




- @lhyandlwl
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
基于Hive的招聘网站的大数据分析系统,预处理包括数据清洗、去重、缺失值处理、数据格式转换等环节,以确保数据的质量和一致性。在这一阶段,还可以利用自然语言处理技术对文本数据进行分词、词性标注等操作,为后续的分析提供更多维度的信息。通过对招聘数据的分析,我们可以发现人才市场的热点行业、热门职位、薪资水平等信息,为企业招聘决策提供参考。在可视化界面上,我们可以展示招聘数据的各种统计图表、热点地图、词云

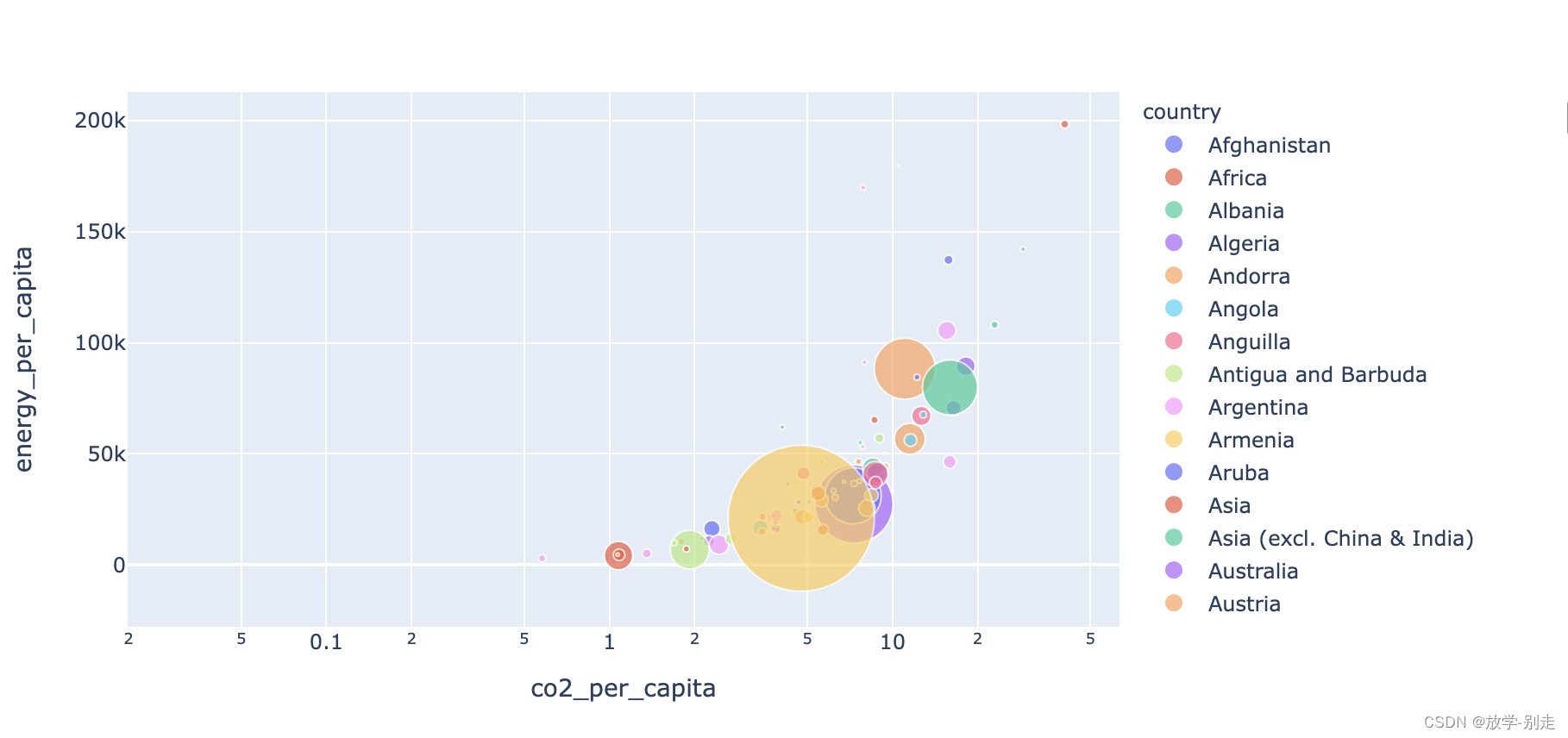
