




- @yiqiedouhao11
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
FlashAttention绝对是大模型训练和推理的必备技巧,它通过巧妙的分块计算和访存优化,解决了注意力机制显存占用过高的问题,同时还能提升计算速度。现在很多主流大模型框架(比如LLaMA、GPT-2的实现)都已经默认支持FlashAttention,如果你还在被显存不足困扰,赶紧把这个神技用起来!个人能力有限,有问题随时交流~

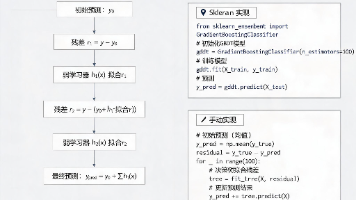
变分自编码器(Variational Autoencoder,VAE)是深度学习中经典的生成模型之一,它结合了自编码器的结构和变分推断的思想,既能完成数据压缩,又能实现数据生成。本文将从原理到代码,一步步拆解VAE的核心逻辑。VAE的本质是通过学习数据的潜在分布,实现从低维隐空间到高维数据空间的映射。和传统自编码器不同,VAE不是直接学习输入到隐向量的确定性映射,而是学习隐向量的概率分布,这也是它
能处理非线性特征,拟合复杂的数据分布;对特征的尺度不敏感,不需要做标准化处理;可以自动进行特征选择,输出特征重要性;模型的预测精度较高,在很多竞赛和实际任务中表现优异。
大模型常用的数值格式主要分为两大类:浮点格式(遵循IEEE标准,由符号位+指数位+尾数位组成,原生存储小数)和整数量化格式(无指数位,通过将小数映射为固定区间整数来实现压缩)。核心规律位数越少,显存占用越小、计算速度越快,但精度越低。指数位越多,数值范围越大,越不易溢出。尾数位越多,小数精度越高。

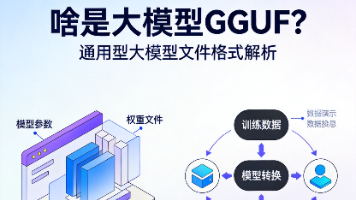
如果你最近在折腾开源大模型,尤其是在个人电脑、树莓派这类边缘设备上跑模型,大概率会碰到GGUF这个格式。它不像PyTorch的.pt或者TensorFlow的.pb那么“正统”,但却是当下圈里最火的轻量化模型格式之一,今天就把它的来龙去脉说清楚。
智能指针是C++中管理动态内存的最佳实践,通过RAII机制彻底解决了手动管理内存的痛点。独占资源用unique_ptr,高效且安全共享资源用shared_ptr,配合引用计数实现自动释放循环引用用weak_ptr,作为辅助工具打破循环掌握这三种智能指针,你的C++代码会更健壮,再也不用为内存泄漏头疼啦!个人能力有限,有问题随时交流~

显存占用降低3-5倍,让普通GPU也能处理更长的文本序列;计算速度提升2-4倍,减少大模型训练的时间成本;后续的FlashAttention2、FlashAttention3都是在这个基础上做的硬件级优化,但核心的分块+重计算思路没变。如果你正在做长文本大模型开发,或者觉得注意力计算太卡显存,一定要试试FlashAttention系列的实现!个人能力有限,有问题随时交流~
FlashAttention绝对是大模型训练和推理的必备技巧,它通过巧妙的分块计算和访存优化,解决了注意力机制显存占用过高的问题,同时还能提升计算速度。现在很多主流大模型框架(比如LLaMA、GPT-2的实现)都已经默认支持FlashAttention,如果你还在被显存不足困扰,赶紧把这个神技用起来!个人能力有限,有问题随时交流~
RMSNorm的故事其实很有意思:它没有引入复杂的数学理论,也没有颠覆式的创新,只是对现有方法做了一次"减法"——去掉了看似必要但实际冗余的步骤,却在大模型时代发挥了巨大的价值。这也给我们一个启示:在AI技术的发展中,有时候最有效的创新不是"做加法",而是"做减法"——找到那些看似不可或缺,但实际上可以简化的环节,往往能带来意想不到的提升。从这个角度看,RMSNorm确实称得上是大模型的"隐秘功臣

泛化能力拉满:支持超长文本外推,训练短文本,推理长文本也能用计算效率高:不需要额外存储位置编码向量,推理时实时计算,节省内存相对位置感知:不仅能知道词的绝对位置,还能感知词与词之间的相对距离,更符合人类语言逻辑无缝集成:可以直接和Transformer的注意力机制融合,不用改模型的核心结构现在再回头看开头的问题,大模型之所以能区分"我爱吃苹果"和"苹果爱吃我",就是因为ROPE给每个词加了独特的位
