- @master_hunter
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
亚马逊云科技免费套餐2025年7月迎来重大调整,从12个月免费改为6个月+最高$200抵扣金的新模式。本文以智能客服问答系统为例,展示如何在新套餐周期内完成部署:采用RAG架构,整合EC2、RDS、S3、Bedrock等服务,提供RESTAPI接口,实现FAQ检索与大模型语义回答。新套餐通过任务奖励机制引导用户熟悉核心服务,更适合短期PoC项目验证,$200额度可覆盖基础云资源成本。系统部署后需关
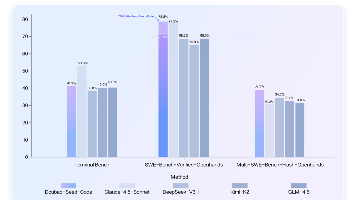
国产编程模型Doubao-Seed-Code实现了突破性进展,能够直接根据UI设计稿生成代码,大幅提升开发效率。该模型支持256K长上下文和视觉理解能力,可处理复杂编程场景,并已在多项权威评测中表现优异。实际测试显示,它能准确还原设计稿细节,合理规划项目结构,并具备安全意识和工程思维,生成可直接运行的代码。相比Claude等国外模型,Doubao-Seed-Code成本更低,在前端开发等场景中展现
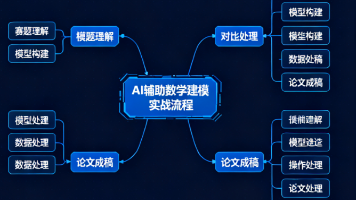
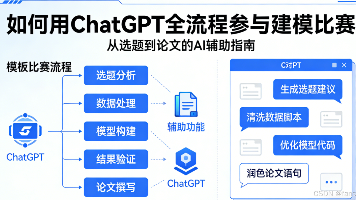
本篇文章会带你走一遍完整的实战流程,从赛题理解、模型构建、数据处理到论文成稿,每一步告诉你如何更好使用AI,如何配合它、质疑它,最终用它来构建一个值得评委信服的解决方案。因此,AI 的价值,不在于替人做决定,而在于让学生有更多时间去考虑“为什么这样建模”、 “结果说明了什么”、 “是否符合实际问题的数学结构”。如果你参加过建模比赛,你就一定懂那个时刻:拿到题的第一天,大家兴致勃勃,“一小时搞清模型
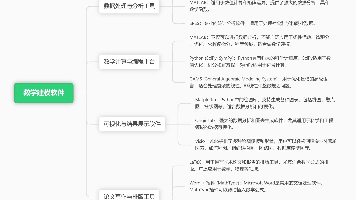
本文系统介绍了数学建模竞赛中常用的核心软件工具链,涵盖数据处理、数学计算、可视化和论文排版四大类工具。重点推荐Anaconda(含Pandas等库)、MATLAB、SPSS等专业数据处理工具;LINGO优化求解器;Matplotlib可视化工具;以及CTeX、TeXLive等学术排版系统。作者结合五年建模经验,详细阐述各工具的功能特点、适用场景及优势,帮助初学者快速搭建高效的建模环境。文中所有推荐
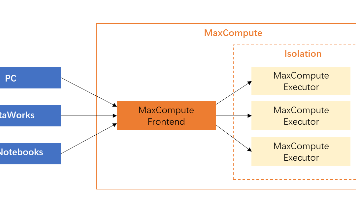
数据准备:从公共数据集中获取数据,并进行数据清洗和特征工程处理,将数据转化为适合机器学习算法处理的格式。创建SageMaker Notebook实例:通过AWS Management Console或AWS SDK创建SageMaker Notebook实例,并连接到实例。编写代码:在Notebook中编写代码,使用Amazon SageMaker提供的XGBoost算法和数据输入通道,加载并处理
以前我们用 Excel,但随着业务扩展,销售数据从几千行变成几十万行,Excel 已经明显吃不消,打开都卡。公司没有预算去买很贵的 BI 工具,于是我开始尝试看看能不能用 AWS 免费套餐搭一个简易的数据分析平台。刚好 AWS 在 2025 年 7 月调整了免费套餐政策(6 个月 + $200 Credit),对我们这种想快速验证方案的团队来说再合适不过。在实际业务运营中,很多中小企业都面临一个相
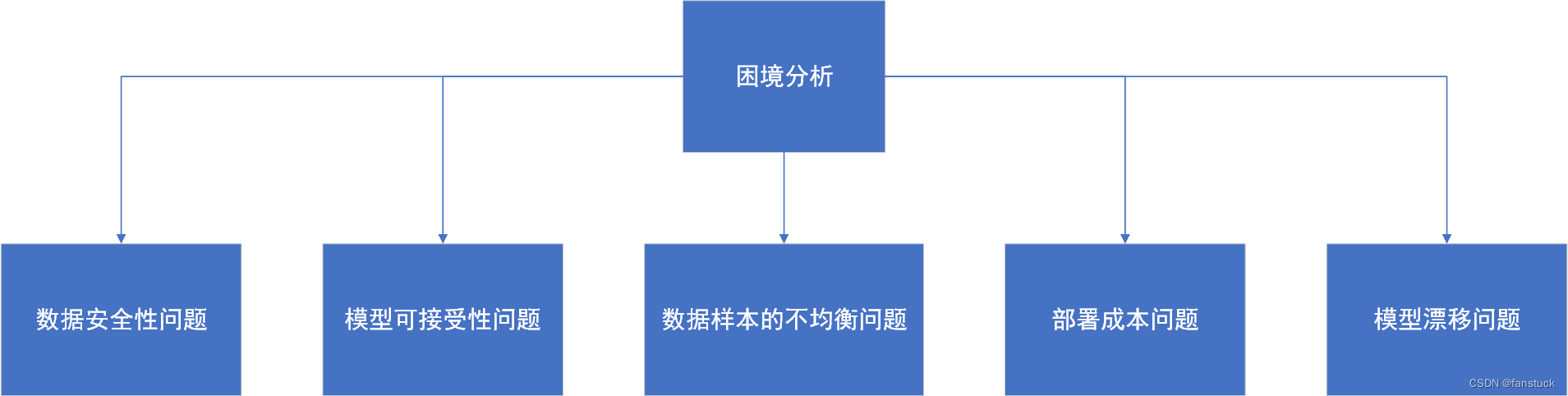
> 真正让我们愿意信任 AI 的,是在赛题刚发布时,它比我们更冷静。我们参加的是 2023 年 MCM 比赛,当时拿到的题目是关于**多地点服务设施的最优选址问题**(E 题)。刚看完题目的时候,我们脑子里全是关键词:- 多目标优化?NP 难问题?- 该不该建模成线性规划?还是遗传算法?- 这是不是那个 Facility Location Problem 的改版?但是经验告诉我们,一旦直接跳模型,
package]name = "my-awesome-lib" # 修改为你的库名version = "0.1.0" # 设置初始版本description = "一个很棒的仓颉库" # 描述你的库cjc-version = "1.0.3" # 根据需要调整编译器版本output-type = "static_library" # 通常三方库设置为 static_library 或 dynamic
总而言之,针对机器学习训练任务选择适当的云服务器配置,对初创企业来说是平衡效率、成本和未来扩展的关键举措。通过分析任务规模和资源瓶颈,团队可以确定所需的 vCPU 核数、内存容量、GPU 数量、网络带宽以及存储方案,从而以最小的投入获得满足训练需求的性能表现。同时,充分利用亚马逊云科技等领先云平台的工具(如 SageMaker、CloudWatch)和优惠政策,可进一步降低探索 AI 创新的门槛。