- @qq_31412425
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
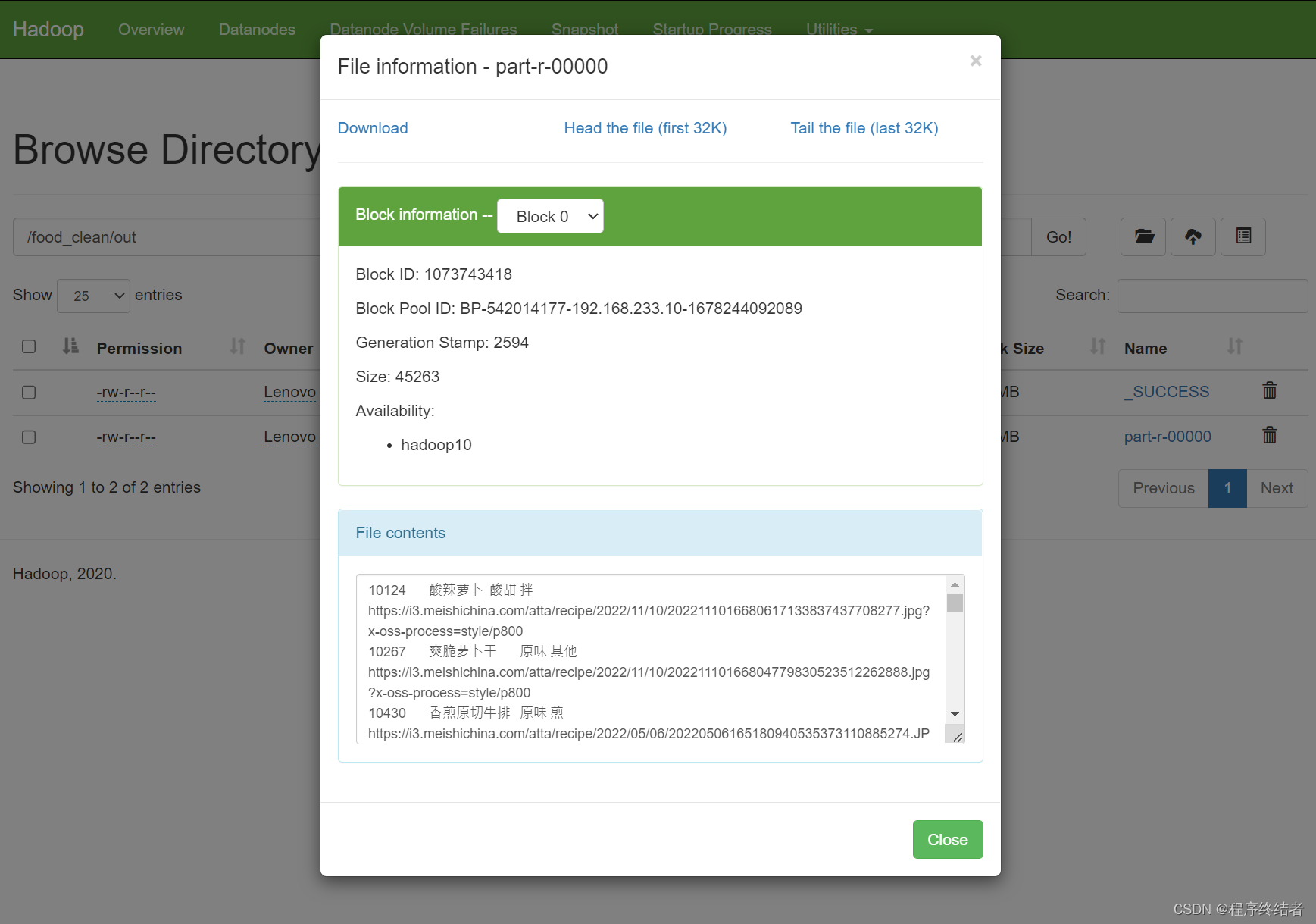
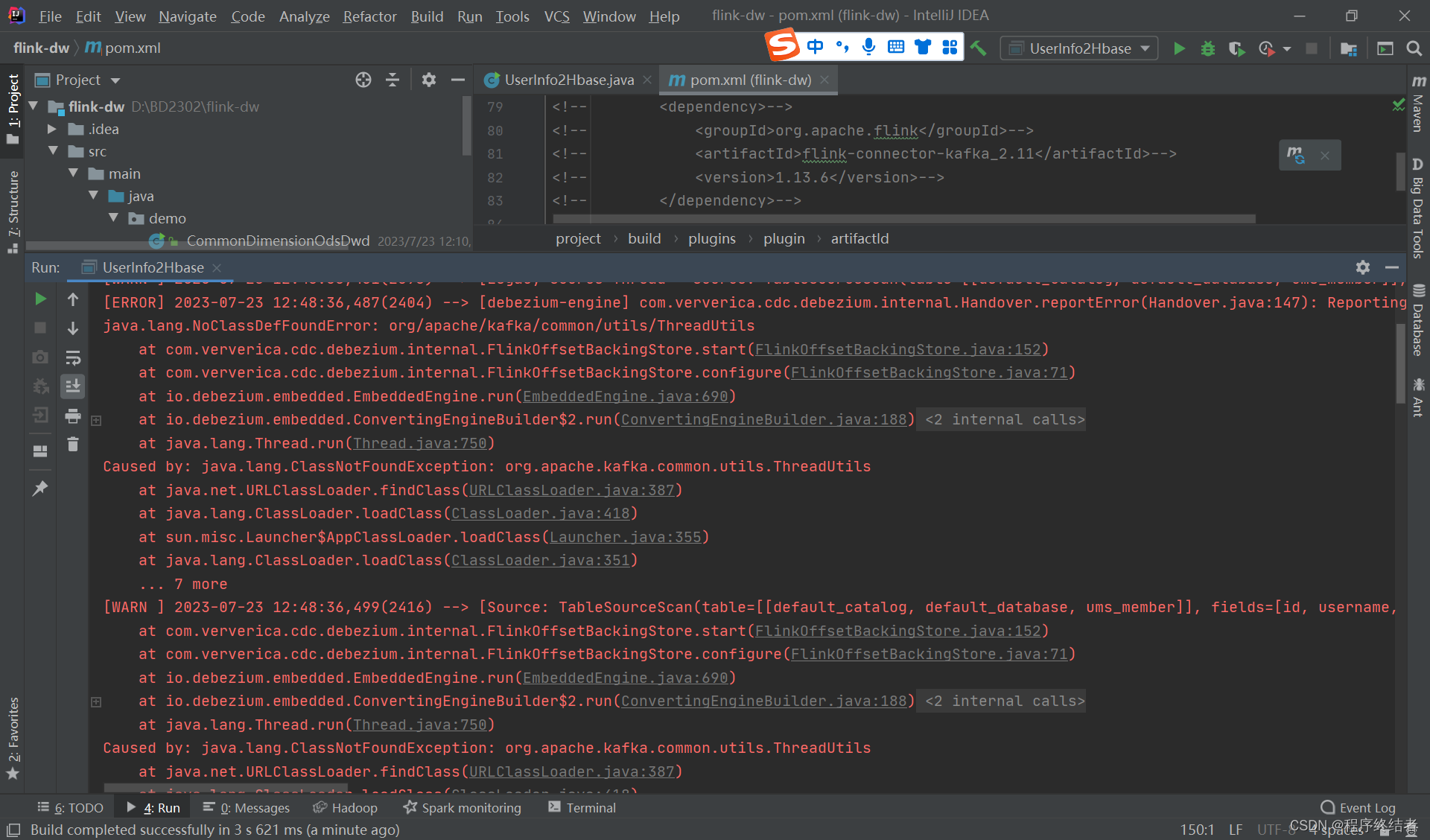
书接上文 【Flink实时数仓】需求一:用户属性维表处理-Flink CDC 连接 MySQL 至 Hbase 实验及报错分析http://t.csdn.cn/bk96r我隔了一天跑Hbase中的数据,发现kafka报错,但是kafka在这个代码段中并没有使用,原因就是我在今天的其他项目中添加的kafka依赖导致了冲突。
本文记录了在离线环境下手动部署CDH客户端(Gateway角色)的操作流程。采用三节点架构:cluster-1作为Server+Agent节点,cluster-2和cluster-3作为Agent节点。主要完成两个关键步骤:1)将CDH 6.3.2的Parcel文件分发到各节点并解压部署,创建符号链接;2)从CM Server收集配置文件并分发到各节点。操作通过容器内文件提取、SCP分发和手动解压
macOS(M系列芯片)2026年2月本文涵盖 OpenClaw、Gemini CLI、Claude Code 三款主流 AI CLI 工具的安装、配置与调试。
Node.js:wiki.js需要Node.js版本16.0.0或更高。Web服务器:wiki.js需要一个Web服务器来托管wiki页面。常用的Web服务器包括Apache、Nginx和IIS。数据库:wiki.js支持多种数据库,包括PostgreSQL、MySQL、MariaDB和SQLite。

macOS(M系列芯片)2026年2月本文涵盖 OpenClaw、Gemini CLI、Claude Code 三款主流 AI CLI 工具的安装、配置与调试。
本文记录了在离线环境下手动部署CDH客户端(Gateway角色)的操作流程。采用三节点架构:cluster-1作为Server+Agent节点,cluster-2和cluster-3作为Agent节点。主要完成两个关键步骤:1)将CDH 6.3.2的Parcel文件分发到各节点并解压部署,创建符号链接;2)从CM Server收集配置文件并分发到各节点。操作通过容器内文件提取、SCP分发和手动解压
将Kafka中的数据消费到Hive可以通过以下简单而稳定的步骤来实现。这里假设的数据是以字符串格式存储在Kafka中的。创建Hive表:编写Kafka消费者脚本:Hive JDBC客户端:运行消费者脚本:这是一个基本的、简单的方式来实现从Kafka到Hive的数据流。这里的示例假设数据是以逗号分隔的字符串,实际上,需要根据数据格式进行相应的解析。这是一个简化的示例,真实场景中可能需要更多的配置和优

一、数据采集清洗1.1 爬虫采集import requestsfrom bs4 import BeautifulSouphead = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',}