




- @qq_41520353
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
马尔科夫决策过程是基于马尔科夫过程理论的随机动态系统的最优决策过程。如果某一状态信息蕴含了所有相关的历史信息,只要当前状态可知,所有的历史信息都不再需要,即当前状态可以决定未来,则认为该状态具有马尔可夫性。凡是具有马尔可夫性的的过程都成为马尔可夫过程。马尔可夫决策过程是针对具有马尔可夫性的随机过程序贯地做出决策。一个决策过程由五元组成: ,分别表示环境的状态集合、智能体的动作集合、状态转移概率、回

本篇仅记录学习笔记。强化学习方法起源于动物心理学的相关原理,模仿人类和动物学习的试错机制,是一种通过与环境交互,学习状态到行为的映射关系,以获得最大累积期望汇报的方法。1 强化学习的主要组成智能体策略值函数模型环境强化学习、监督学习与非监督学习机器学习实际上有三大分类:监督学习、非监督学习和强化学习。2 强化学习的分类根据是否建立环境动力学的模型划分为模型方法和无模型方法。根据不同的估计方法可以把

目录重复记录的识别和处理缺失值的识别缺失值的处理办法删除法替换法插补法异常值的识别和处理基于分位数法识别异常值基于法识别异常值基于模型法识别异常值异常值的处理数据形状的重塑reshape2Tidyr包数据的聚合操作基于aggregate函数的聚合基于sqldf函数的聚合基于group_by和summarize函数的聚合数据的合并与连接基于bind_rows函数的数据合并基于*_join函数的数据

生存分析用于研究被观察对象会在何时发生某个事件的问题,例如银行业务的预测、保险及零售行业客户下次购买时间等的预测。其结果变量是一个时间点到任何感兴趣事件发生的时间。另外还有风险函数。删除数据包括左删失、右删失、区间删失,用以确定时间范围。生存分析方法使用survival包,survminer包中的ggsurvplot()函数用于绘制生存曲线。Kaplan-Meier方法适用于数据量比较小的,Sur

借一下周老师的图。决策树可以用于数值型因变量的预测和离散型因变量的分类。其中第一个难点就是节点字段的选择,究竟该以数据的哪个类型作为节点呢?节点字段的选择这里首先引入一个信息增益的概念,也就是信息熵。延伸的感念有信息熵、基尼指数,核心思想都是将数据中的根节点挑选出来。信息增益的缺点是会偏向于取值较多的字段,信息增益率就是在信息增益的基础上增加了惩罚函数。而基尼指数就是适用于预测连续性因变量。决策树

操作系统1.1 操作系统的概念包括硬件系统和软件系统操作系统特征并发性共享性随机性研究操作系统的观点从软件观点看它是个大型软件系统从资源管理的观点看负责管理资源从进程观点看它由多个程序组成从虚拟机观点看,它统称为操作系统虚拟机从服务提供者观点看,它是服务提供者操作系统的功能进程管理:进程控制、同步、进程间通信、调度存储管理:内存分配与回收、存储保护、内存扩充文件管理:存储空间管理、目录管理、文件系

目录介绍稀疏自编码器实例:编码器实现输入参数的重构堆叠自编码器实例:堆叠编码器去噪自编码器实例:去噪自编码器介绍自编码器是一种无监督三层特征学习前馈神经网络。输入层的节点数等于输出层的节点数,隐藏层的节点数少于(或多于)输入层节点数。自编码器的目的不是在给定输入x的情况下预测目标值y,而是对输入x进行重构。一个自编码器就是一个尝试对输入数据进行重现的人工神经网络,输出的目的就是输入。自编码器是一个
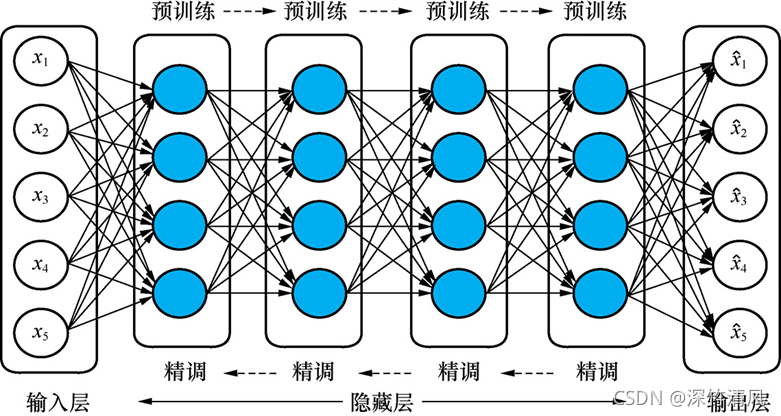
pytorch前身是Torch,Torch使用Lua和C语言,而后因为python的兴起,演变成为PyTorch。事实上,pytorch是提供动态图功能的chainer分支。pytorch与2017年发布。基于磁带的自动求导系统使Pytorch具有动态图功能。关于磁带:https://blog.csdn.net/qq_37289115/article/details/109206099通过演化,人

在生活中用Word的次数当然相当多,域代码只要是学过OFFICE计算机二级,或者是参加过一些高要求的排版,比如“第几页”、“共几页”时候接触过。诚然,这也是它最为重要的功能之一。而笔者不甘于此,想把Word域代码学习的透彻一下,因此将学习内容进行一个展示总结。1 域代码简介百度百科说:Microsoft Word 中的域用作文档中可能会更改的数据的占位符,并用于在邮件合并文档中创建套用信函和标签。
总之 大数据分析现在已经存在于方方面面。但事实上,其首次提出仅仅是20世纪90年代,而直到2011年6月,美国麦肯锡全球研究院发布了题为《大数据:下一个创新、竞争和生产力的前沿》的研究报告,“大数据(BIG DATA)”一词才真正“热”起来。