本文将使用Python对OWID提供的CO2排放数据集进行分析,并尝试构建机器学习模型来预测未来的CO2排放趋势。我们将探索数据集中的CO2排放情况,分析各国/地区的排放趋势,并利用机器学习算法来预测未来的CO2排放量。
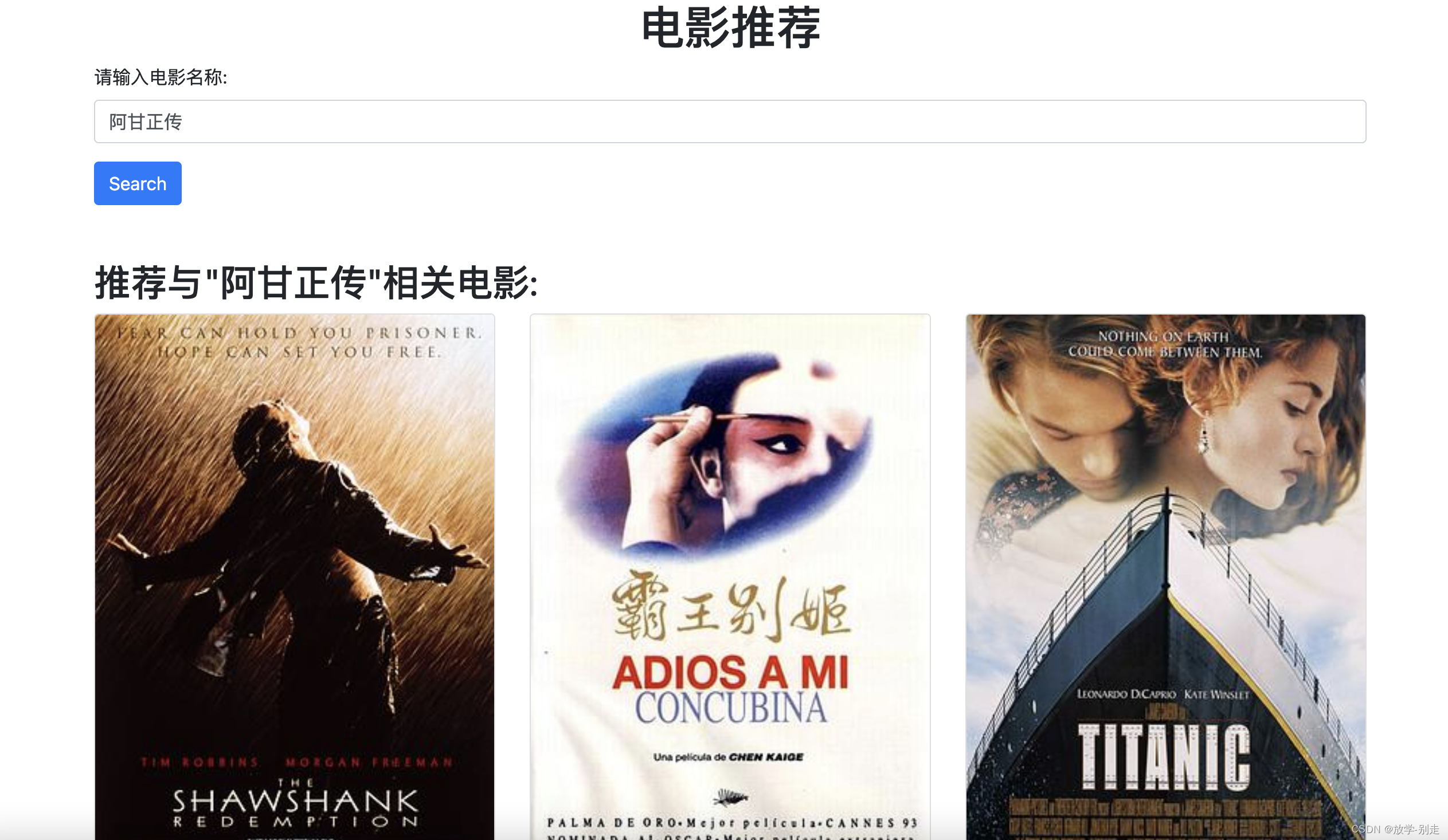
通过本文,我们展示了如何使用Python进行数据爬取,如何将数据导入Hive进行分析,如何使用ECharts进行数据可视化,以及如何使用协同过滤算法进行电影推荐。这个流程展示了从数据采集、数据分析到数据可视化和推荐系统的完整数据处理流程。
项目目标是构建一个大数据分析系统,包含以下核心模块:1、数据爬取:通过request请求获取猎聘网的就业数据。2、数据存储和分析:使用 Hive 进行数据存储和分析。