
写文章




- @weixin_44870066
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
大数据-------元数据管理
大数据之元数据管理
Spark job failed during runtime. Please check stacktrace for the root cause.
Spark job failed during runtime. Please check stacktrace for the root cause.
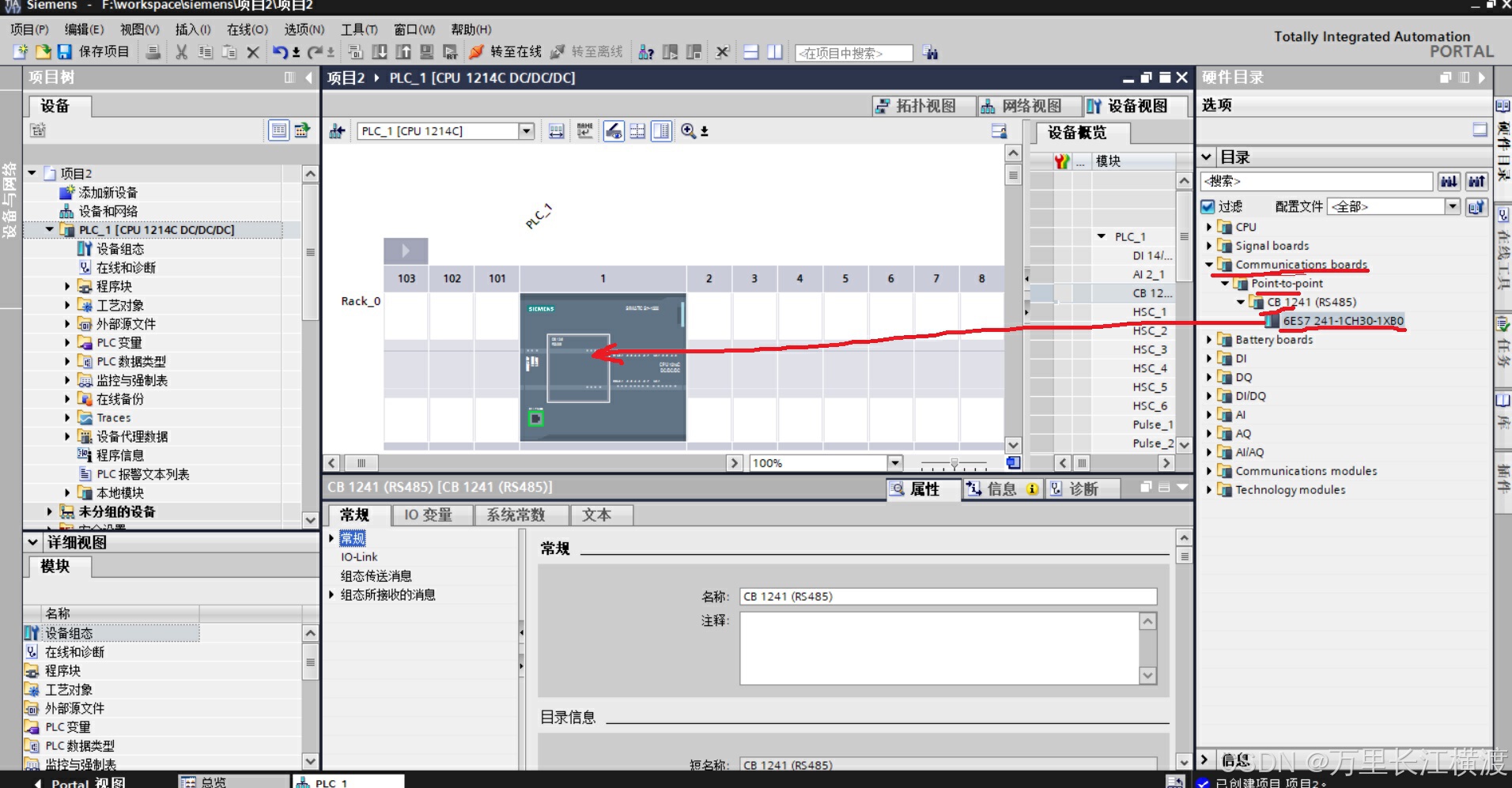
西门子1200面板的485通讯案例
4、其他常见的485口。
大数据-------元数据管理
大数据之元数据管理
Hbase集群安装
1、根据hadoop的版本选择合适的hbase版本,可参照下图本机安装的hadoop3.1.3所以选择HBASE版本为2.0.52、将hbase上传到/opt/software/文件目录,使用tart -zxvf命令解压到opt/module/中[xiong@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/3、为了
zookeeper启动失败
报错[xiong@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh startZooKeeper JMX enabled by defaultUsing config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfgStarting zookeeper ... FAILED TO START具体原因可能是以下5个
Kafka常见问题处理
Kafka常见问题处理
到底了