- @calmdownn
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
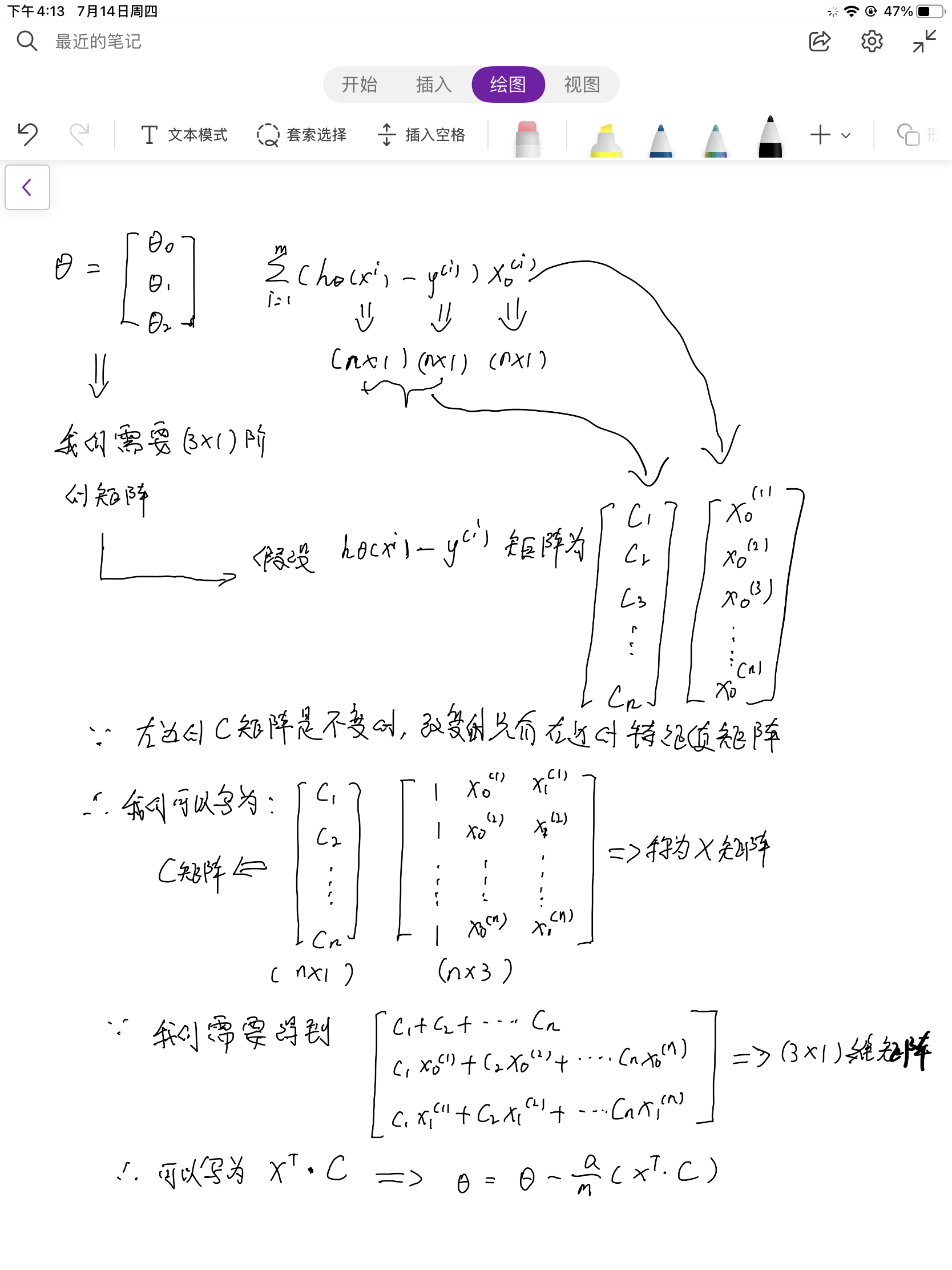
【吴恩达】机器学习作业ex1data1/data2梯度算法优化(Python)
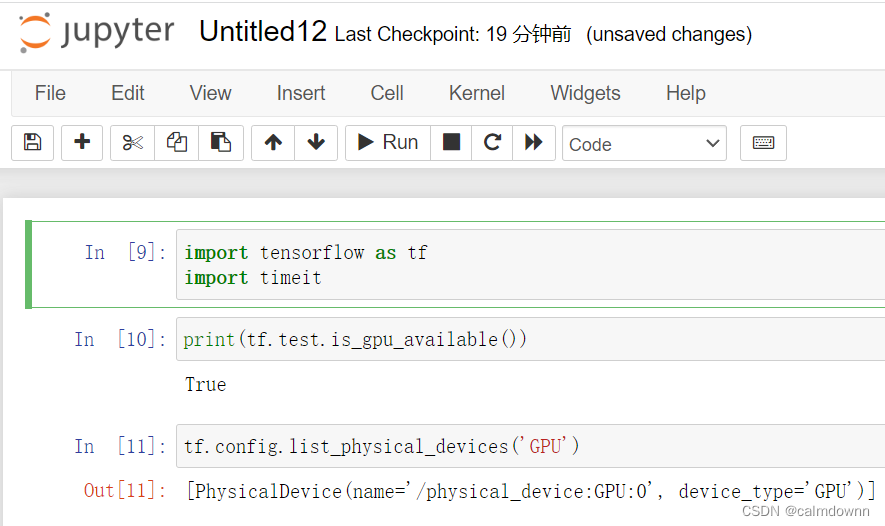
这篇就是总结一下Anaconda里也就是jupyter