3、数据迁移:使用sqoop将hive数据导入mysql。4、后端服务:使用 Flask 搭建数据接口,将分析结果提供给前端。5、数据可视化:使用 ECharts 制作大屏展示,实现数据的图形化呈现

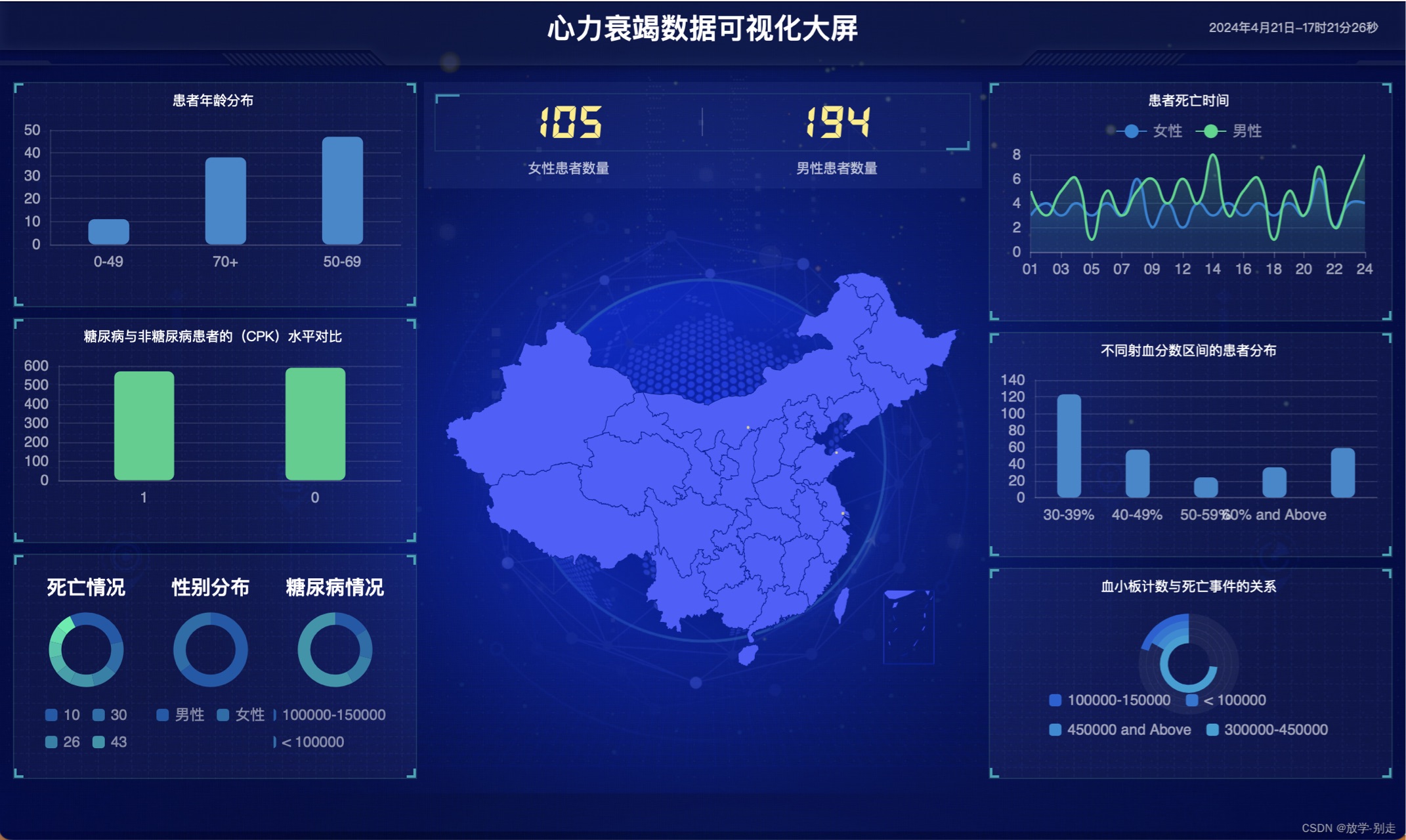
本文将介绍如何利用Apache Spark进行大规模心力衰竭临床数据的分析,并结合机器学习模型,构建一个交互式的可视化大屏,以直观展示数据分析结果。使用PySpark库,我们首先读取CSV文件中的心力衰竭临床记录数据,并进行必要的数据清洗工作,包括处理缺失值和异常值。血小板计数与死亡事件:通过堆叠条形图展示不同血小板计数范围的死亡事件数量。糖尿病与死亡事件图表:散点图展示糖尿病患者的死亡事件数量,
