




- @qq_38951259
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
之前被各大平台封到怀疑人生,到一套工作流打通 TikTok、LinkedIn多平台采集,不需要再为每个网站单独写一套爬虫,也无需操心代理池和验证码。Dify Workflow 替代多套独立爬虫,Bright Data MCP 帮我搞定所有封锁问题。立即免费注册 Bright Data,可以免费获取$20额度,5 分钟内搭建你的多平台数据采集流水线,只为成功采集的数据付费。# 前言。
文章摘要: 本文通过家电卖场智能屏的三种交互体验对比,提出AI正从"文本交互"向"具身交互"演进的核心观点。作者指出,线下场景需要具备实时反馈、多模态表达的拟人化交互能力,而魔珐星云作为具身交互智能开放平台,通过自研参数流技术解决了传统方案延迟高、无法打断的痛点。文章以搭建门店导购智能体为例,演示了10分钟配置3D形象、SDK接入的实操流程,并对比测试显示:具身智能体支持实时打断、多通道反馈,其眼

本文中介绍的工具类型会跟前面几篇介绍的某些类型重复,本文是做对内置的工具类型做一个总结。

随着人工智能技术的不断演进,多模态大模型已是当下比较热的研究方向,它可以同时理解和生成多种输入和输出模态,如文本、图像、语音等,能够更好地模拟人类的多感知能力,给文档图像的分析处理带来了新的机遇和挑战!近期,中国模式识别与计算机视觉大会在厦门举办,是国内顶级的模式识别和计算机视觉领域学术盛会。大会汇聚了国内国外模式识别和计算机视觉理论与应用研究的广大科研工作者及工业界同行,分享我国模式识别与计算机

近几年来,随着互联网技术的不断发展,办公使用的文档处理软件在市场上也是很多。比较熟悉就是Microsoft Office 和 WPS,但是 Microsoft Office 需要付费才能使用,国内破解方法也比较麻烦,搞不好电脑就直接瘫痪,而WPS的广告满天飞。直到我遇见了`ONLYOFFICE`,让我相见恨晚啊!

从前期需求拆解、选定目标网站,再靠 AI Agent 一键生成爬虫代码,IDE 精细化调试,配置分页、多阶段分层抓取,设置定时自动调度,最后对接 S3 存储、Webhook 实现数据自动推送,以及 Self-Healing 自愈机制,解决网站改版爬虫直接报废的痛点,整套端到端流程一次性完整演示。很多做开发、数据分析的朋友都只会写零散单页爬虫,一碰到全链路采集、定时任务、网站反爬改版就束手无策。今天

从前期需求拆解、选定目标网站,再靠 AI Agent 一键生成爬虫代码,IDE 精细化调试,配置分页、多阶段分层抓取,设置定时自动调度,最后对接 S3 存储、Webhook 实现数据自动推送,以及 Self-Healing 自愈机制,解决网站改版爬虫直接报废的痛点,整套端到端流程一次性完整演示。很多做开发、数据分析的朋友都只会写零散单页爬虫,一碰到全链路采集、定时任务、网站反爬改版就束手无策。今天
从前期需求拆解、选定目标网站,再靠 AI Agent 一键生成爬虫代码,IDE 精细化调试,配置分页、多阶段分层抓取,设置定时自动调度,最后对接 S3 存储、Webhook 实现数据自动推送,以及 Self-Healing 自愈机制,解决网站改版爬虫直接报废的痛点,整套端到端流程一次性完整演示。很多做开发、数据分析的朋友都只会写零散单页爬虫,一碰到全链路采集、定时任务、网站反爬改版就束手无策。今天
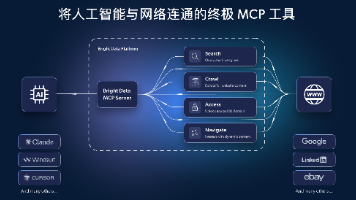
以前要做跨平台商品比价,要么自己写爬虫、租代理、折腾反爬,要么维护好几套脚本累死人。各平台经常改版,光修解析就能把人耗光。自建爬虫的成本不在“写代码”,而在“长期维护反爬”。Bright Data + MCP 的价值在于:把最难、最不稳定的部分(代理、解锁、解析)完全外包,让你只关注数据本身。接入:专门做采集的基础设施,反爬、代理、解析全交给它,你只管拿结果。配一个 Skill(SKILL.md)
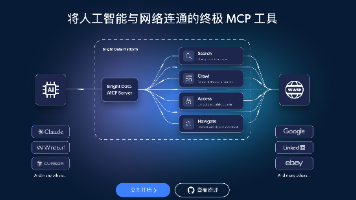
大模型存在知识滞后、信息封闭的短板,无法自主获取互联网实时内容与垂直行业数据,而大模型数据抓取器能够智能突破网页反爬限制,高效采集、清洗并结构化全网优质文本、资讯、行业资料等内容,为 RAG 知识库搭建、模型微调训练、实时信息问答与行业舆情监测提供高质量数据源,补齐大模型联网能力,提升回答准确性、时效性与专业度,是 AI 落地应用不可或缺的核心工具。
