




- @weixin_70682362
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
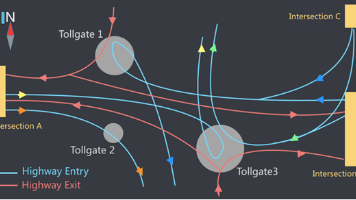
Vissim是德国PTV公司开发的微观交通流仿真软件,核心功能围绕交通场景模拟与系统分析展开。它能构建高速公路、环岛、停车场等复杂交通环境,通过Wiedemann驾驶行为模型模拟车辆跟驰、车道变换等行为,同时支持机动车、卡车、有轨交通及行人的交互仿真。在信号控制方面,可模拟定时控制、车辆感应控制及SCATS、SCOOT等系统,还能通过VAP自定义控制方法,满足多样化信号方案的设计与检验需求。此外,
希望这份路线图和实战案例能帮助你顺利启程。如果你能告诉我你的编程基础(例如,是完全零基础,还是有其他语言经验),或者具体想分析什么类型的数据(如商业、金融、生物等),我可以给你更具体的学习资源建议。以下是一个整合了数据加载、探索、可视化、建模与评估的完整数据分析流程示例,使用了第二、三阶段的核心库。整个路线可以划分为四个阶段,以下表格汇总了每个阶段的核心目标、关键技能与建议时间。

在Excel中,有一些用于数据分析的功能和工具库,以下是主要的一些和基本的分析流程:

要将 DeepSeek 的 AI 功能接入 Microsoft Word,通常需要通过 API 调用并结合 VBA(Visual Basic for Applications)或 Office 插件开发。适用于简单文本生成或分析场景。

通过以上方案,开发者可在PyCharm中实现从基础API调用到复杂业务逻辑的全链路AI赋能。建议根据项目需求选择:新手优先使用插件或SDK;企业级项目采用原生HTTP请求结合云端部署;高性能场景可尝试异步调用和批量处理。同时需注意成本监控与数据安全,确保AI赋能的可持续性。

Git 是一款免费、开源的分布式版本控制系统,他是著名的 Linux 发明者 Linus Torvalds 开发的。而GitHub 上面说了,主要提供基于 git 的版本托管服务。也就是说现在 GitHub 上托管的所有项目代码都是基于 Git 来进行版本控制的,所以 Git 只是 GitHub 上用来管理项目的一个工具而已,GitHub 的功能可远不止于此!

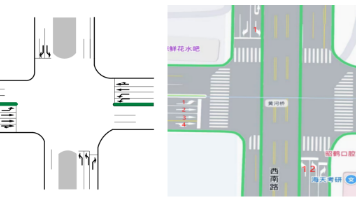
数据处理是将原始数据转化为有价值信息的过程,涉及数据收集、清洗、集成、转换、存储、分析和应用等流程。其核心目标是提升数据质量,包括处理缺失值、异常值和格式标准化,并通过转换和集成形成统一视图。数据分析阶段应用统计和机器学习方法挖掘模式,最终通过可视化和应用实现价值。数据处理面临大数据实时处理、隐私保护等挑战,未来趋势包括自动化工具和流式计算。整个过程需遵循准确性、一致性和可追溯原则,确保数据可靠可
