- @qq_42257666
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
你在 npm run serve时遇到的 “onMounted” is defined but never used错误,是一个由 ESLint 的 no-unused-vars规则触发的常见警告。它表示代码中导入了 onMounted这个函数,但在后续代码里并没有实际使用它。下面帮你梳理了问题的原因和解决方法。
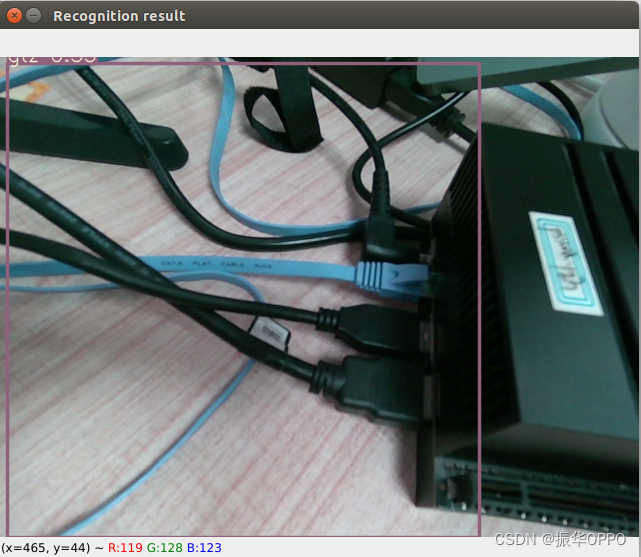
教你如何订阅yolov7发布的话题
DeepSeek大模型是由北京深度求索人工智能基础技术研究有限公司开发的一款基于Transformer架构的大型语言模型。它具备强大的自然语言理解和生成能力,能够处理多种复杂的语言任务,如智能对话、文本生成、语义理解等。DeepSeek大模型的诞生,标志着人工智能在自然语言处理领域取得了重大突破。

知识图谱不仅是人工智能的“基础设施”,更是连接数据与智慧的桥梁。从搜索引擎到产业大脑,其应用正在重塑人类与信息交互的方式。随着技术迭代与生态完善,知识图谱有望成为驱动社会智能化升级的核心引擎。我强烈推荐4本可以改变命运的经典著作《寿康宝鉴》在线阅读白话文《欲海回狂》在线阅读白话文《阴律无情》在线阅读白话文《了凡四训》在线阅读白话文。
,这表示是已编译好的二进制版本,解压即可使用。避免下载仅包含源码的版本,否则可能会遇到“找不到或无法加载主类”的错误。希望这篇详细的教程能帮助你在Windows上顺利搭建ZooKeeper环境,并迈出分布式系统实践的第一步!可以将其理解为分布式系统的“神经系统”,负责在各个组件之间传递关键信息,确保它们步调一致。ZooKeeper是基于Java开发的,因此需要先确保你的系统上已经安装了合适的。保证
我在解决另一问题的时候,重启了云服务器。当我想再次访问phpMyAdmin时,出现了如下报错。

打开侧边栏Gradle,点击offline mode,被选中有背影就是开启,否则就是关闭,我们需要保证它是关闭的。报错显示离线模式下找不到合适的tools缓存,请禁用gradle的offline mode,然后同步工程。生活需要一颗感恩的心来创造, 一颗感恩的心需要生活来滋养。再次sync,然后run,成功解决问题。
遇到的错误表明在尝试访问Java内置类 java.io.File 的私有字段 path 时出现了权限问题。这个问题通常发生在使用JDK 9及以后版本时,因为这些版本引入了模块系统,对类和接口的访问进行了更严格的控制。常用的方法是:更新Gradle版本、修改Gradle属性、降低JDK版本。这里我一般使用的是降低JDK版本,方便快捷。安装和配置好当前项目Gradle对应的Java,然后设置当前项目G

