




- @z099164
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
近些年,人工智能应用铺天盖地。人脸识别、老照片复活、换脸等应用都得益于人工智能算法。许多人工智能算法封装的框架基于 Python 语言,这也导致了 Python 的热度只增不减。Python 简单易学,根据 2020 年 StackOverflow 开发者调查报告显示,Python 是世界上最受欢迎的编程语言,排名仅次于 Rust 和 TypeScript。
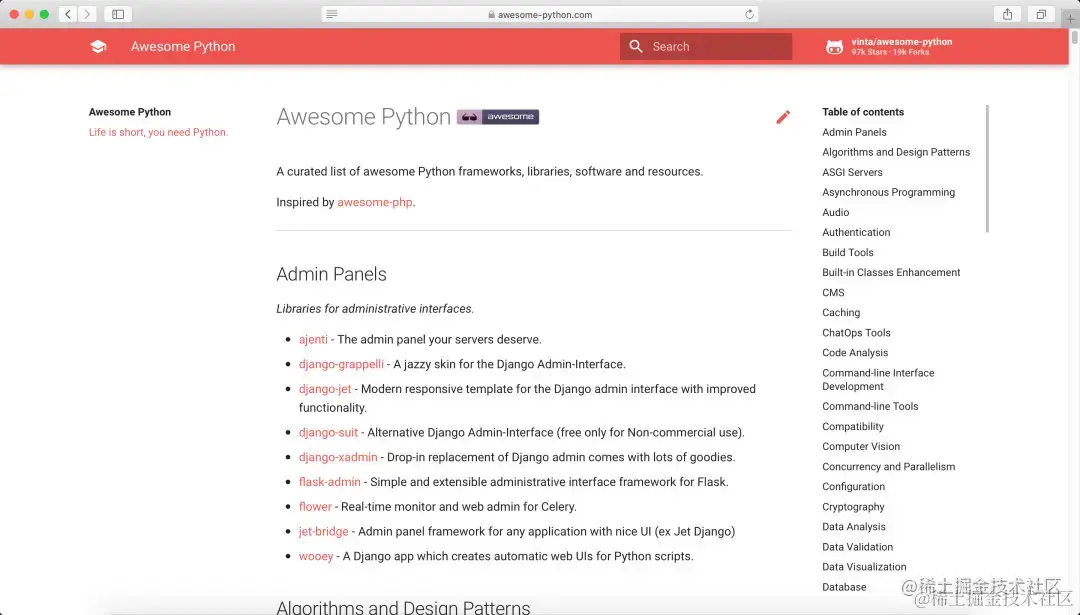
