




- @xzpdxz
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文介绍了vLLM框架中第三方平台插件的识别机制。通过Python的entry_points机制,插件可被自动发现和加载。以GCU平台为例,详细说明了插件开发流程:1)创建包含设备检测函数的插件包;2)实现Platform类提供设备接口;3)在setup.py中注册插件。vLLM启动时会扫描所有注册插件,调用检测函数识别可用设备,并动态加载对应平台类。环境变量VLLM_PLUGINS可控制插

【代码】【vLLM大模型TPS测试三部曲】
PH8平台提供国内最低价的Claude Code大模型编程方案,支持Qwen2.5-7B、DeepSeek-V3等国产模型,价格仅为市场1/4。用户可通过简单配置切换不同模型,还提供智能成本优化脚本和多模型对比使用策略。该方案具有国内直连、按需计费、响应快等优势,特别适合需要频繁使用AI编程助手的开发者,能显著降低使用成本同时保持良好体验。平台还提供免费额度供新用户体验。
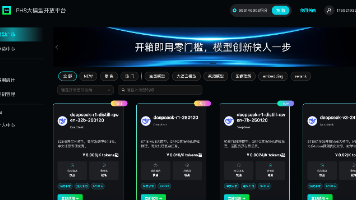
通过gloo通信,可以将各家芯片通信联通通过梯度更新实验,证明方式可行。
vLLM模型加载流程:EngineCore初始化时创建Executor,后者为每个GPU rank创建Worker进程。Worker通过GPUModelRunner加载模型,包括初始化分布式环境、加载权重、应用量化/LoRA优化,并分析内存使用。整个过程在独立Worker进程中完成,主进程仅负责协调。

PH8平台提供国内最低价的Claude Code大模型编程方案,支持Qwen2.5-7B、DeepSeek-V3等国产模型,价格仅为市场1/4。用户可通过简单配置切换不同模型,还提供智能成本优化脚本和多模型对比使用策略。该方案具有国内直连、按需计费、响应快等优势,特别适合需要频繁使用AI编程助手的开发者,能显著降低使用成本同时保持良好体验。平台还提供免费额度供新用户体验。
摘要:本文介绍了vLLM框架中第三方平台插件的识别机制。通过Python的entry_points机制,插件可被自动发现和加载。以GCU平台为例,详细说明了插件开发流程:1)创建包含设备检测函数的插件包;2)实现Platform类提供设备接口;3)在setup.py中注册插件。vLLM启动时会扫描所有注册插件,调用检测函数识别可用设备,并动态加载对应平台类。环境变量VLLM_PLUGINS可控制插
vLLM模型加载流程:EngineCore初始化时创建Executor,后者为每个GPU rank创建Worker进程。Worker通过GPUModelRunner加载模型,包括初始化分布式环境、加载权重、应用量化/LoRA优化,并分析内存使用。整个过程在独立Worker进程中完成,主进程仅负责协调。
快速使用spring-boot来构建web应用java基础及mvn创建应用重要概念什么是注解:带有@符号的就是注解,注解起一个解释标识作用,程序会根据反射来找对应的函数什么是javaBean对象:在spring框架中,带有javaBean注解的类将被自动实例化,无序用户在new操作,对于单例模式时非常友好的程序如何执行的:在spring中,程序的执行会根据注解反射对象进行实例化,也就是程序会不断根