




- @m0_52049033
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
介绍了卷积神经网络各层的设计、卷积的概念、卷积神经网络反向传播的计算步骤以及使用pytorch实现卷积神经网络的代码。
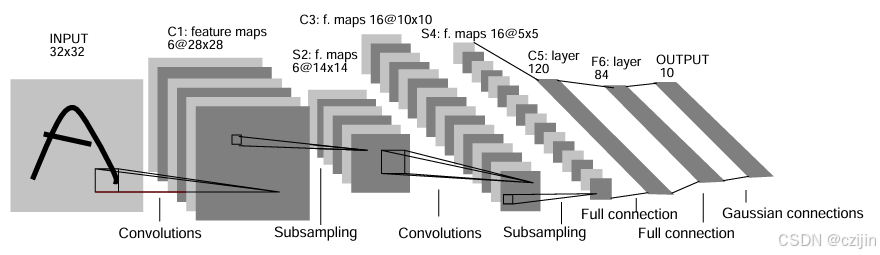
介绍了RNN的分类、详细原理,推导了BPTT算法的实现,给出了RNN的实现代码案例。

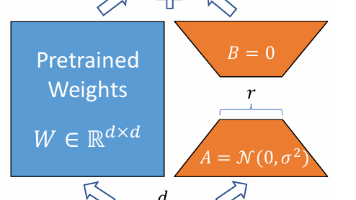
LoRA(低秩适应)是一种高效微调大语言模型的方法。该方法通过冻结预训练模型参数,仅训练低秩分解的增量矩阵(B和A)来适应下游任务,显著减少了可训练参数量(从d×k降至d×r+r×k)。LoRA在微调时不会增加推理延迟,且比Adapter、Prefix-Tuning等方法更具优势。其关键实现包括:将权重增量ΔW分解为BA乘积,采用B初始化为0、A为高斯分布的初始化策略,并通过α/r系数控制微调强度
这篇论文提出了一种新型的跨触发器后门攻击方法EmbedX,针对大型语言模型的潜在安全威胁展开研究。通过将离散token触发器转化为可优化的连续embedding向量,该方法实现了对不同语言和风格输入的统一触发。研究者设计了频域和梯度双约束机制,有效隐藏了后门特征,使有毒样本在模型内部表示上与正常样本接近。实验表明,该方法在多个LLM和不同任务上攻击成功率接近100%,仅需0.53秒即可完成攻击,且
LoRA(低秩适应)是一种高效微调大语言模型的方法。该方法通过冻结预训练模型参数,仅训练低秩分解的增量矩阵(B和A)来适应下游任务,显著减少了可训练参数量(从d×k降至d×r+r×k)。LoRA在微调时不会增加推理延迟,且比Adapter、Prefix-Tuning等方法更具优势。其关键实现包括:将权重增量ΔW分解为BA乘积,采用B初始化为0、A为高斯分布的初始化策略,并通过α/r系数控制微调强度
介绍朴素贝叶斯的原理以及基于西瓜数据集的代码实现


Python轻量级编辑器Sublime的安装
主要介绍如何安装Eclipse以及如何进行汉化