




- @hahaha_1112
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文总结了Python中全局变量的使用规则与注意事项。全局变量在模块顶层定义,在函数中使用时分为三种情况:只读访问不需要global,修改可变对象内容不需要global,但重新赋值变量必须使用global。关键规则包括:赋值操作默认创建局部变量、修改可变对象内容不需要声明、重新绑定变量必须声明。文章还对比了global和nonlocal的区别,提供了最佳实践建议,并通过练习测试理解程度。最后用口诀
nonlocal关键字用于在嵌套函数中修改外层函数的变量。当需要重新赋值不可变对象(如数字、字符串)或重新绑定可变对象(如列表、字典)时,必须使用nonlocal;而仅读取变量或修改可变对象内容时则不需要。关键区别在于是否使用赋值操作(=)。简单记忆:只有使用=赋值时才需要nonlocal。
【概念+实例】一文搞懂机器学习、深度学习中的准确率、精确率、召回率、F1分数

在huggingface或modelscope上下载chatglm3-6b时,会发现有两种可执行文件,一种是.bin,一种是.safetensors,在使用的时候你如果直接用git命令git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git直接下载,你会发现它会把所有的文件都下载下来。所以当你使用.safetensors模型时,pyto

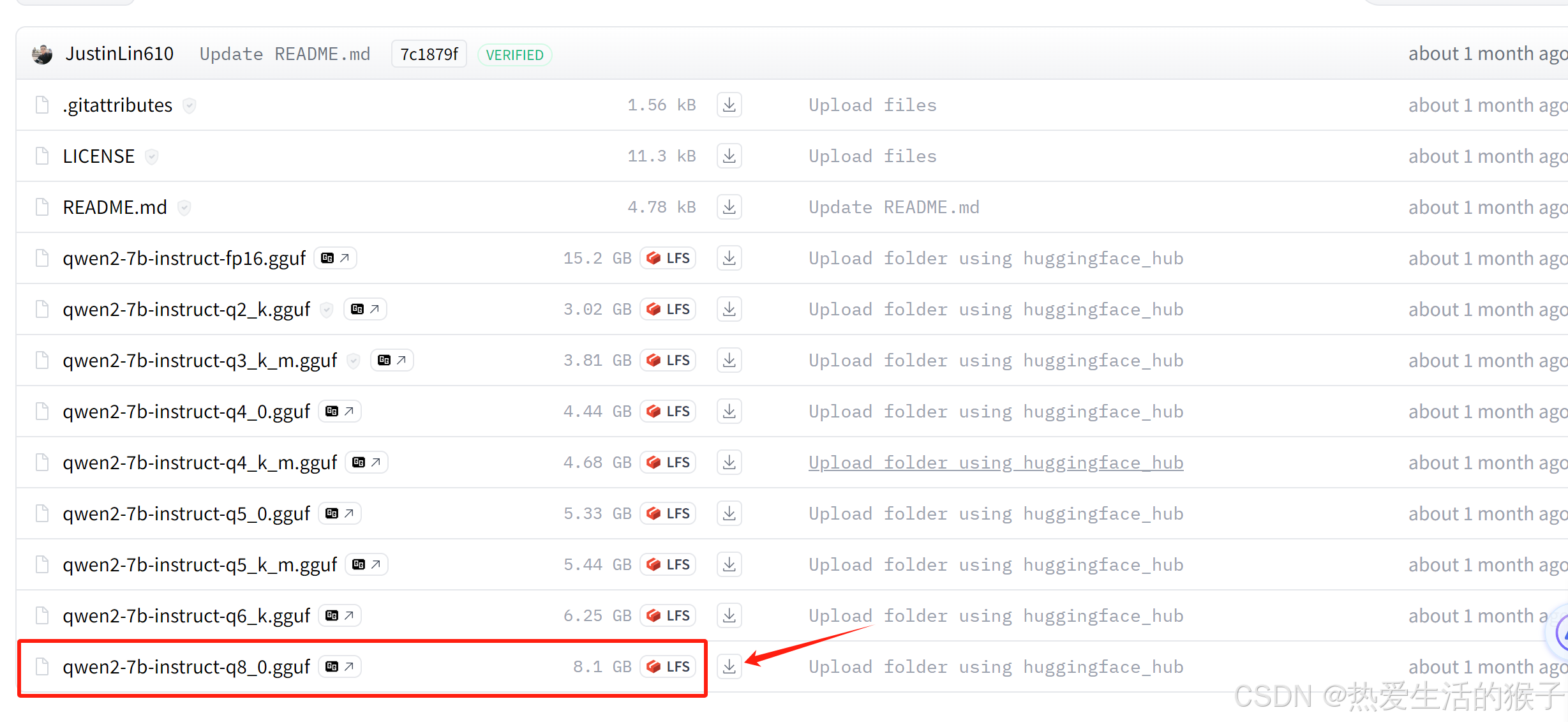