如何用python做数据分析?
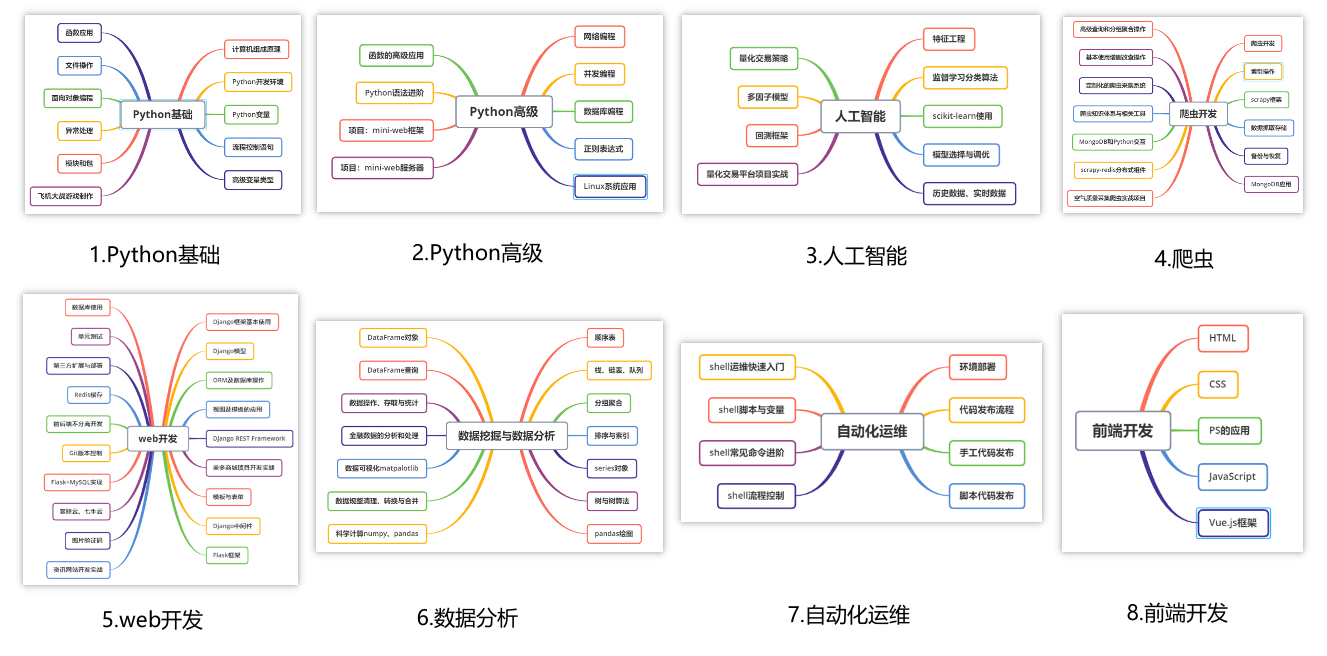
今天的主题是:使用Python联动飞书文档+机器人,实现一个专属的记账助手,这篇文章如果对你帮助极大,欢迎你分享给你的朋友、她、他,一起成长。也欢迎大家留言,说说自己想看什么主题的Python文章,留言越具体,我写的越快,比如留言:我想看Python 自动操作Excel 相关文章。开通消息事件之前,需要先在服务器部署一个简单 web 服务用于接收消息,如下图,没啥特别要求,用 flask 快速写一

