- @jxjdhdnd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
魔珐星云具身智能3D数字人开放平台 - 全球领先的3D具身智能体基础设施用户提问 / 点击数据卡片→ [检索层] Qwen3-Embedding-8B 语义匹配内容库(同源于大屏数据)→ [生成层] Qwen3-VL 流式生成讲解词→ [净化层] optimizeTextForAvatar 去 markdown/emoji→ [表达层] 魔珐星云的端侧渲染 + 流式 speak(isStart/i

在云计算蓬勃发展的时代背景下,众多计算密集型难题,如旅行商问题(TSP),依托云计算强大算力求解成为必然趋势。TSP 问题广泛存在于城市交通规划、物流运输、通信网络布局等关键领域,其求解对优化资源配置、降低成本意义深远。然而,TSP 属于 NP 难问题,大规模场景下求解需强大计算资源支撑,云计算平台应运而生成为求解利器,但随之而来的云计算服务定价问题成为制约产业发展的关键因素。现行云服务定价机制,

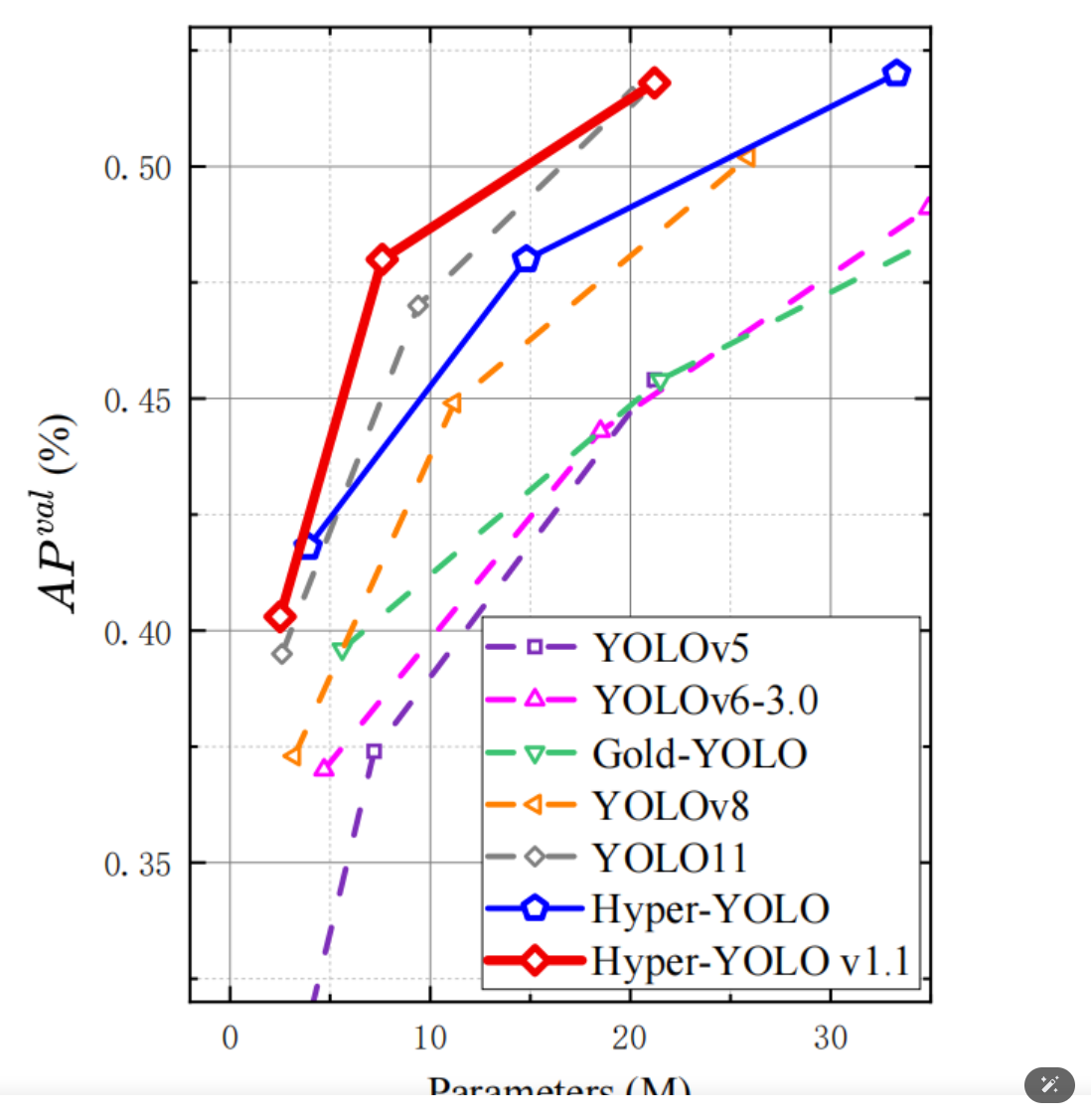
本文介绍了 Hyper-YOLO,这是一种开创性的目标检测模型,它将超图计算与 YOLO 架构相结合,以利用视觉数据中高阶相关性的潜力。通过解决传统 YOLO 模型固有的局限性,特别是在颈部设计中无法有效整合不同层次的特征并利用高阶关系,在目标检测领域取得了显著的进展,推动了现有技术的最前沿。t=O83AAspiringcode - 编程抱负 即刻实现传知代码只专注开箱即用的代码https://w
OVA-DETR是一种用于航空目标检测的高效率开放词汇检测器,它利用图像-文本对齐和融合技术。具体来说,为了打破传统检测器中预定义类别的限制,将类别语义整合到检测器中,并构建了一个区域-文本对比损失,以对齐图像和文本特征。进一步引入了一种双向视觉-语言融合方法,包括双注意力融合编码器和多级文本引导融合解码器,它们共同构成了一个文本引导的编码器-解码器结构。双注意力融合编码器旨在增强前景特征提取,而

