




- @qq_16803227
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
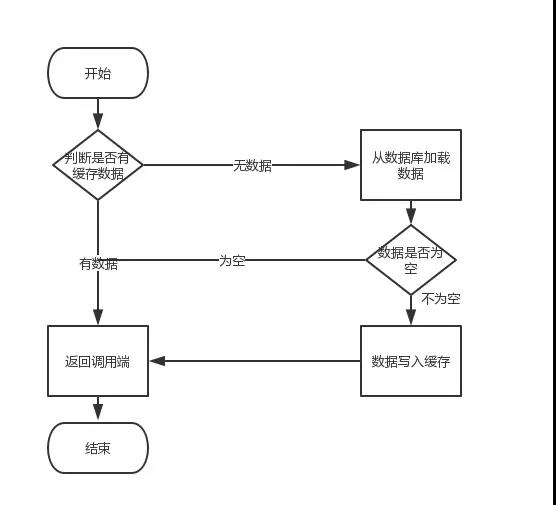
首先,缓存由于其高并发和高性能的特性,已经在项目中被广泛使用。在读取缓存方面,大家没啥疑问,都是按照下图的流程来进行业务操作。但是在更新缓存方面,对于更新完数据库,是更新缓存呢,还是删除缓存。又或者是先删除缓存,再更新数据库,其实大家存在很大的争议。目前没有一篇全面的博客,对这几种方案进行解析。于是博主战战兢兢,顶着被大家喷的风险,写了这篇文章。文章结构本文由以下三个部分组成1、讲解缓存更新策略2
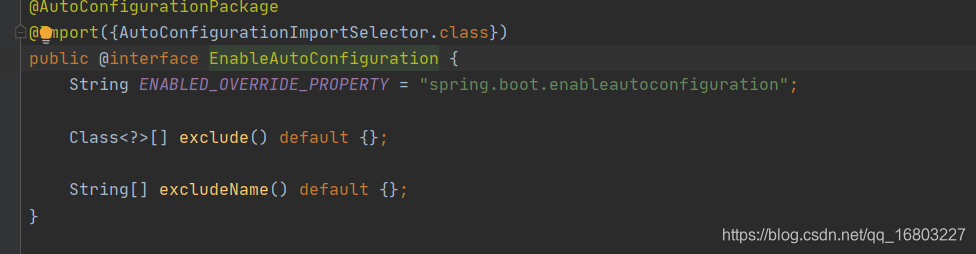
所谓自动配置那么就应该分成两步;一、自动;二、配置一、springboot如何实现自动springboot其实就是对spring的二次开发,能够实现自动主要是因为注解@EnableAutoConfiguration;注解中使用了@Import({AutoConfigurationImportSelector.class});AutoConfigurationImportSelector中又实现了D
数据是以分区目录的形式组织的,每个分区独立分开存储.这种形式,查询数据时,可以有效的跳过无用的数据文件。

容器 vs 虚拟机。

学习了好久的spring源码,成果总结一下,不一定全对,都是自己研究的//一、创建一个srping容器,并放置几个核心的 Processor CommonAnnotationProcessor AutowiredAnnotationProcessorAnnotationConfigApplicationContext annotationConfigApplicationContext =...

kubernetes中资源可以使用YAML描述(如果您对YAML格式不了解,可以参考),也可以使用JSON。

例如有一个Deployment控制有3个Pod,每个Pod的CPU使用率是70%、50%、90%,而HPA中配置的期望值是50%,计算期望副本数=(70 + 50 + 90)/50 = 4.2,向上取整得到5,即期望副本数就是5。可以看到,TARGETS的期望值是70%,而实际是0%,这就意味着HPA会做出缩容动作,期望副本数量=(0+0+0+0)/70=0,但是由于最小副本数为1,所以Pod数量

方便实现服务发现,伸缩自愈等功能。
容器 vs 虚拟机。
查询集群所有资源的详细信息,resource包括集群节点、运行的Pod、Deployment、Service等。
