666666
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目录1. Atlas介绍2. 安装配置3. Atlas功能测试4. 生产用户要求5. Atlas基本管理5.1 连接管理接口5.2 打印帮助5.3 查询后端所有节点信息5.4 上线或下线节点5.5 添加删除节点5.6 用户管理5.7 保存配置到配置文件6. 自动分表6.1介绍7. 关于读写分离建议8. 中间件介绍1. Atlas介绍Atlas是由 Qihoo 360, Web平台部基础架构团队开发
退出代码0表示特定容器没有附加前台进程该退出代码是所有其他后续退出代码的例外,一般是容器正常退出,程序自动退出。这不一定意味着发生了不好的事情。如果开发人员想要在容器完成其工作后自动停止其容器,则使用此退出代码。比如:kubernetes job 在执行完任务后正常退出码为 0。
若你的/etc/docker/daemon.json有额外的自定义配置信息也会输出到这里,摘掉即可。
Trivy(tri 发音为 trigger,vy 发音为 envy)是一个简单而全面的漏洞/错误配置扫描器,用于容器和其他工件。软件漏洞是软件或操作系统中存在的故障、缺陷或弱点。Trivy 检测操作系统包(Alpine、RHEL、CentOS 等)和特定语言包(Bundler、Composer、npm、yarn 等)的漏洞。此外,Trivy 会扫描基础设施即代码 (IaC) 文件,例如 Terra

Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地
vmstorage 是 VictoriaMetrics 时序数据库系统中的核心存储组件,负责时间序列数据的持久化存储和查询服务。
1:zabbix是一个写多读少的业务,优化数据库的写入性能,建议使用tokudb存储引擎2:功能上的优化,精简无用的监控项,适当增加取值间隔,减少数据的保留周期3:定时任务,分库分表处理4:进程优化(适当增加进程数)5:缓存优化(适当增加缓存的大小)vim /etc/zabbix/zabbix_server.confStartPollers=30默认5轮询器实例数量一般规则 -保持此参数的值尽可能
下载zabbix-agent软件包到本地:下载完->双击运行应用->配置Host Name:10.0.0.1 Zabbix-Server:10.0.0.71->安装Zabbix界面选择链接模板:
LVM是Linux系统中对磁盘分区进行管理的一种逻辑机制,它是建立在硬盘和分区之上,文件系统之下的一个逻辑层,在建立文件系统时屏蔽了下层的磁盘分区布局,能够在保持现有数据不变的情况下动态调整磁盘容量,从而提高磁盘管理的灵活性。需要注意的是,“/boot”分区不能基于LVM创建,必须独立出来。
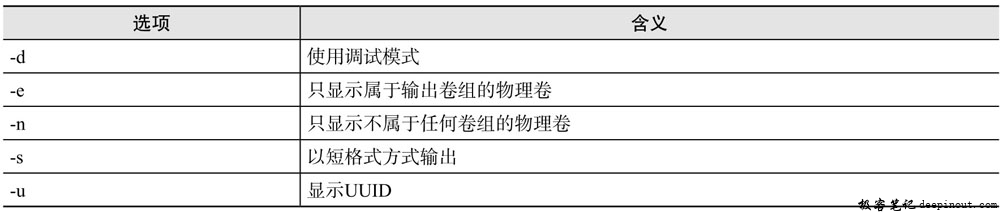
架构解析】将Harbor的redis缓存组件、PostgreSQL数据库组件迁移到系统外部做高可用,使用外部共享存储实现多个Harbor实例的数据共享,Harbor实例可横向扩展。