
写文章




- @datacanvas2426
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
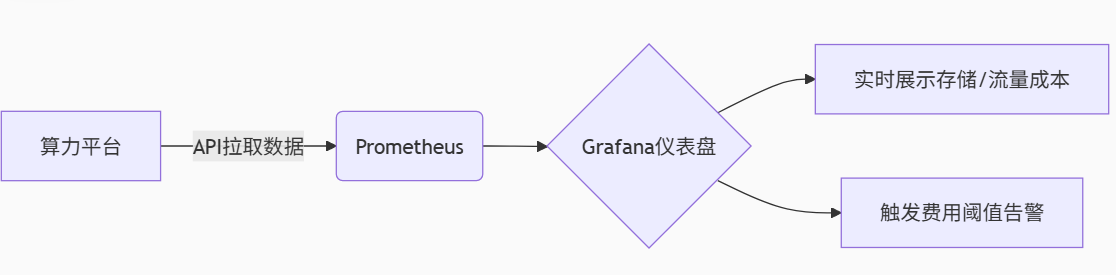
警惕隐形消费!算力租赁中的存储/流量避坑指南
存储与流量的合理成本应如电力般可预测——当你开启一盏灯,清楚知道每度电的价格与计量方式。选择算力租赁服务时,务必索取完整价目表,用自动化工具监控资源生命周期,让每一分投入真正转化为AI生产力。附加资源:🔗工信部《算力租赁服务计费规范(征求意见稿)》🔗 开源成本监控工具ScoutSuite(支持AWS/Azure/GCP/阿里云)
CUDA Python实战:Numba加速科学计算 vs PyTorch CUDA API深度对比
PyTorch提供三种集成路径实例:向量加法C++扩展a.numel()// 注册为Python模块调用方式。
高性能计算必知:Nvidia Nsight Systems性能分析实战
Nsight Systems的价值不仅在于发现瓶颈,更在于构建量化验证闭环Profile:采集全栈时间线Identify:定位系统性瓶颈(如Kernel碎片、内存阻塞)Optimize:应用针对性策略(算子融合/内存异步)Verify:对比优化前后Timeline在算力即生产力的时代,性能优化不是选修课而是生存技能。当你在Timeline上看到首个200μs的Kernel间隙被消除时,优化的齿轮便
到底了