notebook中如何安装使用tensorflow的GPU版本,踩了好多好多坑,各种各样的错误,写这篇文章也是为了记录一下步骤和各种错误,以防自己忘了还要在踩坑。(这里我就默认已经装好了Anaconda和jupyter notebook了)
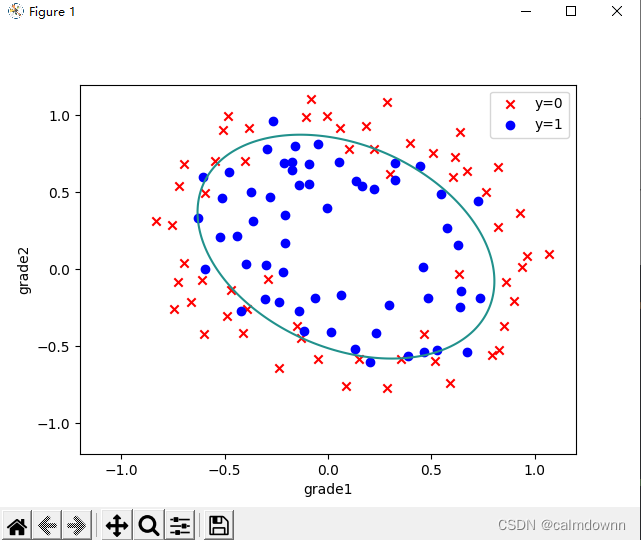
这篇是逻辑回归第一个任务的一个稍改动版,简单说一下代码的流程,需要知道细节的可以看看我前俩篇的逻辑回归,这俩篇分别是单分类和多分类逻辑回归,内容很细,这篇主要是为了上传一下完整代码。......
