




- @m0_52448367
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
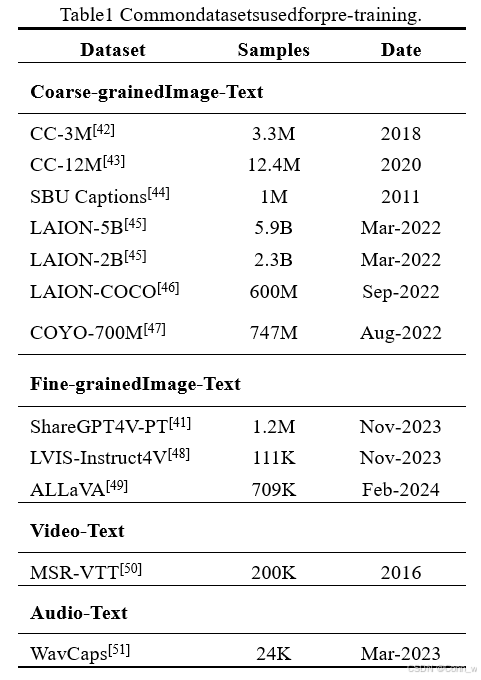
本文综述了多模态大型语言模型(MLLMs)的最新进展,探讨了其基本架构、训练策略、评估方法以及面临的挑战和未来研究方向。MLLMs结合了大型语言模型(LLMs)和大型视觉模型(LVMs)的优势,通过模态编码器、预训练LLM和模态接口实现多模态信息的接收、推理和输出。文章强调了MLLMs在细粒度支持、模态支持、语言支持和特定场景应用方面的扩展。同时,指出了MLLMs在处理长上下文信息、遵循复杂指令、
(8)利用拉普拉斯算子,对图1的输出图像进行锐化, ,使用掩膜 ,得到锐化后的新图,可以明显看出人物的轮廓像是被描粗了一遍,比平滑后的图像更为明显,人物与原图效果较为接近。2、了解了图像空域和频域图像增强方法,理解并掌握常用平滑和锐化方法,了解了空域和频域的滤波方法实现平滑处理和锐化处理,对理解并掌握常用平滑和锐化方法有了更深的认识。均值滤波是线性滤波器。在频域空间中也可以设置滤波器,常用的平滑滤

之后,根据图像边界的周长,判断哪些圆是互相接触的,哪些圆没有互相接触。根据图像的边界,可以根据图像边界的周长判断哪些圆是独立的,哪些圆是与另外的圆互相连通的。(7)利用形态学算法提取出只包含边界接触的圆时,先提取出这些圆的边界信息,利用边界的周长信息判断哪些连通域属于不同的圆连通在了一起,并认为周长大于等于200的连通域属于不同的圆连通在了一起。形态学的闭操作就是用结构元素对原图像先进行膨胀操作,

从上述结果可知,针对14个城市的TSP问题,粒子群优化算法求解得出的最短路径值为42.0138。粒子群算法是基于概率的随机自搜索算法,同遗传算法一样都是不稳定的,每次的搜索结果都不尽相同。需要不断修改粒子群大小与演化次数来获取最优值。但是,每次运行的结果不会相差很大,最短距离基本都在42-45之间,上面仅给出了四次结果。粒子群算法在计算最优解会出现陷入局部最优的情况,但是它的运行效率高,在实际的应
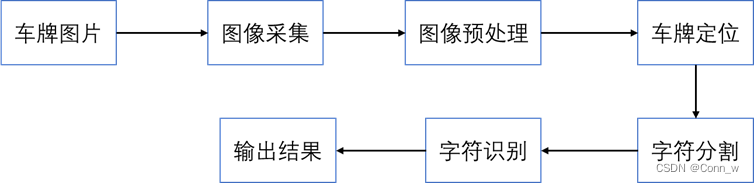
本文主要解决了以下问题:1、在背景的图像中如何定位牌照;2、将定位的牌照区域中的字符分割;3、对分割下来的牌照字符提取具有分类能力的特征,并对汉字、字母及数字均进行识别。在车辆牌照字符识别系统的研究领域,近几年出现了许多切实可行的识别技术和方法,从这些新技术和方法中可以看到:单一的预处理和识别技术都无法达到理想的结果,多种方法的有机结合才能使系统有效识别能力提高。在本系统的设计时,也汲取了以上一些
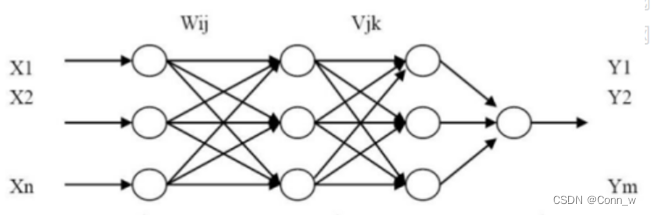
用BP算法训练单隐层前馈神经网络,实现对Iris数据分类。
其中,c是一个常数,f是浮点数。对数变换可以将图像的低灰度值部分扩展,显示出低灰度部分更多的细节,将其高灰度值部分压缩,减少高灰度值部分的细节,从而达到图像偏暗的图像增强的目的,其逆变换可以强调高灰度。图像的对数变换主要的作用是压缩动态范围,原因是对数曲线在像素值较低的区域斜率大,在像素值较高的区域斜率较小,所以图像经过对数变换后,较暗区域的对比度将有所提升,所以就可以增强图像的暗部细节。当 ga
本文综述了多模态大型语言模型(MLLMs)的最新进展,探讨了其基本架构、训练策略、评估方法以及面临的挑战和未来研究方向。MLLMs结合了大型语言模型(LLMs)和大型视觉模型(LVMs)的优势,通过模态编码器、预训练LLM和模态接口实现多模态信息的接收、推理和输出。文章强调了MLLMs在细粒度支持、模态支持、语言支持和特定场景应用方面的扩展。同时,指出了MLLMs在处理长上下文信息、遵循复杂指令、
通过本次数据挖掘的K-means聚类算法实验,了解了k-means算法的实现过程及基本方法。k-means算法的优点为原理易懂、易于实现,当簇间的区别较明显时,聚类效果较好。缺点为当样本集规模大时,收敛速度会变慢;对孤立点数据敏感,少量噪声就会对平均值造成较大影响;k的取值十分关键,对不同数据集,k选择没有参考性,需要大量实验。
