




- @weixin_59295776
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
java虚拟机主要分为以下几个区:1) 方法区:a. 有时候也成为永久代,在该区内很少发生垃圾回收,但是并不代表不发生GC,在这里进行的GC主要是对方法区里的常量池和对类型的卸载b. 方法区主要用来存储已被虚拟机加载的类的信息、常量、静态变量和即时编译器编译后的代码等数据。c. 该区域是被线程共享的。d. 方法区里有一个运行时常量池,用于存放静态编译产生的字面量和符号引用。该常量池具有动态性,也就
实现通过类的权限定名获取该类的二进制字节流的代码块叫做类加载器。主要有一下四种类加载器:1) 启动类加载器(Bootstrap ClassLoader)用来加载java核心类库,无法被java程序直接引用。2) 扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
1) 可以增加消费者的数量(注意: 最多和topic的分片数量相等, 并保证都在一个组内)2) 如果无法增加, 可以调整topic的分片数量, 以此来增加更多的消费者3) 调整消费者的消息的机制, 让其消费的更快...

kafka发送消息时,会将多条消息组成一个batch再进行批量发送,这样做的目的是可以提高kafka的吞吐量,不必每次来一条消息就进行一次网络请求,那么这些批量的消息发送出去后,必然还存在于内存中,等待的将是JVM的GC,当消息越来越多时,带来的问题就是频繁的GC,也就是会造成频繁的STW。针对上述问题,于是kafka就设计出了缓冲池的概念,kafka先将一片内存区域固定下来专门用于存放batch
Linux发行版包括Linux内核(Linux的核心源代码)、系统库和系统程序。Linuxnei'he'shi'zui'ji'chu'de'bu'fen
hive的安装1. 修改 hadoop的 core-site.xml中, 添加以下内容:#修改hadoop 配置文件 etc/hadoop/core-site.xml,加入如下配置项:<property><name>hadoop.proxyuser.root.hosts</name><value>*</value></propert
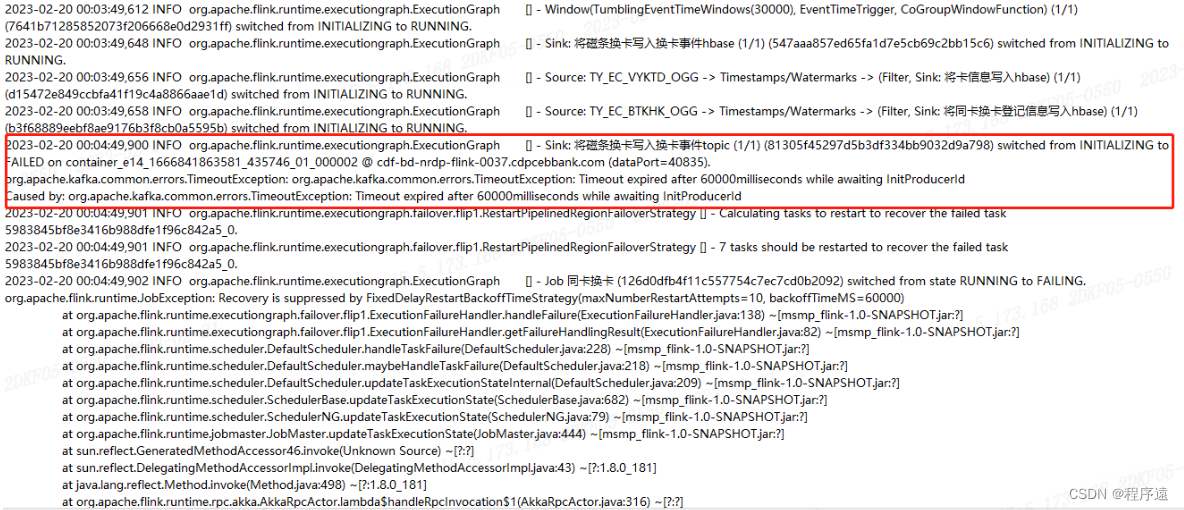
将Kafka unclean leader参数设置为true先选举出主分片,后续修改server配置,将最小ISR数量变更为2。Kafka集群有一台节点磁盘坏了,partition无法选主,导致flink任务无法写Kafka。
flush刷新机制(溢写合并机制):流程: 客户端不断将数据写入到memStore内存中, 当内存中数据达到一定阈值后, 需要将数据溢写刷新的HDFS中 形成一个storeFile文件阈值: 128M 或者 1小时 满足任意个都会触发flush机制内部详细流程: hbase 2.0架构 以上流程:1) 客户端不断向memStore中写入数据, 当memStore只数据达到阈值后, 就会启动flus
Kafka 宕机引发的高可用问题从 Kafka 部署后,系统内部使用的 Kafka 一直运行稳定,没有出现不可用的情况。但最近系统测试人员常反馈偶有 Kafka 消费者收不到消息的情况,登陆管理界面发现三个节点中有一个节点宕机挂掉了。但是按照高可用的理念,三个节点还有两个节点可用怎么就引起了整个集群的消费者都接收不到消息呢?要解决这个问题,就要从 Kafka 的高可用实现开始讲起。Kafka 的多
一、单选题如果对HBase表的添加数据记录,可以使用(C)命令进行操作。A.create B.get C.put D.scan如果需要对HBase表中的数据进行列表查看,可以使用(B)命令进行操作。A.count B.scan C.put D.get以下更新HBase表中数据的语法,输写正确的是(D)。A.update user. xiaoming’ set info.age=1B.update