- @weixin_59191169
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI行业在2026年迎来爆发式增长,企业业绩和薪资水平显著提升。文章指出,AI行业不仅限于理工科,文科生也能获得高薪职位。以AI测试为例,上海地区薪资普遍在18-60万元/年。AI行业因其高薪、低门槛和广阔前景,成为职场人转行和提升技能的热门选择。对于想进入AI领域的小白或程序员,AI测试是一个不错的切入点,具有入门友好、技能易掌握、薪资起点高等优势。2026年刚开年,聊起当下最火、最有前景的行业

从 L1 到 L5,AI Native 组织的演进不是一蹴而就的。95% 的企业还停留在 L1-L3。但 5% 的 「Future-Built」 企业已经证明:AI 原生不是未来,而是现在。它们的收入增长是其他企业的 5 倍,成本削减是 3 倍,人均收入是传统企业的 25-35 倍。差距正在扩大。窗口正在收窄。BCG 将其称为 「The Widening AI Value Gap」——AI 价值鸿

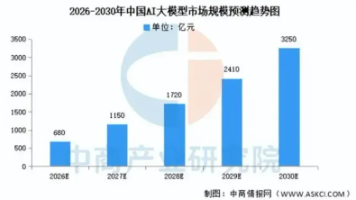
AI大模型市场正高速扩容,预计2026年将突破680亿元,2030年达3250亿元。众多企业扎堆入局,行业生态持续壮大,落地场景拓宽至各领域。AI能力成为企业和职场人的核心竞争力,掌握AI技能可提升职场竞争力、获得高薪岗位。AI大模型应用开发岗位需求暴涨,薪资待遇优厚。在AI全面普及的当下,主动学习AI技能是普通人逆袭破局的最佳机会。近几年,人工智能早已不是遥远的科技概念,而是悄悄渗透进各行各业、
最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续

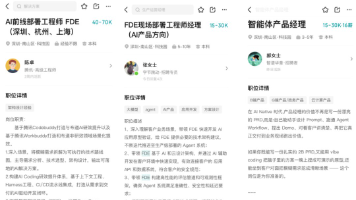
再聪明的大模型,也不懂你这公司具体的业务场景。FDE就是来解决这个问题的。它既不是纯程序员,也不是销售,更不是客服,而是一个三合一的角色:FDE = 懂技术的工程师 + 懂需求的产品经理 + 能驻场的交付专家腾讯招聘官网写得挺直白:“深入行业场景,将模糊需求拆解为可执行的技术路线图,主导需求分析、技术选型、架构设计,输出可落地的AI解决方案。上海创智学院在启动培训班时给了个更精准的说法:他们既是技
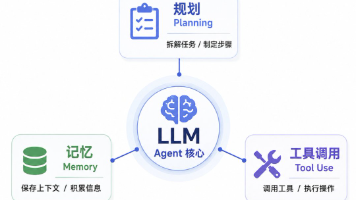
如果把前面的逻辑重新收一下,会发现这些概念根本不是平行关系。它们更像一套从下往上的 AI 产品设计结构。先从Skill开始,先沉淀能力;再用专家和专家团补足专业判断和相互协同;用Claw打通真实执行;由Agent负责任务编排;最后,才有可能长成虚拟员工。所以如果一定要再做一个更高层的总结,可以这样说:概念的本质,不是为了定义 AI,而是为了帮助产品经理决定:先做哪一层,补哪一层,最后又该往哪一层长

最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续

最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续
最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续

最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续