




- @qq_41964545
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
由于真实雷达图像较少,作者采用了GPR工具箱,使用不同配置,合成了部分模拟雷达图。然后采用Cifar-10数据(灰度图)对Faster RCNN进行预训练,再采用真实和合成数据进行微调。论文地址。

由于真实雷达图像较少,作者采用了GPR工具箱,使用不同配置,合成了部分模拟雷达图。然后采用Cifar-10数据(灰度图)对Faster RCNN进行预训练,再采用真实和合成数据进行微调。论文地址。
1 传统算法目标检测区域选择 -->特征提取-->特征分类1.1 区域选择 python 实现 图像滑动窗口区域选择: 区域选取:首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(SlidingWindows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。滑动窗口: 固定一个窗口,截取图片1.1.1 以滑动窗口方式切分图像import

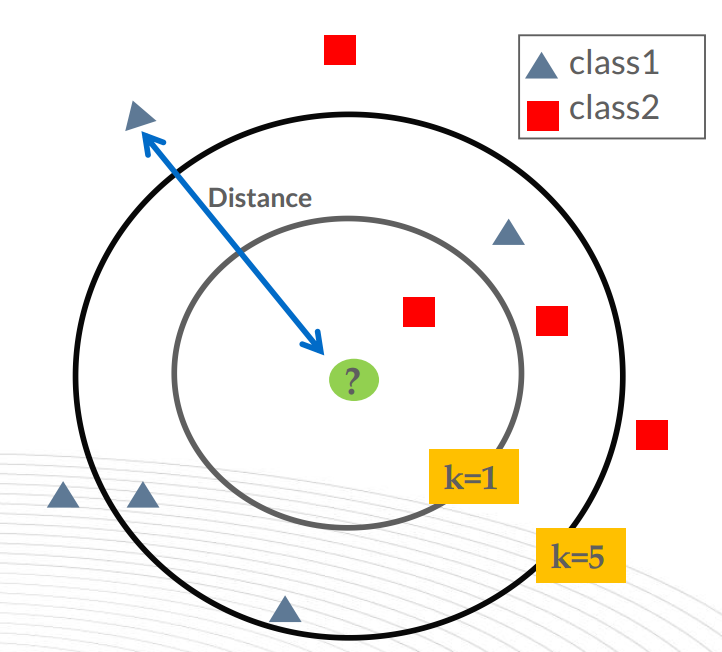
机器学习面试准备(一)KNN
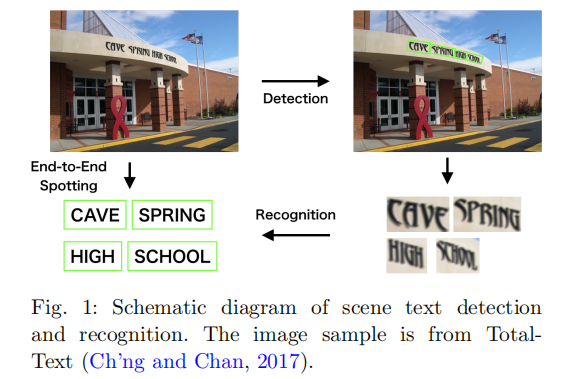
随着深度学习的兴起和发展,计算机视觉发生了巨大的变革和重塑。作为计算机视觉的一个重要研究领域,场景文本检测与识别不可避免地受到了这一革命浪潮的影响,从而进入了深度学习时代。这项调查旨在总结和分析深度学习时代场景文本检测和识别的主要变化和重大进展。通过本文,我们致力于:(1)介绍新的见解和想法;(2)突出最近的技术和基准;(3)展望未来的趋势。
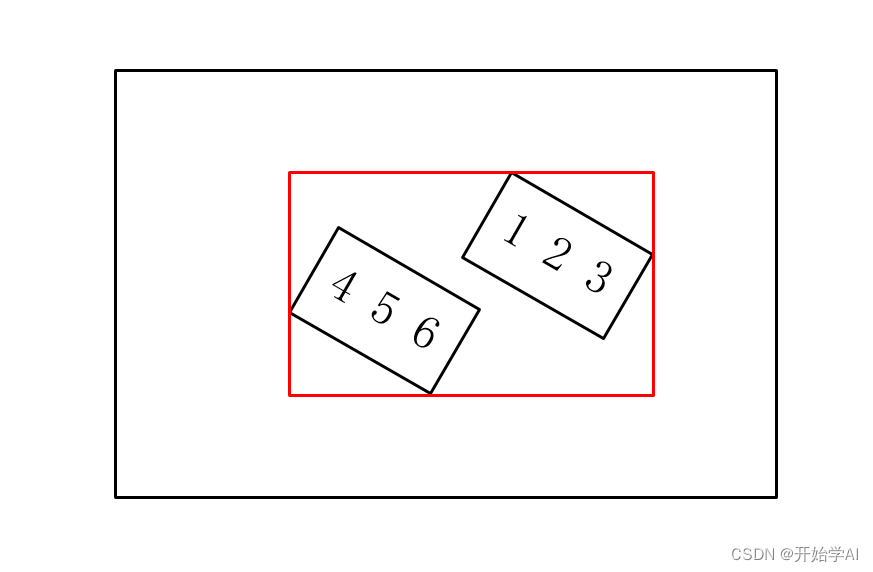
过程由于文字标注区域可以为任意四边形,为了不把文字标注区域切分成两个区域,因此首先需要得到所有标注框的最外界坐标,如下图红色框的获取过程。然后根据红色框与图像边界的距离进一步随机生成裁剪坐标,如生成蓝色虚线框的左上角与右下角坐标。随后进行区域剪裁与Bbox调整。BBox的坐标更新,只需要将原来的BBox的值减去裁剪区域的起始坐标,如减去蓝色框的起始坐标。如下:[bbox[0][0] - crop_
模型的参数越多,其复杂度就越高,能够处理的数据也越多。它们是模型从大量文本数据中学习的结果,不仅编码token的身份,还编码其与其他token的关系。反向传播、Adam 优化和 Transformer 架构,训练所需的内存通常是相同大小的 LLM 推理所需内存的 3 到 4 倍。例如,如果您需要微调大小为 1024×512 的参数,使用选择rank为 8 的 LoRA,您只需要微调以下数量的参数:
这两个指标在自然语言处理领域应用广泛,能够反映生成文本与参考文本之间的相似度,进而为文本生成质量提供客观衡量标准。其中,BLEU 侧重于文本间的匹配准确性,适用于评估生成文本在词汇和句法层面的精确性 [43];而 ROUGE 则是衡量文本覆盖度与连贯性的指标,通过 ROUGE-1、ROUGE-2 和 ROUGE-L 三个子指标,从多个层面实现综合评估 [44]。其次**,“大语言模型作为评判者”
4.在「Cursor Settings」菜单栏中点击「MCP」,然后点击「+ Add new global MCP server」按钮,会弹出一个mcp.json文件,把arxiv-mcp-server中的配置信息添加到json文件中去。5. 配置自己的API KEY,其余模型去掉。3. 下载0.47版本以上的Cursor。2. git clone 代码。将安装路径添加到环境变量。

1.4 HOG特征+支持向量机实现行人检测为了把前面知识串起来,参考书籍做了以下实验。import cv2import matplotlib.pyplot as pltfrom matplotlib import patchesimport numpy as npimport randomimport osfrom numpy.lib.shape_base import take_along_ax
