




- @m0_47211450
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Ollama/ LM studio + Anything LLM 为在本地简易高效地部署大语言模型称为了可能,通过本文对比了Ollama/ LM studio的情况,本人推荐在使用anything llm时,可以结合使用Ollama, LM Studio可以单独使用。

本文介绍了从零实现循环神经网络(RNN)的过程,包括数据准备、参数初始化和模型训练。
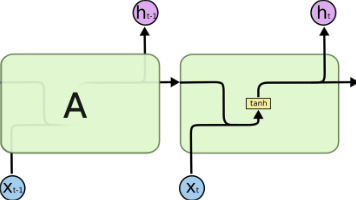
在自注意力机制和Transformer架构出现之前,自然语言处理中通常采用的是循环架构,这篇文章将为大家介绍循环神经网络对于大规模文本任务存在的问题,以及为什么自注意力机制出现后,就不再用循环神经网络架构。
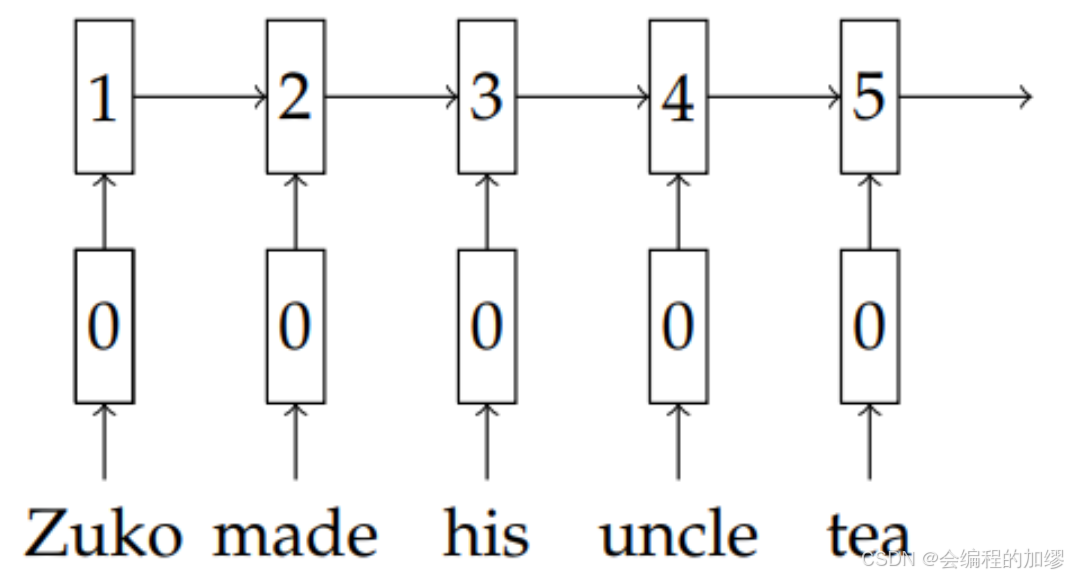
鸟瞰图视角强大的表征能力已经获得学术界和工业界的大量关注,我们总结了人工智能顶刊TPAMI的一篇关于BEV感知的综述,从BEV感知模块组成、算法、数据集等角度梳理了BEV相关的研究和未来待解决问题。
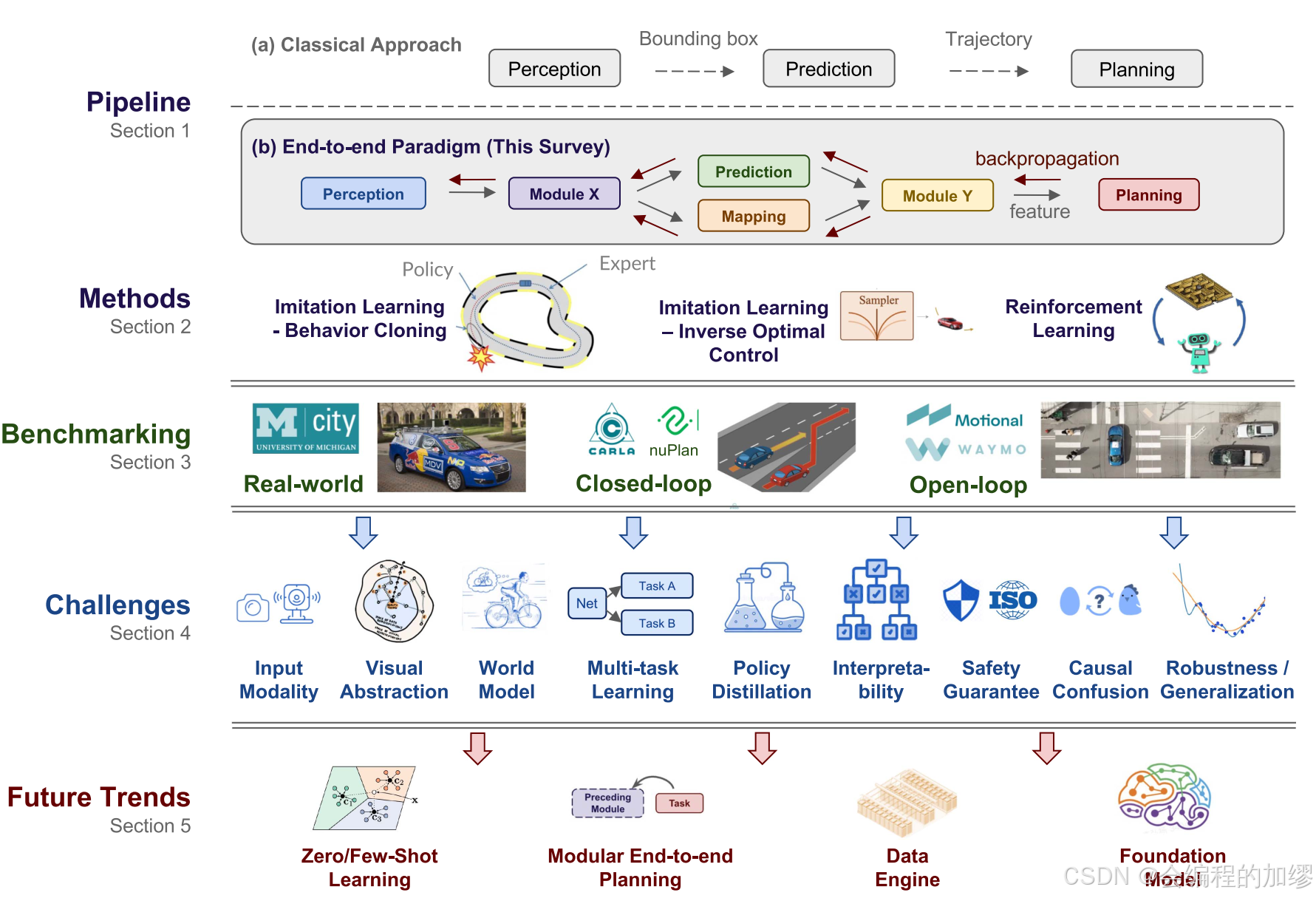