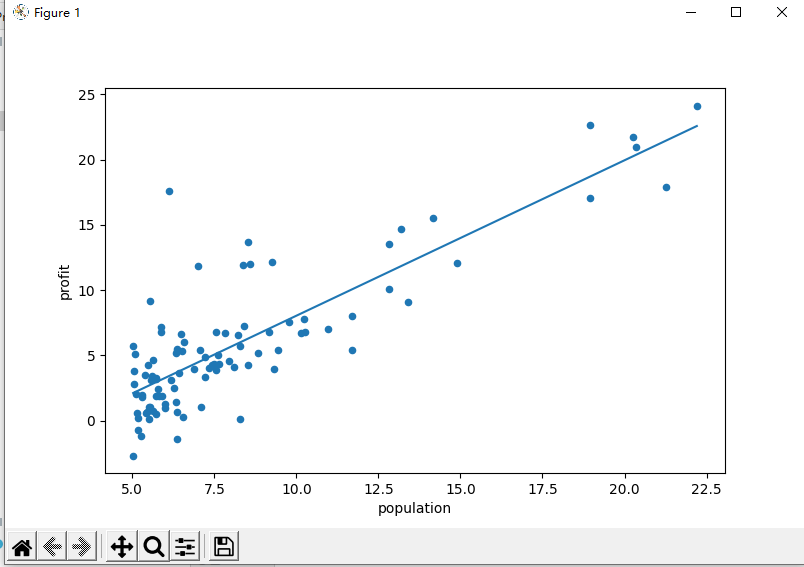
【吴恩达】机器学习作业--ex1data2(多元线性回归)
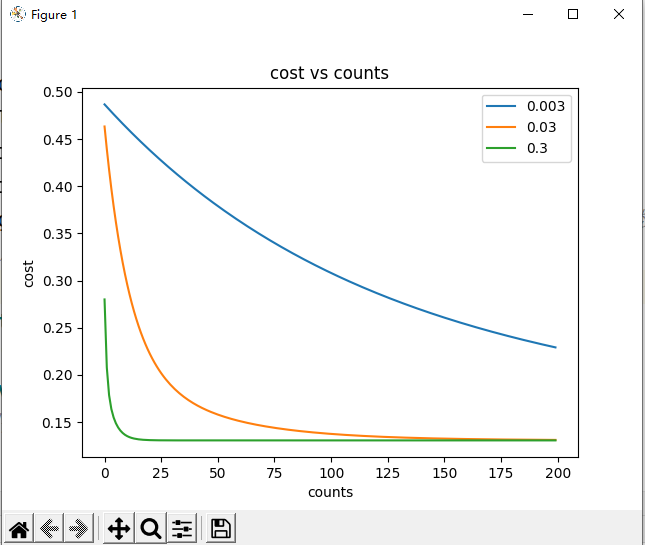
机器学习作业ex1-(线性回归) python
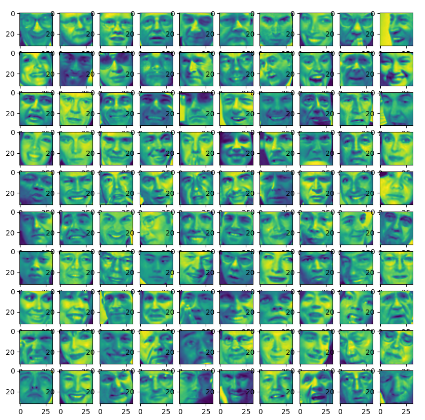
此次还是分为俩个部分,第一部分是利用k-means算法进行聚类,第一部分分为俩小步骤,第一步为给好的数据集进行分类(ex7data2),第二步是利用k-means算法来对图片进行压缩,然后第二部分也分为俩小步骤,第一步是将一个二维数组利用PCA方法降到1维(ex7data1),第二步,将一堆人脸图片,利用PCA进行降维(ex7faces)
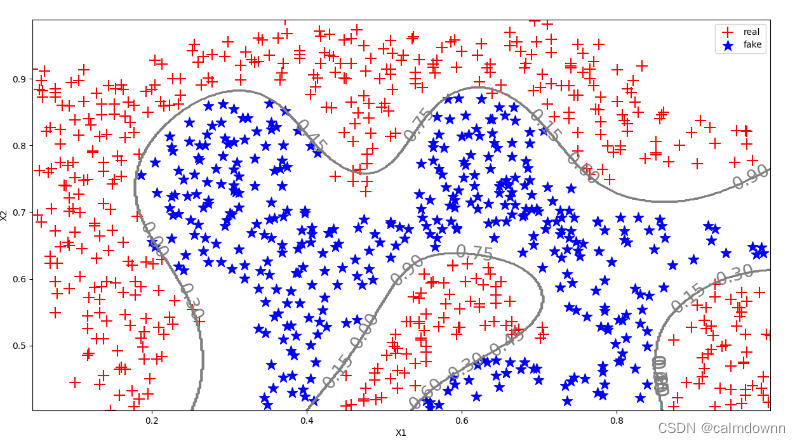