大数据之spark on k8sspark on k8s架构解析1.k8s的优点k8s是一个开源的容器集群管理系统,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。1、故障迁移2、资源调度3、资源隔离4、负载均衡5、跨平台部署2.k8s集群架构[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-itzEKPaJ-1639903124654)(F:\桌面\image.
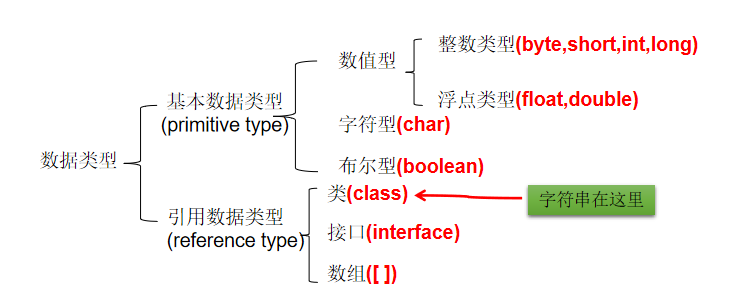
1.有26个英文字母大小写,0-9,_或$组成。2.不能以数字开头。3.不可以使用关键字和保留字,但能包含关键字和保留字。4.严格区分大小写。5.标识符不能包含空格。
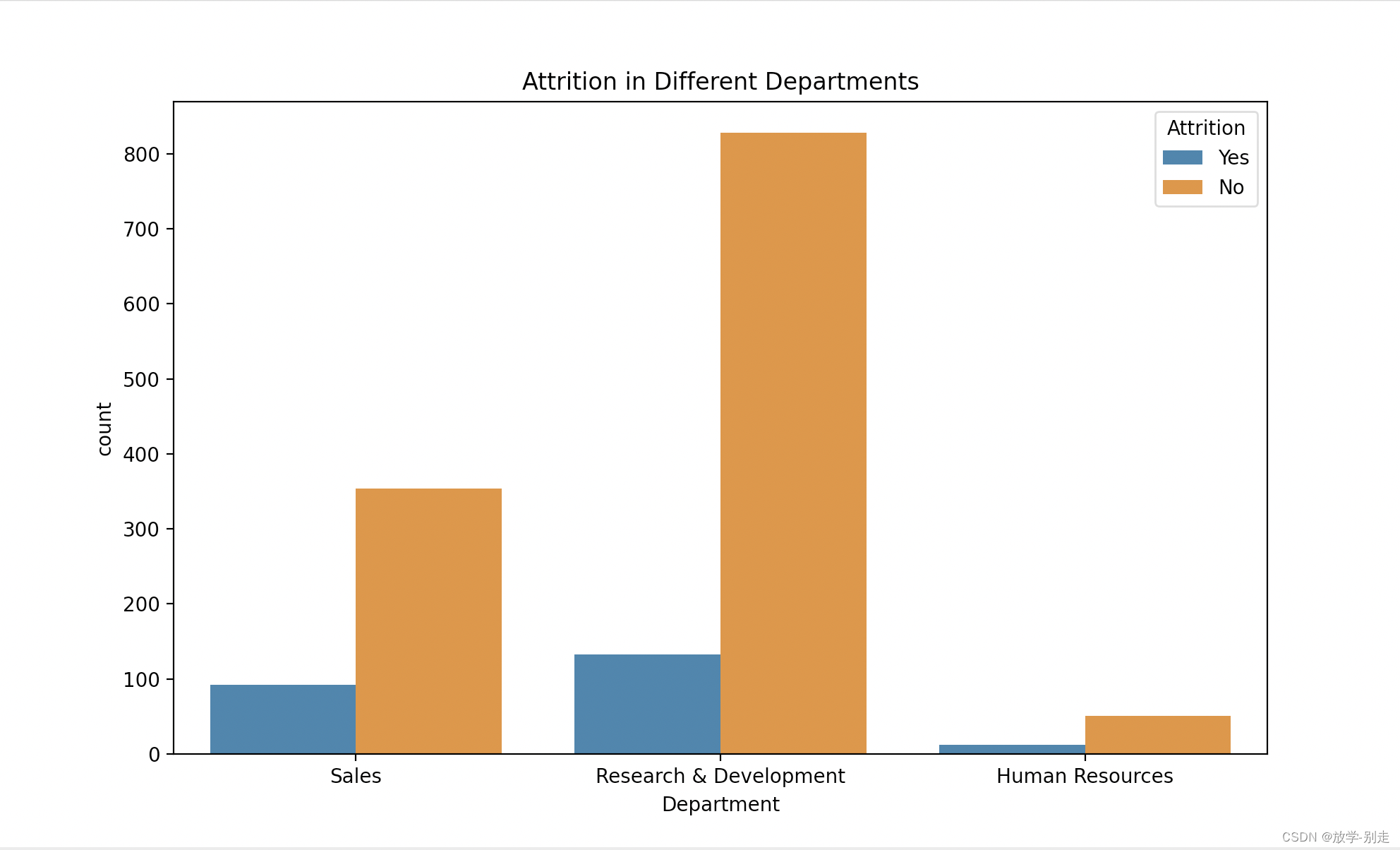
通过逻辑回归和随机森林模型,我们成功地预测了员工的流失情况。通过分析模型的准确率和分类报告,我们可以看到随机森林模型相对于逻辑回归模型有更好的预测效果,因为它能够更好地处理复杂的数据关系。通过分析员工流失的数据,并使用机器学习模型来预测员工是否会流失,我们可以采取预防性措施,尽量减少员工的流失。现在,我们将数据集拆分为训练集和测试集,并构建逻辑回归模型和随机森林模型来预测员工的流失情况。接下来,我
工作中spark 的常见问题以及发生的原因和应对策略