




- @qq_20949471
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
低代码开发基于可视化和模型驱动的概念,结合了云原生和多终端体验技术,它可以在大多数业务场景中,帮助企业显著的提升效率,还能进一步降低企业开发成本,也就是我们所说的“降本增效”,为专业开发者提供了一种全新的高生产力开发方式;从某种意义上说,低代码可以弥补日益扩大的专业技术人才缺口,同时也可以促进企业与技术之间深度协作的最终敏捷形式。L“追求少的代码量,完成最多的开发工作”,不管是开发代码的工具还是代

有Sqoop和DataX之类数据处理为何还要用Apache SeaTunnel,这就要得益于Apache SeaTunnel依赖Flink和Spark天然分布式处理数据的特性,前两者是单机同步数据不适于海量数据同步,以低代码方式用配置文件就可以启动Flink数据处理应用,本篇从基本概念和原理入手,并通过部署SeaTunnel演示了多个基于Flink的Source和Sink配置,基本掌握如何编写配置

数据安全是大数据产业的发展基石,更是国家安全重要保障;信息化发展是一个新机遇,政府数据的开放共享和数据壁垒的打通,推动双循环发展的新机遇,复杂多变的国际形势让我国科技创新、新型基础设施建设和自主可控关键技术发展迎来新的发展机遇,随着坚定的发展脚步,5G、AI、工业互联网等将改变整个社会实现智能化;其次,目前网络安全形势十分严峻,网络攻击、数据贩卖、技术防范弱、自然灾害等问题大量存在,需要从产品和服

数据化已经贯穿经济社会发展的全领域、多层级,成为国家治理经济发展和社会运行的核心驱动力,而数据作为新的生产要素的核心定位也成为数据化过程中最关键的驱动力,国家发展数据化经济提出更高的要求,数据治理先行同步统筹安全和发展,其中以数据安全治理为核心的数据安全能力框架2.0和零信任身份安全解决方案动态细粒度访问控制能力和业务应用控制相结合,实现对数据流转的精准控制,做到主体的数字身份可信,行为操作合规以

在Go的Web开发世界中,Gin以其简单、高性能一举成为使用最广泛的框架;本篇先了解定位和特性,然后在进行常见使用功能如参数获取和绑定、路由组、中间件、静态资源使用、内容渲染、Cookie和Session等多个代码示例演示,最后通过分析源码中的核心流程和数据结构加深对其整体理解。

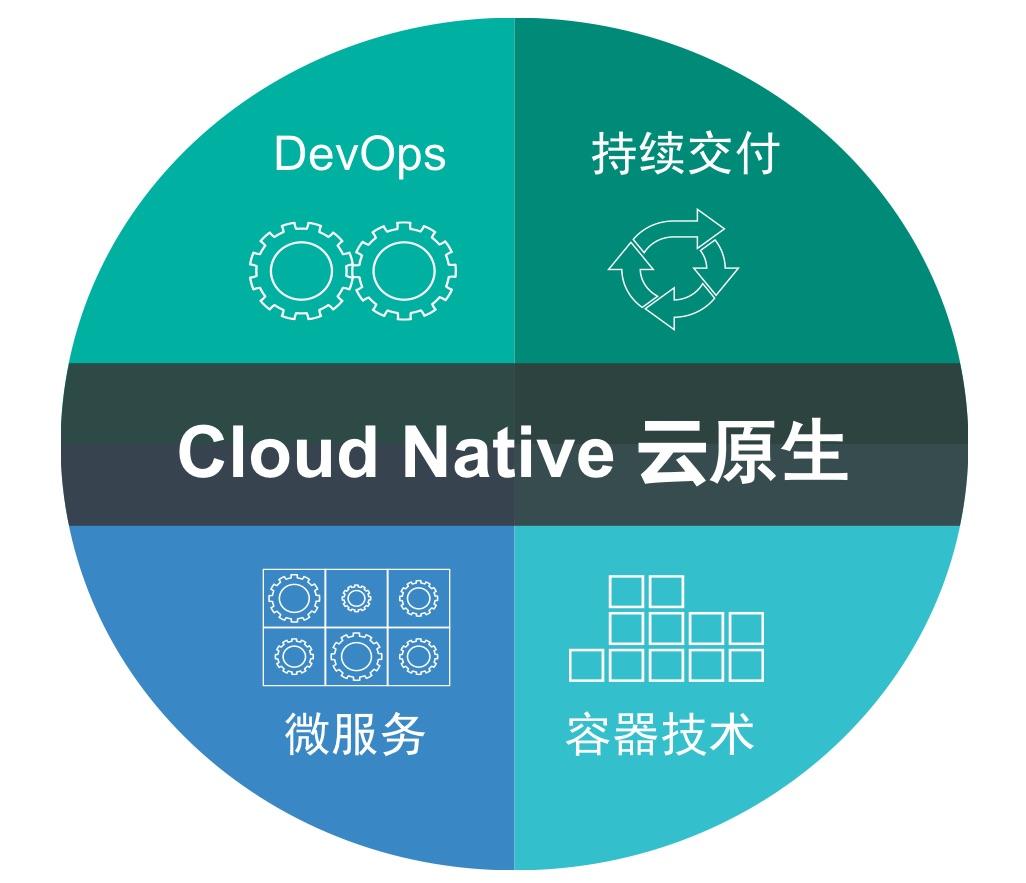
CNCF-云原生计算基金会,2015年由谷歌牵头成立,充分利用云的分布式和弹性特点,Cloud Native云原生应用的三大特征。容器化封装、动态管理:通过集中式的编排调度系统来动态的管理和调度。面向微服务:明确服务间的依赖,互相解耦。云原生以容器、微服务、DevOps等技术为基础为代表的敏捷基础架构组成,用于帮助企业快速、持续、可靠、规模化的交付业务软件,云原生需要考虑是从开发-测试-运维一体化
Pulsar即可以支持queue模式的消息中间件比如RabbitMQ和RocketMQ,也可以支持stream流模式的Kafka,几乎涵盖消息应用的领域,加上丰富企业特性如多租户隔离、百万级Topics、跨地域复制、鉴权认证,是云原生时代其他消息中间件的演化或者说是替代品也不为过

不用再担心SpringBoot启动慢和内存占用大的困惑了,为K8S云原生Quarkus轻松实现快、省、灵活的特性,本篇了解Quarkus优势和性能,并从quarkus工程创建开始,实现简单编码、普通jar打包、打包二进制文件和可跨平台直接运行二进制文件,并制作成docker镜像运行验证。

云原生时代作为程序猿心怀好奇学习了Kubernetes从此对其不再陌生,本篇以kubeadm方式快速部署3台服务器v1.22.1版本的K8S集群,从部署规划到部署步骤一步步详细记录和说明,遇到问题逐个解决,并练习K8S常用的命令,通过Nginx部署及其快速扩缩容、基于yaml文件部署、容器DNS功能,而关于K8Sconfigmap、secrets、有状态应用、高可用k8s集群、helm以及基于微服

从监控基础理论简单谈起,部署Prometheus的两种数据采集exporter和pushgateway,并通过相应采集示例演示,通过一个对CPU监控采集和图形展示的示例了解到Prometheus强大数学支持,最后通过部署grafana实现一个抓取TCP waiting_connection美观的可视化展示。.........
