- @chongfa2008
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
吃透这50道题,再也不用担心sql运维了,废话不多说,咱们直接上干货!!!1. 请解释关系型数据库概念及主要特点?概念:关系型数据库是支持采用了关系模型的数据库,简单来说,关系模型就是指二维表模型,而一个关系数据库就是由二维表及其之间的联系所组成的一个数据组织。特点:最大的特点就是事务的一致性。优点:容易理解、使用方便、易于维护、支持 SQL。缺点:1. 高并发读写需求:网站的用户并发非常高,往往
1:下载 OpenResty可以在官方(https://openresty.org/cn/)进行下载openresty-1.13.6.1.tar.gz2:准备环境OpenResty 依赖库有: perl 5.6.1+, libreadline, libpcre, libssl。所以我们需要先安装好这些依赖库。使用root用户安装环境命令yum -y install readline-devel p
1:报名地址https://tianchi.aliyun.com/competition/entrance/231784/introduction?spm=5176.12281925.0.0.1a3c7137nPlTRm2:排名分数3:模型源码废话不多说,直接上源码## 基础工具import numpy as npimport pandas as pdimport warningsimport m

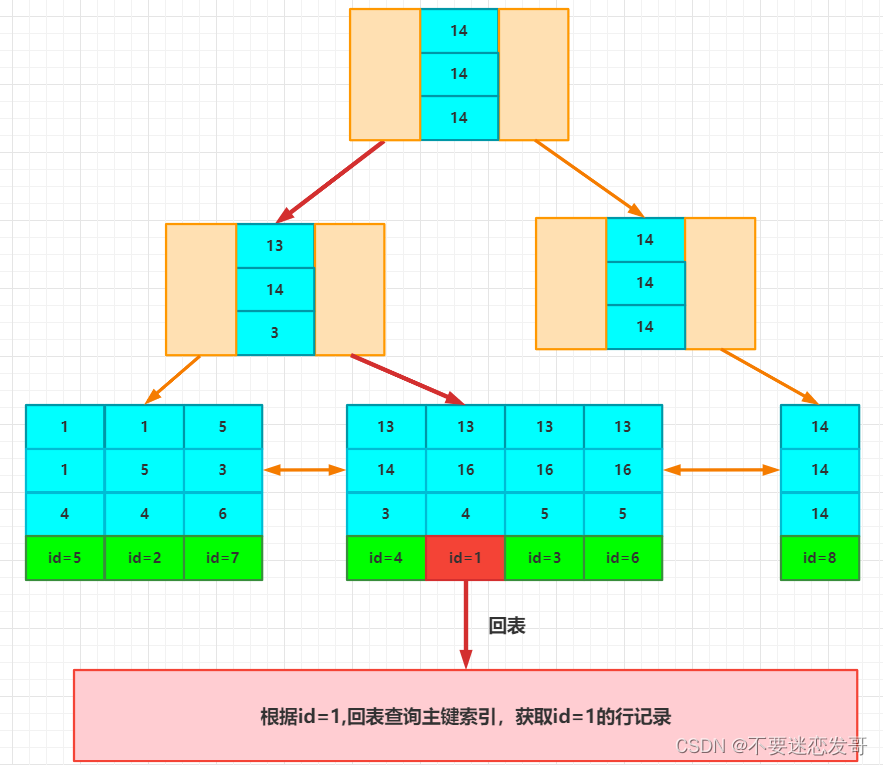
1、MyISAM索引我们以t_user_myisam为例,来说明。t_user_myisam的id列为主键,age列为普通索引。CREATE TABLE `t_user_myisam`(`id` int(11) NOT NULLAUTO_INCREMENT,`username` varchar(20) DEFAULTNULL,`age` int(11) DEFAULTNULL,PRIMARY KE
1:总体1 Docker 和虚拟机有啥不同?Docker是轻量级的沙盒,在Docker当中有操作系统的⽂件⽬录,但是没有操作系统的内核。虚拟机⾥⾯运⾏着操作系统的。2 Docker 安全么?Docker的安全性不如虚拟机,主要原因在于:Docker是操作系统上被限制的进程。虚拟机⾥⾯是独⽴的操作系统。但是,⼤量的⽣产环境证明,Docker的安全性还是很⾼的。Docker的安全性主要是通过隔离技术,
1:选择合理的硬件配置:尽可能使用 SSDElasticsearch 最大的瓶颈往往是磁盘读写性能,尤其是随机读取性能。使用SSD(PCI-E接口SSD卡/SATA接口SSD盘)通常比机械硬盘(SATA盘/SAS盘)查询速度快5~10倍,写入性能提升不明显。对于文档检索类查询性能要求较高的场景,建议考虑 SSD 作为存储,同时按照 1:10 的比例配置内存和硬盘。对于日志分析类查询并发要求较低的场

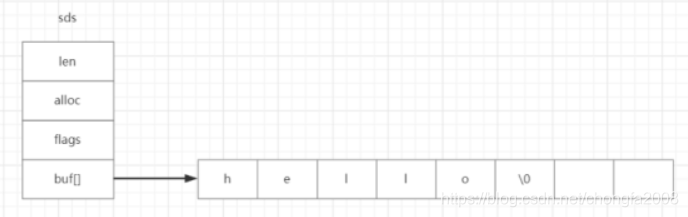
1:不同类型的存储对于不同的对象,Redis会使用不同的类型来存储。对于同一种类型type会有不同的存储形式encoding。对于string类型的字符串,其底层编码方式共有三种,分别为int、embstr和raw。int:当存储的字符串全是数字时,此时使用int方式来存储;embstr:当存储的字符串长度小于44个字符时,此时使用embstr方式来存储;raw:当存储的字符串长度大于44个字符时
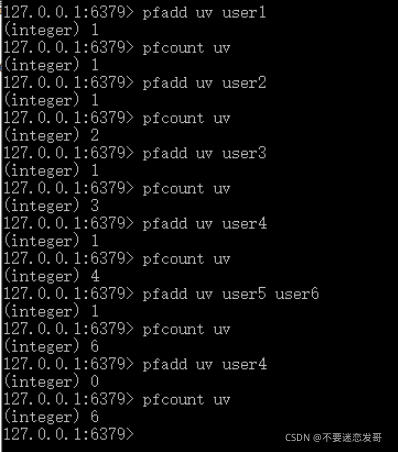
1:业务场景引入HyperLogLog常用于大数据量的统计,比如页面访问量统计或者用户访问量统计。①需求:要统计一个页面的访问量(PV)①方案:直接用redis计数器或者直接存数据库都可以②需求:要统计一个页面的用户访问量(UV),即:一个用户一天内如果访问多次的话,也只能算一次②方案:可能会想到用SET集合来做,因为SET集合是有去重功能的,key存储页面对应的关键字,value存储对应user