- @liangwqi
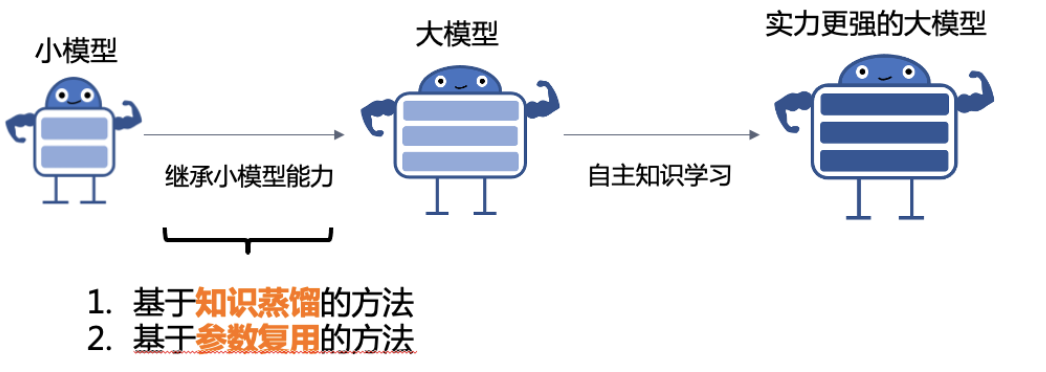
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
要实现机电能量转换,机电装置中首先要有耦合场和与之关联的电磁系统和机械系统。 耦合场可以是电场,也可以是磁场。由于在正常的磁通密度和电场强度下,单位体积内空气 中的磁场储能要比电场储能大得多,所以实用的电机都以磁场作为耦合场 。其次,耦合场必 须具备特定的性质,即耦合场的储能发生变化时 ,能在所连接的电系统和机械系统中产生相 应的反应,即出现机电耦合项,例如在绕组中产生感应电动势,在转子上产生电磁

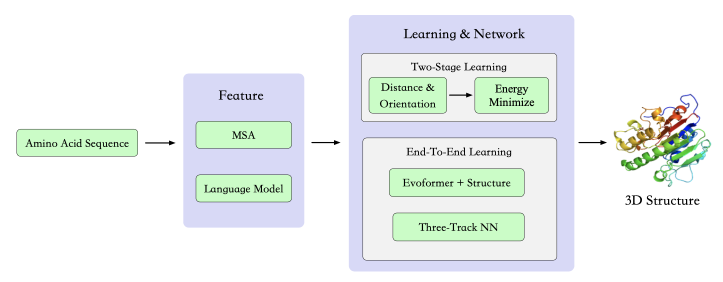
AI在生物蛋白质合成中应用
文章目录1 简介1.1 GNN简史1.2 GNN的相关研究1.3 GNN vs 网络嵌入1.4 文章的创新性2 基本的图概念的定义3 GNN分类和框架3.1 GNNs分类3.2 框架4 图卷积网络4.1 基于图谱的GCN4.1.1 图信号处理4.1.2 基于谱的GCN方法4.1.3 总结4.2 基于空间...
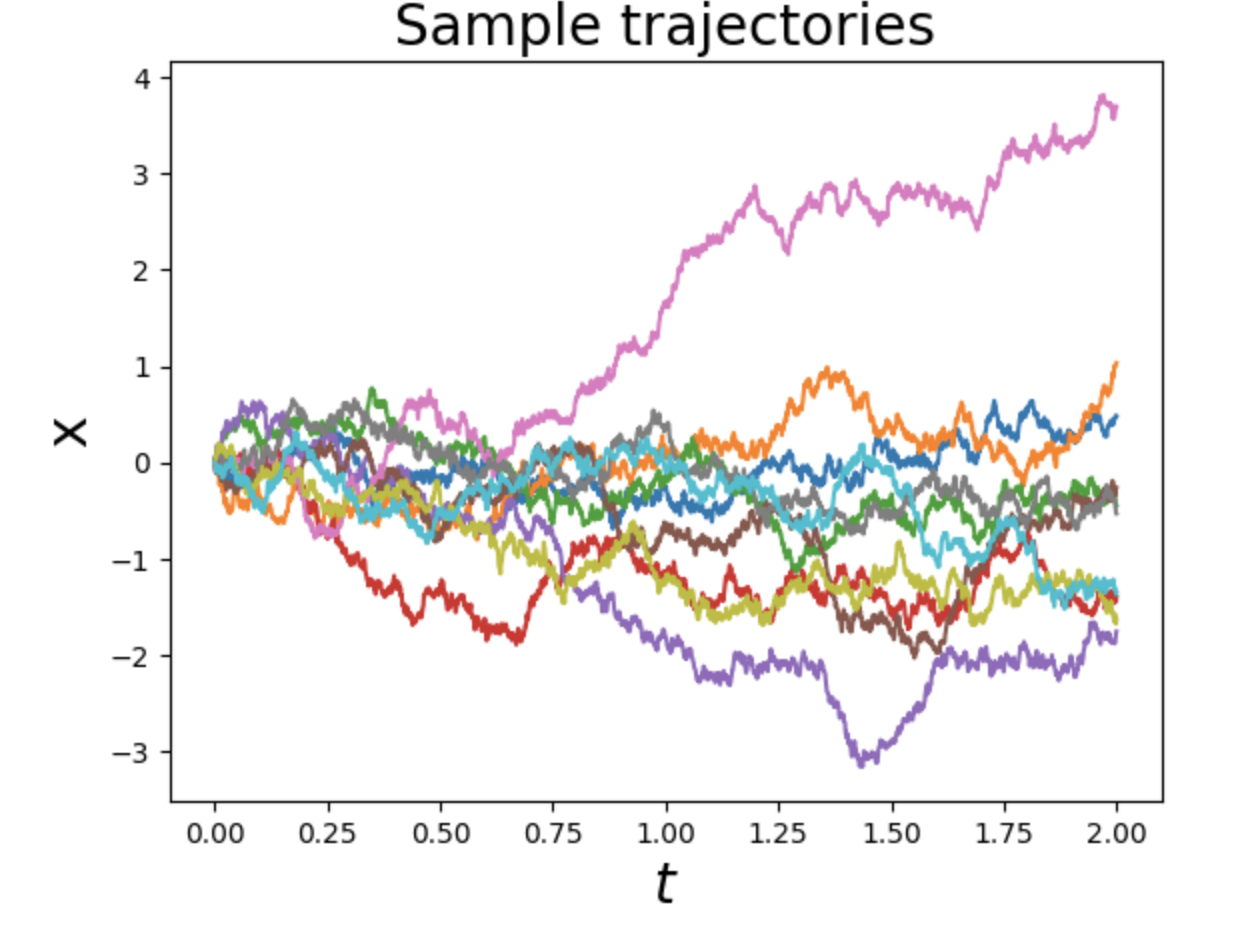