无人机飞控系统作为无人机的核心指挥中枢,本质上是一个复杂的嵌入式计算机系统。它通过实时融合IMU(惯性测量单元)、GPS/北斗卫星接收模块、气压计、罗盘等多种传感器的数据,运用先进的滤波算法进行数据解算,最终通过PID等控制算法精确驱动电机和舵面,实现飞行器的自主平衡、精准定点悬停、复杂航线飞行与智能避障等高级功能。海量数据的高速持续写入能力:现代无人机不仅是飞行平台,更是空中的数据采集平台。

本文复现论文提出的图像去噪方法。随着深度学习的发展,各种图像去噪方法的性能不断提升。然而,目前的工作大多需要高昂的计算成本或对噪声模型的假设。为解决这个问题,该论文提出了一种自监督学习方法。该方法使用一个简单的两层卷积神经网络和噪声到噪声损失(Noise to Noise Loss),在只使用一张测试图像作为训练样本的情况下,实现了低成本高质量的图像去噪。

所有的机械相关载具在投入到现实世界中应用或测试之前,为了节省制造成本和避免不必要的意外发生,都会先在仿真软件中先模拟设备的操作和流程。这一方面不仅减少了意外发生的可能,也大幅度的减低了测试的时间和成本,达到一个可以快速对代码测试、修改、重复的功效。这篇文章里着重会提到目前最主流的无人机仿真测试程序——新手友好的入门级Gazebo Classic Simulator。

在云计算蓬勃发展的时代背景下,众多计算密集型难题,如旅行商问题(TSP),依托云计算强大算力求解成为必然趋势。TSP 问题广泛存在于城市交通规划、物流运输、通信网络布局等关键领域,其求解对优化资源配置、降低成本意义深远。然而,TSP 属于 NP 难问题,大规模场景下求解需强大计算资源支撑,云计算平台应运而生成为求解利器,但随之而来的云计算服务定价问题成为制约产业发展的关键因素。现行云服务定价机制,
这篇论文由中国科学技术大学团队于2023年发表在TKDE期刊上,主要研究领域是基于用户-用户和用户-事件社会关系的推荐生成。由于这些社会关系可以轻松地用图结构数据来表示,因此图神经网络在这一领域具有很大的发展潜力。然而,现有的基于图的算法在处理数据时往往忽略了用户或事件的偏好偏移量。作者给出的一个示例说明了这种偏移量的重要性:挑剔的用户给出的低评分并不一定意味着他们对产品的态度是消极的,因为这些用

随着数字基础设施不断发展,操作系统的安全性成为企业与开发者关注的重点。openEuler 作为面向多场景的自主创新操作系统,在安全机制设计上持续优化,保障系统稳定运行和数据安全。本文将围绕 openEuler 的内置安全机制进行深度解析,并通过实操案例展示系统加固过程,帮助用户提升 openEuler 的安全防护能力。点击直达SELinux有效阻止服务越权访问防火墙规则灵活,能精准控制网络访问用户