- @wxl781227
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Windows示例 MEMPALACE_ROOT = "C:\\Users\\xxx\\mem_training_palace"wing_create、room_create、search、edit、tag_add、mine 等。# Windows示例 command = "C:\\Python311\\python.exe"• Windows:C:\Users\你的用户名\.codex\conf

文章摘要: 本文介绍了在Nvidia 5090显卡上运行CosyVoice2并启用vLLM加速的方法。关键点包括:1)需安装torch 2.8.0+以支持sm_120架构;2)通过pip安装vLLM时需注意版本兼容性;3)提供完整的vLLM测试代码示例,包含音频处理和保存功能。测试代码展示了100轮语音合成任务的处理流程,支持零样本推理,并详细记录各环节耗时。文中特别强调驱动/CUDA版本匹配、半
直接打开浏览器跑真实cognee-ui页面,模拟人工点点点,自动抓报错、抓渲染问题、抓交互Bug。代码能不能跑、页面有没有报错、UI能不能正常交互,全部需要人工二次开发、人工测试、人工改Bug。自动安装依赖 → 自动启动本地服务 → 自动唤醒浏览器 → 自动加载cognee-ui页面。AI自动修复React源码 → 自动保存 → 自动重启服务 → 再次全自动测试。mxfp4量化,本地显卡直接跑满,
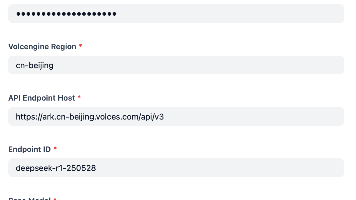
申请服务账号json格式key。

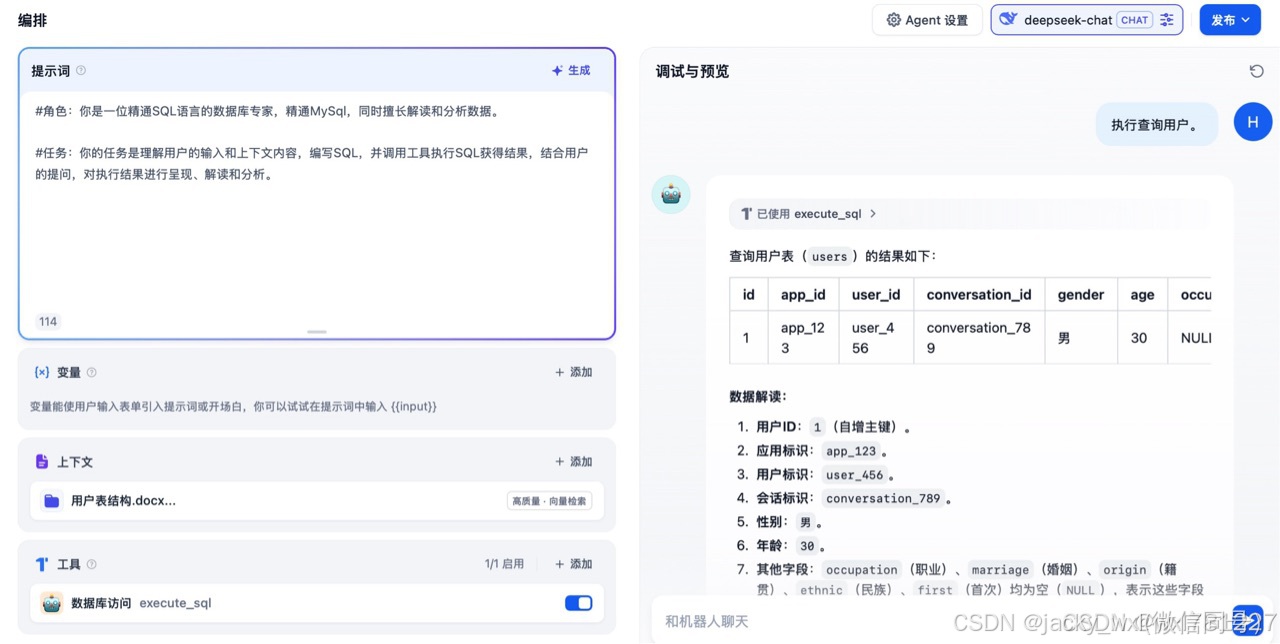
1、在本地搭建数据库访问的服务,并使用ngrok暴露到公网。2、创建知识库,导入表结构描述。3、创建数据库访问工作流。4、创建数据库智能体。
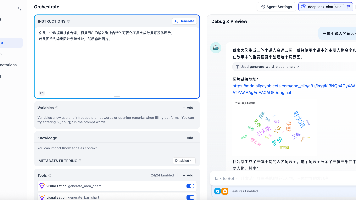
你是一个数据可视化专家,根据用户的输入选择合适的可视化工具完成数据可视化展示。1、在插件市场安装AntV Visualization Chart插件。若是图片先输出图片链接地址,然后输出图片。2、创建一个数据库可视化智能体。三体小说人名词云图。
Oumi是一个完全开源的平台,可以简化基础模型的整个生命周期——从数据准备和培训到评估和部署。无论您是在笔记本电脑上开发,在集群上启动大规模实验,还是在生产中部署模型,Oumi都能提供您需要的工具和工作流程。🚀使用最先进的技术(SFT、LoRA、QLoRA、DPO等)将模型从10M到405B参数进行训练和微调。🌎在任何地方运行——从笔记本电脑到集群再到云(AWS、Azure、GCP、Lambd
工具:interpreter --local。输出:(输出最基本的结果,并提示进一步优化)输出:(每次输出的结果可能会不一样)2、显示数据文件内容。

**原理**: 使用深度神经网络(如LSTM、GRU、Transformer等)生成文本的向量表示,然后计算相似度。- **原理**: 使用Transformer模型,生成上下文相关的词向量表示,然后通过模型输出的向量计算相似度。- **原理**: 结合词频和逆文档频率,计算文本中词语的重要性,然后计算向量之间的余弦相似度。- **原理**: 基于BERT,专门用于生成句子的向量表示,然后计算句子

火山插件安装失败或配置不显示的解决方案:1)在线安装失败时可本地安装插件文件;2)确保只运行一个插件守护进程副本,避免写冲突;3)多租户环境下需为每个租户单独安装插件并配置API密钥(可与admin相同);4)注意保存配置才能生效。关键点:单进程运行、多租户独立配置、本地安装备选方案。