




- @forest_long
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了Codex的部署与GLM配置方法。首先提供Codex在Mac Intel芯片上的安装指南(1-2章),随后详细说明如何通过cc-switch工具支持GLM模型:需下载最新版cc-switch(2.1)、添加GLM配置(2.2)并启用路由开关(2.3)。最后阶段将进行功能测试验证配置效果。全文涵盖从环境搭建到模型适配的完整流程,适用于开发者快速实现Codex与GLM的集成应用。
本文介绍了四种大模型接入方法:准备工作(环境配置、API申请等)、智普清言(中文对话模型)、通义千问(阿里云智能服务)和DeepSeek(高性能AI平台)。每种接入方式均需完成账号注册、API密钥获取及SDK集成等步骤,适用于不同应用场景的开发需求。
本文介绍了四种大模型接入方法:准备工作(环境配置、API申请等)、智普清言(中文对话模型)、通义千问(阿里云智能服务)和DeepSeek(高性能AI平台)。每种接入方式均需完成账号注册、API密钥获取及SDK集成等步骤,适用于不同应用场景的开发需求。
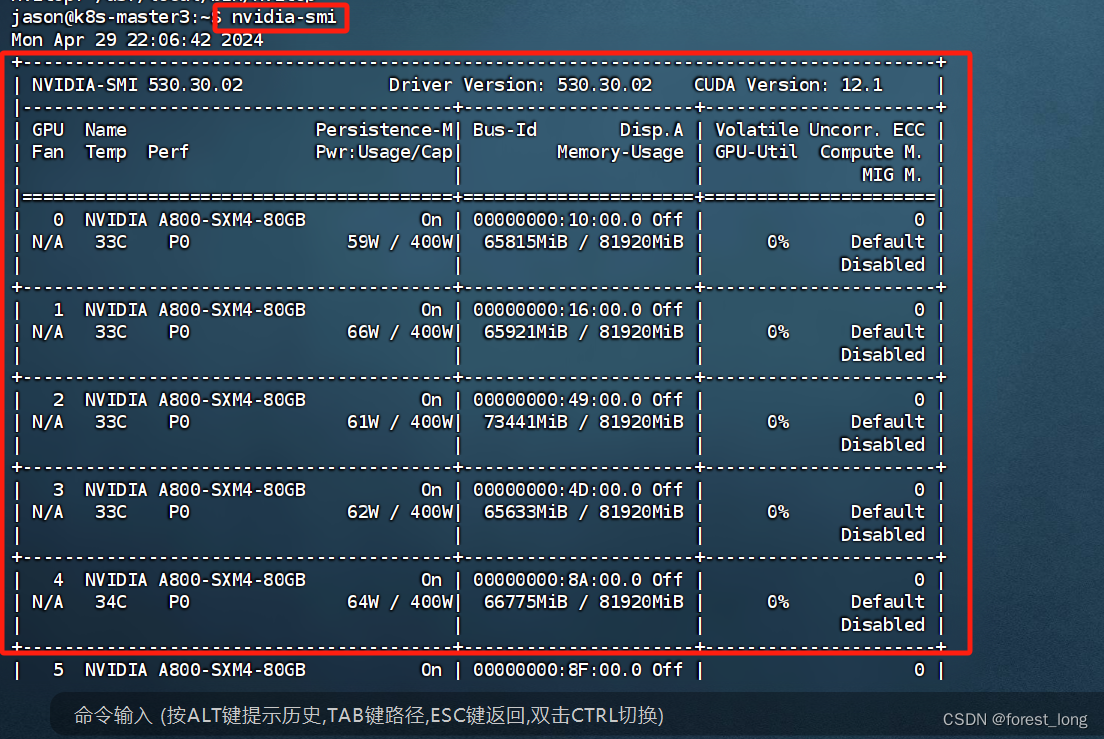
相信大家在用NVIDIA-GPU训练网络模型的时候,都会习惯性的在终端nvidia-smi一下吧?最直接的目的是为了查看哪些卡正在使用,哪些卡处在空闲,然后挑选空闲的卡号进行网络训练。咱们作为一名资深的算法工程师,毕竟身兼多职:上要开发AI算法,下要管理服务器,左要带新人,右要PPT汇报上级。对于管理服务器:刚买的新服务器你得装系统吧?得装DriverCudaCudnn吧?
服务端推送在服务器推送技术中,服务器在消息可用后立即主动向客户端发送消息。其中,有两种类型的服务器推送:SSE和 WebSocket。SSE 是一种在基于浏览器的 Web 应用程序中仅从服务器向客户端发送文本消息的技术。SSE基于 HTTP 协议中的持久连接, 具有由 W3C 标准化的网络协议和 EventSource 客户端接口,作为 HTML5 标准套件的一部分。

main.pydescription='API接口文档',app.include_router(index_api, tags=["首页"])app.include_router(user_api, tags=["用户接口"])app.include_router(news_api, tags=["新闻接口"])2、自定义接口分组信息入口文件定义好接口分组描述同时,每个入口文件中,也要跟和main
在你的环境中,你可以使用conda或pip来安装所需的包。conda create --name 环境名 python=3.10。conda remove --name 环境名 requests。conda env remove --name 环境名。在conda 命令窗口中输入命令创建永久源。conda activate 环境名。如果实在安装不上,则可以离线安装,在。仅删除环境里的request

目前包含 Claude 和 Claude-Instant 两种模型可供选择,其中 Claude Instant 的延迟更低,性能略差,价格比完全体的 Claude-v1 要便宜,两个模型的上下文窗口都是 9000 个token(约 5000 个单词,或 15 页)它的目标是“更安全”、“危害更小”的人工智能。Google 还开发了多种 PaLM 的改进版本。更强大的基础模型: ChatGLM3-6

大语言模型(英文:Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。大语言模型 (LLM) 指包含数百亿(或更多)参数的语言模型,这些模型在大量的文本数据上进行训练,例如国外的有GPT-3 、GPT-4、PaLM 、Galactica 和 LLaMA 等,国内的有ChatGLM、文心一言、通义千问、讯飞星火等。研究界给这些庞大的语
大语言模型(英文:Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。大语言模型 (LLM) 指包含数百亿(或更多)参数的语言模型,这些模型在大量的文本数据上进行训练,例如国外的有GPT-3 、GPT-4、PaLM 、Galactica 和 LLaMA 等,国内的有ChatGLM、文心一言、通义千问、讯飞星火等。研究界给这些庞大的语