电脑C盘可用存储空间日渐下降,使用电脑管家进行清理,并且显示大文件,我发现有不少.ipch文件,而且很像之前力扣刷过的题目,然后进入目录仔细研究,发现了新大陆。
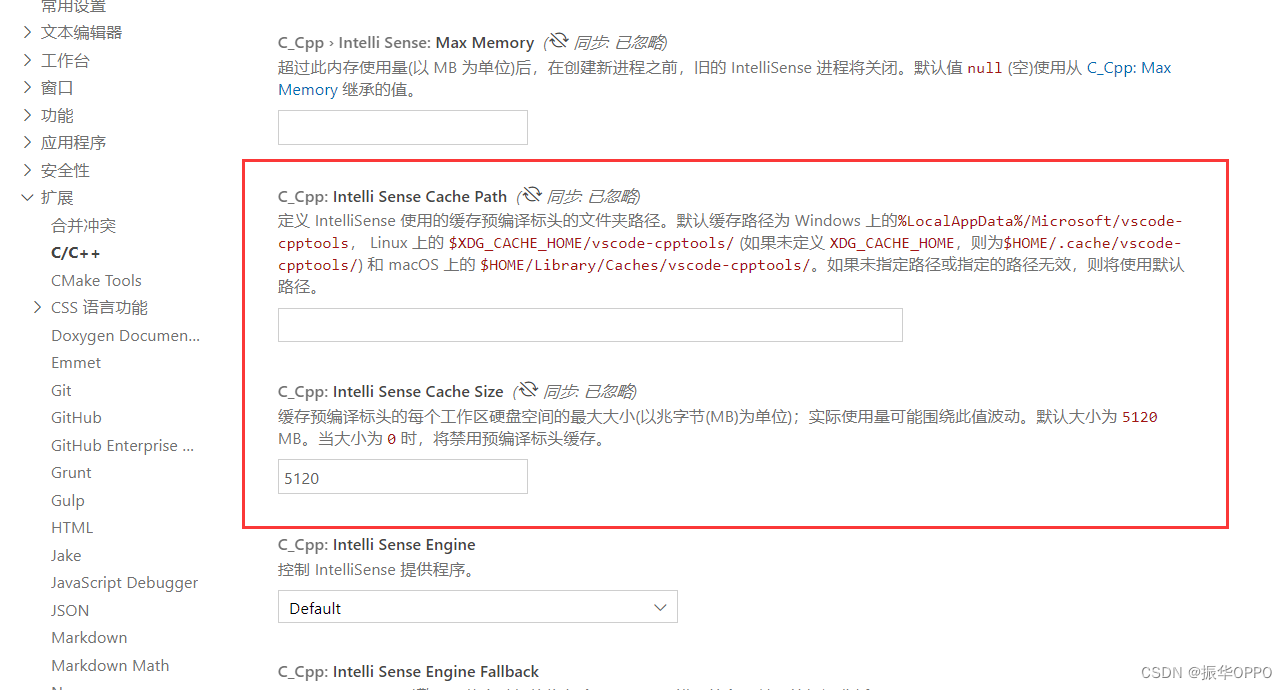
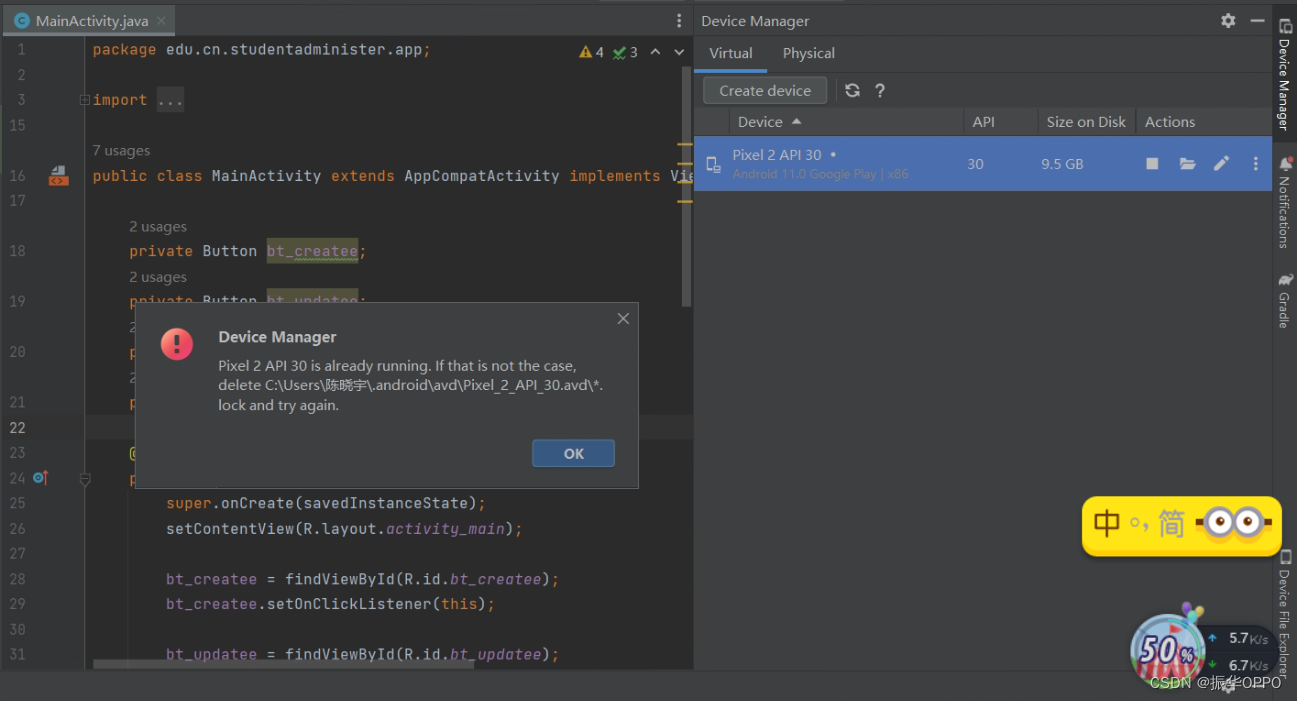
按照报错提示打开目录, 找到所有后缀名是.lock的文件夹或文件删除掉,然后再重新运行模拟器即可。