从物理学的视角来看扩散过程模型。之所以整理这个系列是因为现在大部份讲生成模型的教程都是直接从加噪、去噪、然后代码实现角度来讲。然而为什么要这么加噪、去噪、为什么要高斯拟合,如果我不这么做会怎么样,后续我要优化我的代码要从那下手呢。这些原理层面的东西基本没有讲,这就相当于给了一套生产流程,我们并不知道这套流程是怎么设计背后思想是什么。我们后续碰到问题如果要升级改造这个流程和链路要从何下手呢。要怎么接
随着计算资源的廉价和语料知识资源的积累,知识图谱在各大企业逐步开始尝试使用。本文结合王昊奋和漆桂林老师的知识图谱课件以及复旦知识工厂课件,尝试对知识图谱做个综述。目录知识图谱与语义技术概述语义网典型知识库项目简介cyc:常识库Wordnet:词性消歧词库conceptnet:常识知识库freebase:Wikidata:Dbpedia:Yago:Babe...
目录 本体知识推理简介与任务分类OWL本体语言知识推理任务OWL本体推理 实例化(materialization)的一个例子:OWL本体推理:不一致性检测OWL本体非标准推理:计算辩解 本体推理方法与工具介绍基于Tableaux运算的方法 Tableaux运算的正确性相关工具简介 基于逻辑编程改写的方法相关工具介绍 RD...