Python机器学习案例:梵高的《星空》图片压缩本案例将奇异值分解用于处理图像压缩任务。

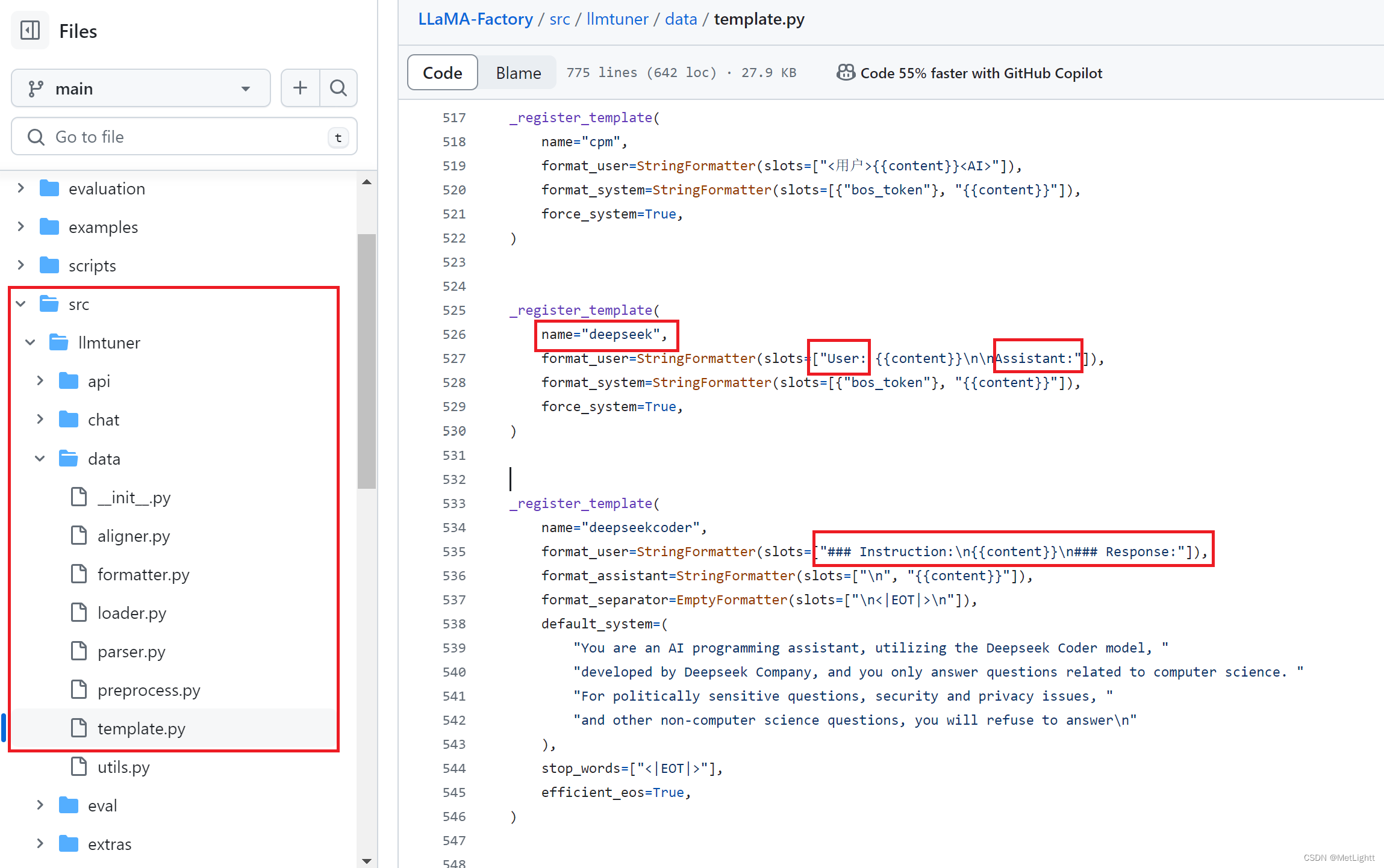
1. 准备好硬件(GPU)、数据;通过各方面的资讯选中你想要微调的基座模型2. 准备好代码:输入数据 + 模型 -> 在GPU上反复训练3. 训练结束以后,得到训练过程中的checkpoint + 一些log信息4. 根据log信息选一些比较有希望的checkpoint在自己的测试集上推理,获得相应的结果5. 分析结果,获得下一轮实验(数据、训练方案的迭代)思路而LLaMA-Factory就是一个
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来

感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,
大型语言模型是一种基于大量文本数据(如书籍、文章、新闻、博客和社交媒体帖子等)训练的人工神经网络。这种模型能够学习自然语言的语法、语法、词汇及语义等结构和模式,并掌握文本中的日期、名称、地点、事件和概念等知识和事实。大型语言模型由多层神经元组成,这些神经元负责处理输入文本并生成输出文本。输入可以是一个词、一个短语、一句话或一段文字,而输出则可能是下一个词、下一句话或整篇文章。此外,输出还可以基于某

机器学习是一门强大的工具,可以用于解决各种各样的问题。通过学习机器学习,您可以开发出能够自动化任务、做出预测甚至创造艺术的应用程序。如果您是一名 Python 开发人员,那么您将很高兴知道,有许多可以用 Python 构建的有趣机器学习应用程序。在本博客文章中,我们将介绍 10 个这样的应用程序。
大家好,最近好多朋友在问我,国内是否有好用的大模型,今天我就整理好 8 款大模型,大家可以多尝试,一定会有不一样的感觉。01HOTSPOTKimiKimi 是由月之暗面科技有限公司开发的人工智能助手。它擅长中英文对话,能够提供安全、有帮助、准确的回答。同时能够阅读和理解用户上传的文件,访问互联网,并且结合搜索结果来回答问题。也能够处理多种文件格式,包括但不限于TXT、PDF、Word文档、PPT幻