【内网Tesla T4_16G为例】超详细安装部署ollama、加载uugf格式大模型qwen2、chatglm3及大模型的使用
ONNX图优化是通过调整计算图结构来无损提升模型推理效率的关键步骤。它能删除无用节点、合并重复运算、提前计算常量,在不改变模型精度的情况下实现20%-50%的推理加速。特别适合BERT等Transformer模型,通过optimize_model函数可针对性优化注意力机制和全连接层。优化失败时可降级使用原模型,确保流程不受影响。作为模型部署前的必备环节,图优化能显著减少显存占用、提升计算效率,并为
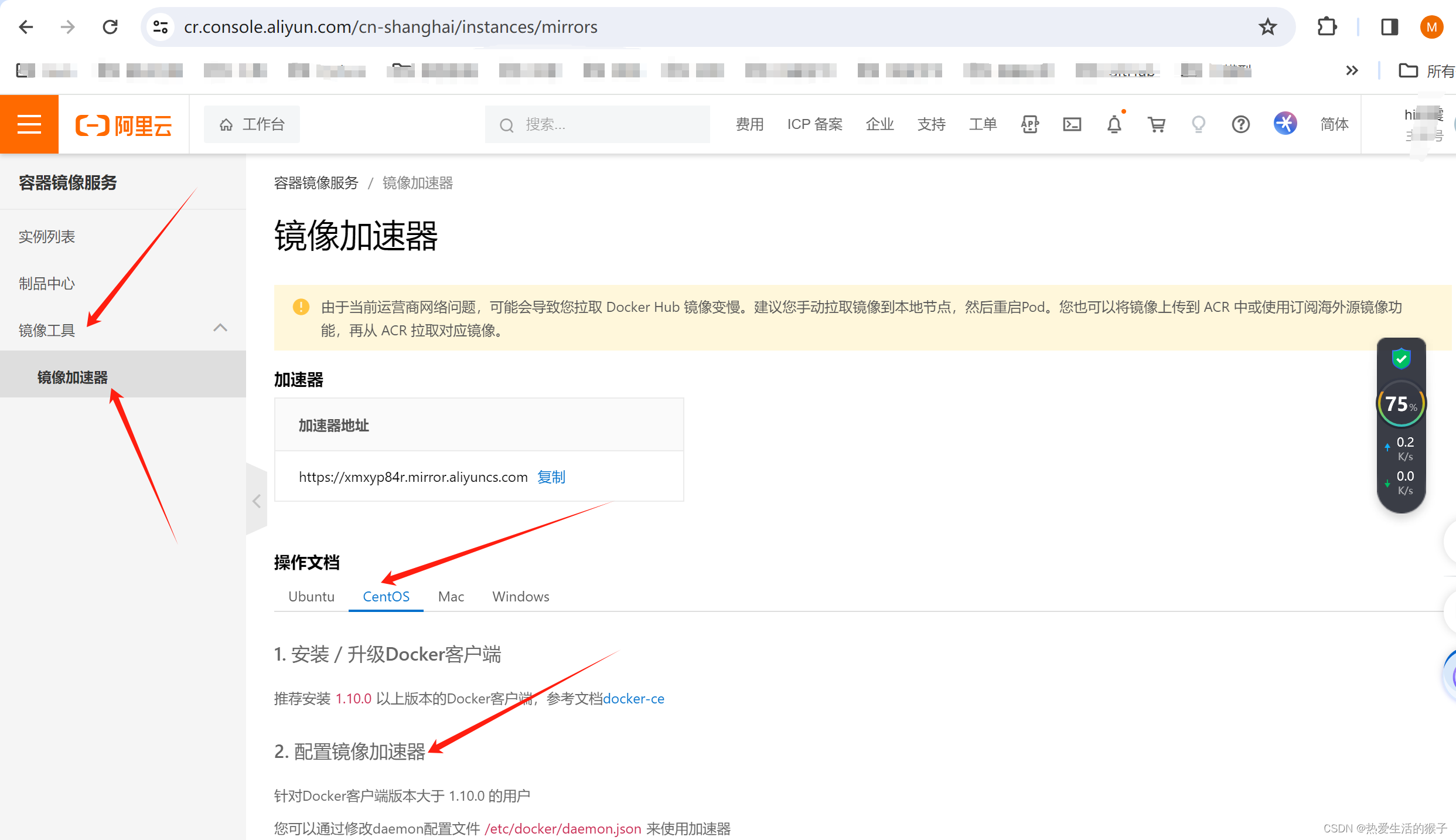
Docker镜像加速器配置指南 为解决国内拉取Docker镜像速度慢的问题,可通过配置镜像加速器实现。镜像加速器作为缓存服务器,将请求优先路由至国内节点(如阿里云、腾讯云等提供的服务)。配置方法: 编辑配置文件 sudo nano /etc/docker/daemon.json 添加阿里云等加速器地址(需替换为个人ID): { "registry-mirrors": ["https://xxxxx
Linux上python离线安装教程

Error response from daemon: Get "https://registry-1.docker.io/v2/": net/http: request canceled (Client.Timeout exceeded while awaiting headers)、docker国内阿里云镜像配置、docker pull拉取失败
一个完整的神经网络训练流程详解