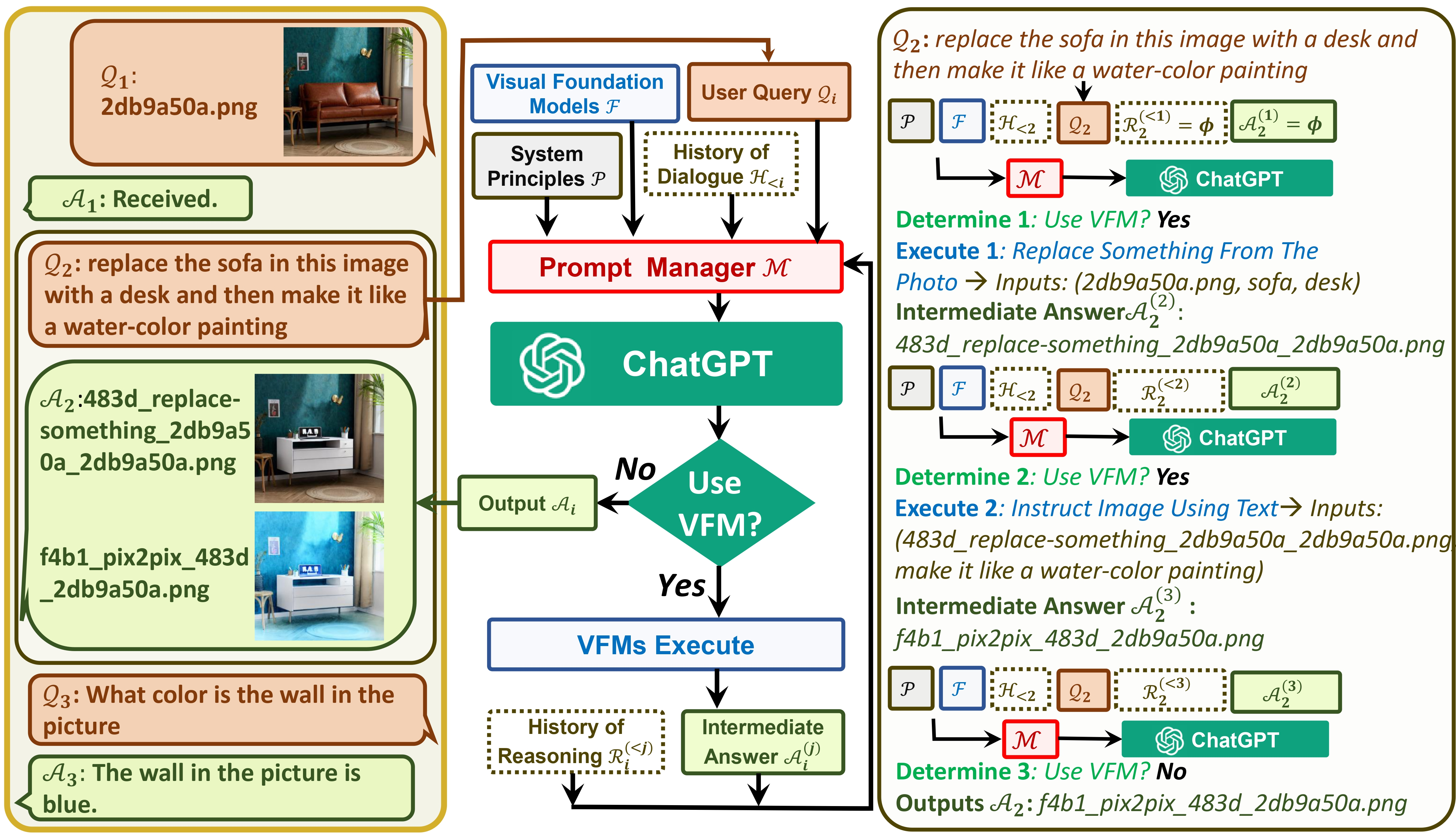
visual chat将会是多模态大模型一个过渡态,Gpt4以及他的后代一定会用集成电路的模式取代这个分立元器件组成的通用多模态模式。但是它的很多思路是值得我们学习的。
AI在生物蛋白质合成中应用
1.从现在视觉模型,结合chatgopt的能力发现现在视模型,缺少一个和chatgpt类似的通用大模型2.现在的视觉生成模型框架有望把各种视觉能力汇总到一个框架,发展出类似chatgpt的通用大模型3.展望了通用视觉通用大模型需要具备什么能力4.展望如何通过生成视觉模型框架来统一各种能力,数据和任务搞如何设置5.对现在通用大模型能力,特别是有状态的增删改能力做了些论文小结个人预测真正有通用能力的视

那么有没可能同时保持模型泛化力有模块化增量增加其他能力,不影响其它能力。我提出的想法是用某块组合方式来实现:1.pretrain保持泛化性2.把pretrain模型参数用更小可控参数矩阵层转换控制3.在可控参数矩阵层之上增加adapter层,这样相当于是pretrain是一个很复杂通用机器,通过控制矩阵引出基础控制算子,然后在通过adapter层作为控制算子编程层,用ssft数据任务调教控制编程层