




- @Landcc
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
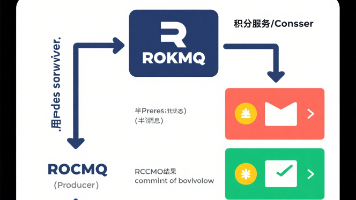
基于 RocketMQ 的可靠消息方案,本质是“本地消息表的 MQ 化”—— 把消息持久化、重试、回查逻辑交给 MQ,简化了业务开发。它的核心优势是“最终一致性 + 低侵入性”:只需关注本地事务和消费逻辑,MQ 自动处理消息状态、回查、重试。适合依赖 MQ 生态的项目,尤其是阿里系技术栈(如 Dubbo + RocketMQ)。理解这套流程后,面对跨服务事务需求,就能判断是否用 RocketMQ
大语言模型(LLM, Large Language Models)是当前人工智能领域最为热门的技术之一。它们基于深度学习,能够理解和生成自然语言,广泛应用于文本生成、自动翻译、聊天机器人等领域。与传统的自然语言处理模型不同,大语言模型具有超强的文本生成能力和上下文理解能力,能够完成复杂的语言任务。本文将带你走进大语言模型的世界,介绍其基本原理、训练方法及其应用。大语言模型(LLM)是人工智能领域的
大语言模型(LLM, Large Language Models)是当前人工智能领域最为热门的技术之一。它们基于深度学习,能够理解和生成自然语言,广泛应用于文本生成、自动翻译、聊天机器人等领域。与传统的自然语言处理模型不同,大语言模型具有超强的文本生成能力和上下文理解能力,能够完成复杂的语言任务。本文将带你走进大语言模型的世界,介绍其基本原理、训练方法及其应用。大语言模型(LLM)是人工智能领域的
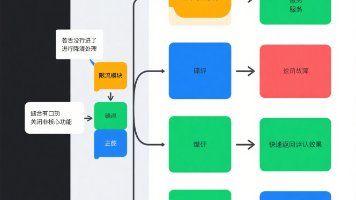
限流:守护系统 “入口”,防止流量洪峰压垮资源。降级:权衡 “功能取舍”,保障核心业务的连续性。熔断:隔离 “故障传播”,快速失败避免雪崩。三者并非孤立,而是协同工作,构建微服务的高可用防护网。在实际项目中,结合 Sentinel、Hystrix、Spring Cloud 等工具,可快速落地这些策略,让系统在高负载、故障下仍能稳定运行。(拓展思考:如何通过监控系统联动三板斧?比如限流触发后,自动调
深度学习是通过增加神经网络的层数(即“深度”),使模型能够自动学习数据中的高层次特征。相比传统的浅层神经网络,深度神经网络(DNN)能够处理更为复杂的任务,并且能够自动从数据中提取特征,无需人工干预。深度神经网络(Deep Neural Networks, DNN):通过堆叠多个隐藏层,处理复杂的输入数据。卷积神经网络(CNN):特别适合图像数据,通过卷积层和池化层提取局部特征,广泛应用于图像识别

Transformer、GPT 和 BERT 都是当前 NLP 领域最重要的模型,它们在架构、训练方法和应用上有所不同。Transformer 提出了强大的自注意力机制,GPT 专注于自回归文本生成,而 BERT 则通过双向训练提升了语言理解能力。随着这些模型的不断优化和创新,它们在各类自然语言处理任务中都取得了巨大的成功。本篇文章深入对比了 Transformer、GPT 和 BERT 的原理及
我想写一篇公众号文章,主题是‘如何高效阅读一本书’,读者是每天只有 1-2 小时阅读时间的上班族,他们总觉得‘读得慢、记不住、没时间’。“用公众号的口语化风格,写一段 150 字左右的内容,解释‘为什么我们读了很多书却记不住’,加一个上班族的具体场景(比如通勤、睡前),最后用‘其实问题不在……:“帮我设计一张《如何高效阅读一本书》的封面图:主视觉是‘一只手拿着书,书里飘出 3 个气泡,分别写着 “
我们有一个包含5000+条车辆电路图文档的资料库,用户查找文档时使用自然语言,导致难以直接匹配。需要一个智能助手通过多轮对话引导用户找到所需资料。
AI 助手不仅能加速工作流程,还能减少低效劳动,让你把精力集中在更重要的任务上。AI 可以帮助你自动生成标准化邮件回复,提高沟通效率。本文将介绍几个能够提高工作效率的 AI 工具,帮助你在日常工作中节省时间、提升效果,让工作变得更加智能和高效。数据分析与报表制作通常需要大量的时间和精力,AI 可以帮助你快速生成数据报告,自动进行分析和可视化。时间管理对于上班族尤为重要,AI 可以帮助你合理规划日程

训练自己的小模型不再是遥不可及的梦想。通过微调(Fine-tuning)或 LoRA 技术,你可以在大规模预训练模型的基础上,快速适应特定任务,并高效地使用资源。无论是文本生成、情感分析还是语音识别,微调和 LoRA 都为个性化的 AI 模型训练提供了有力支持。本篇文章介绍了如何使用 Fine-tune 和 LoRA 来训练自己的小模型,帮助你理解这两种方法的原理与应用。如果你有任何问题,或者想了