此次作业共可分为4个部分,前三个部分是利用支持向量机和高斯来对数据集进行分类,类似前几章的逻辑回归,第四部分是对垃圾邮件进行分类,理论什么的可以看看大神的笔记,讲的比较细致,数据集分别是ex6data(1-3),spainTest,spainTrain这次需要用到pandas中的pd.DataFrame()的方法,将数据集整合到一起并且准确找出特征值,sklearn工具包中包括了许多高级算法,支持
这篇是逻辑回归第一个任务的一个稍改动版,简单说一下代码的流程,需要知道细节的可以看看我前俩篇的逻辑回归,这俩篇分别是单分类和多分类逻辑回归,内容很细,这篇主要是为了上传一下完整代码。......
想使用这个接口,首先电脑得配备node.js,如果不知道node.js如何下载安装的可以点击这里,这篇文章前部分是下载安装方法,下面开始正文。
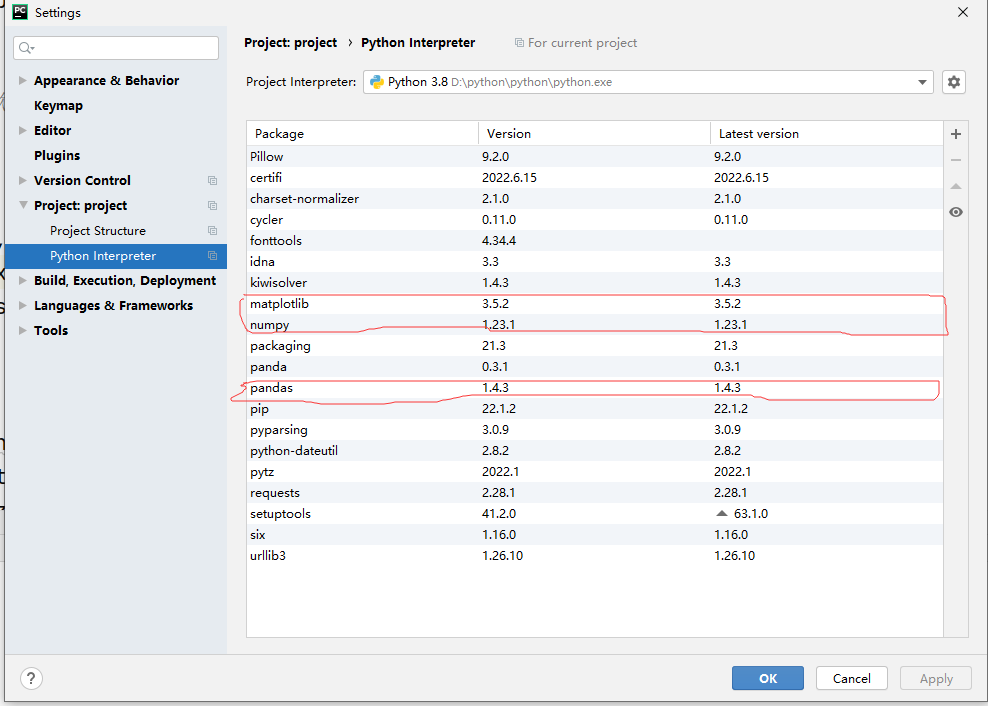
俩个方法在pycharm中导入pandas,numpy,matplotlib这三个包