
写文章




- @weixin_42118737
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
学习笔记:使用Ollama项目快速本地化部署Qwen 1.5模型
本文记录了采用Ollama项目快速本地部署运行qwen1.5模型。

Ubuntu22.04本地部署qwen模型、jupyterlab开发环境、LoRA微调全流程
这段时间在自己的Win11系统上部署了chatGLM以及Qwen模型,进行对话、推理以及工具调用都没有问题,但是在尝试进行微调的时候发现好像并不能成功,因此花费了很大的力气,又分别在ubuntu桌面版、windows子系统WSL2 Ubuntu上部署了Qwen模型,并尝试进行LoRA的微调实践。由于过程比较多,步骤较为繁琐,我可能会分几个部分进行叙述。首先介绍一下我的两个环境(平民玩家,勿喷):一

通义千问Qwen 1.8B以及7B chat模型本地化部署
本文简单的记录了在本地部署阿里通义千问1.8B以及7B模型
Qwen学习笔记3:Qwen模型调用外部API实现模型增强(openai的形式)
本文进一步记录了千问模型的函数调用功能使用方法,大家可以一起学习交流~

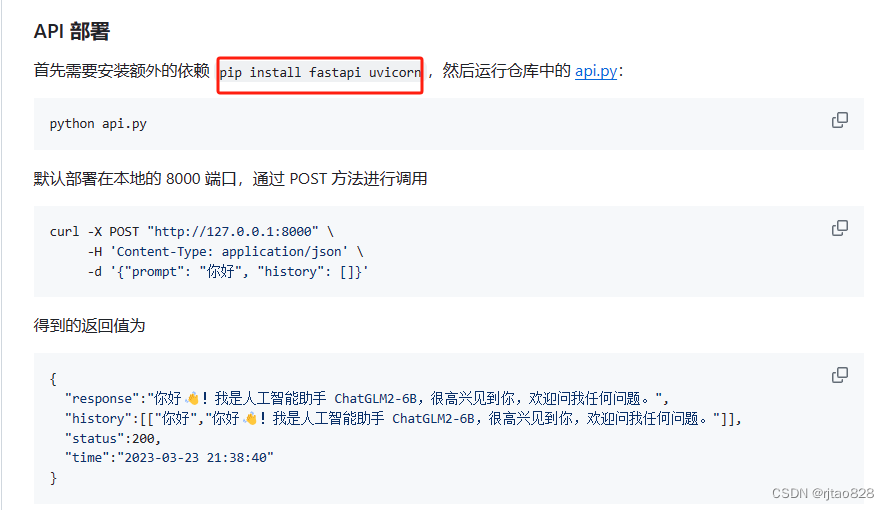
采用API的方式调用本地chatGLM2-6B,postman方式访问接口,openai格式调用接口
本文记录了采用api的方式访问本地chatGLM2-6B的方法
Qwen模型LoRA微调后的两种启动方式
本文记录了Qwen模型LoRA微调后的两种启动方式。

RAG从入门到高阶(四): 知识图谱Graph RAG
本文详细介绍了GraphRAG系统,这是一种将知识图谱与RAG框架结合的创新方法。传统RAG在处理多跳推理和深层关系时存在局限,GraphRAG通过结构化知识存储、多跳推理能力和可解释的推理路径解决了这些问题。文章系统阐述了GraphRAG的工作原理,包括知识图谱构建、查询理解与子图检索、图推理与答案生成三个阶段。完整展示了从实体关系抽取到知识图谱构建,再到子图检索和答案生成的实现代码。

windows系统jupyter lab安装和配置:本地开发、探索大模型的利器
本文介绍了jupyterlab的安装和配置。