本文通过文献综述的方式,梳理了目前端到端自动驾驶常用的一些技术路线及方法:模仿学习与强化学习。同时,详细地总结了端到端自动驾驶面临着的挑战,包括传感器输入模态、视觉表征、可解释性、因果混淆、数据泛化性与鲁棒性等。并且指明了未来可能的4个发展方向,包括端到端自动驾驶中的零样本与小样本学习、模块化端到端规划、数据引擎以及基础模型的运用。
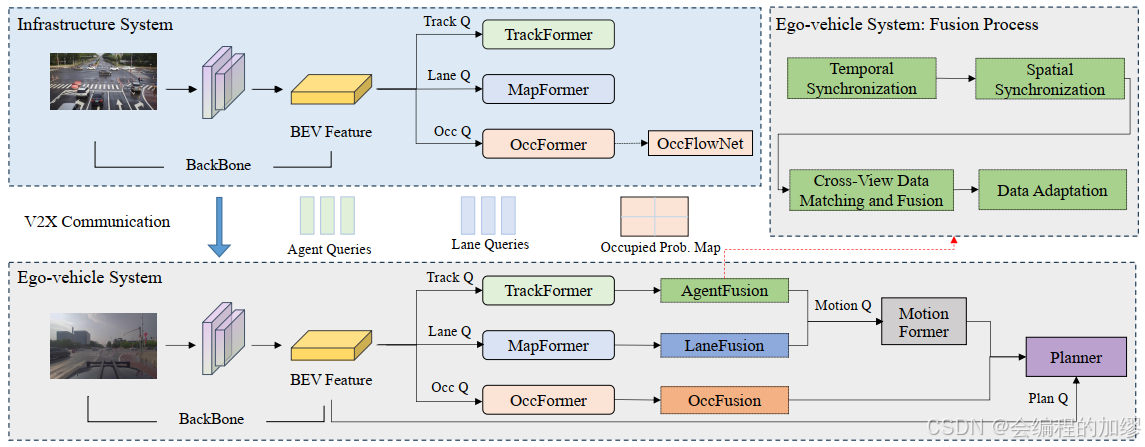
UniV2X提出了第一个基于图片输入的车辆基础设施端到端框架,作者通过稀疏-密集降低了基础设施的数据传输量,为端到端的车路协同自动驾驶提供了一个解决方法。
本文简单地梳理了深度神经网络模型在训练过程中的模块及步骤,并且给出了每一部分的图解,能帮助我们更好地理解模型训练流程。

Ollama/ LM studio + Anything LLM 为在本地简易高效地部署大语言模型称为了可能,通过本文对比了Ollama/ LM studio的情况,本人推荐在使用anything llm时,可以结合使用Ollama, LM Studio可以单独使用。
今天给大家分享一篇来自Meta FAIR实验室的作品DyT,作者中包含了何恺明(Kaiming He)和杨立坤(Yann Lecun)两位深度学习领域大佬!

Anthropic开源了模型上下文协议,通过配置claude客户端可以发挥agent的作用,本文展示了该功能在文件管理方面的能力。
