




- @Eric005
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大型语言模型(LLM)的自回归生成本质,决定了提示词(Prompt)是约束模型输出分布、对齐任务目标的核心载体。提示工程并非「话术优化」,而是一门融合了自然语言理解、概率统计、推理系统设计与工程化迭代的交叉技术。本文基于Google官方白皮书的技术框架,从LLM生成的底层数学原理出发,逐层拆解输出配置的采样算法机制、12种核心提示范式的技术逻辑与适用边界、代码场景的全生命周期提示方案,最终落地为工
查看网页源代码—F12按住F12或者Fn+F12,弹出来的界面叫开发者工具左上角为选择按钮(点击之后再点击你想选中的内容他就会跳转到对应的代码)其中Elements为(元素)选项卡,找到对应的文本进行修改,网页就会对应的修改查看网页源代码—右键菜单通过此操作能查看所需内容再网页源代码的位置,通过此方式打开也能通过Ctrl+F搜索(显示的为网页框架)网址构成和http与https协议“ https:
该类用于实现随机森林分类器。__init__方法是类的构造函数,用于初始化随机森林的参数,包括决策树的数量、最大深度、子空间维度和随机种子。是一个空列表,用于存储随机森林中的每棵决策树。fit方法用于训练随机森林模型。对于每棵决策树:调用sample函数对数据进行自助采样,得到训练样本X_sample和对应的标签y_sample。使用随机选择个特征,得到特征子空间的索引。从采样数据中提取特征子空间
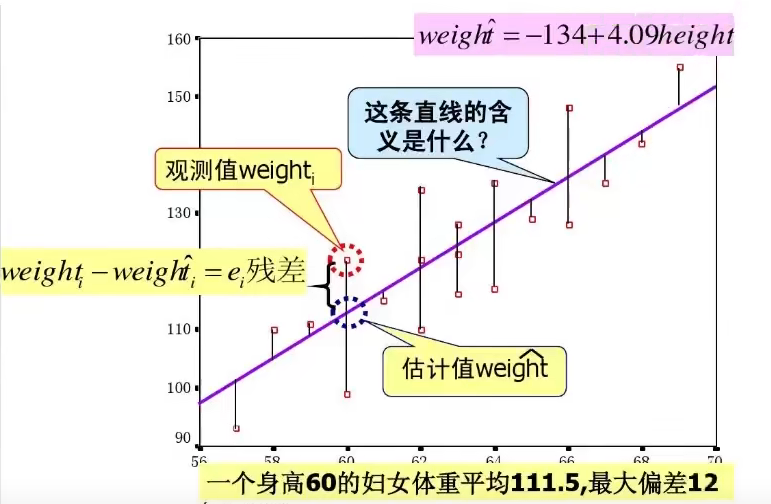
x轴叫阈值,图中的两条折线分别代表各分位点下的正例覆盖率和1-负例覆盖率,通过两条曲线很难对模型的好坏做评估,一般会选用最大的KS值作为衡量指标。通常绘制ROC曲线,不仅仅是得到左侧的图形,更重要的是计算折线下的面积,即图中的阴影部分,这个面积称为AUC。其中,α为学习率,也称为参数βj变化的步长,通常步长可以取0.1,0.05,0.01等。所以,性别变量的发生比率为e** β1,表示男性患癌的发
在大数据分析中,回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。
那么解决方法就是,一种是设置k近邻样本的投票权重,使用KNN算法进行分类或预测时设置的k值比较大,担心模型发生欠拟合的现象,一个简单有效的处理办法就是设置近邻样本的投票权重,如果已知样本距离未知样本比较远,则对应的权重就设置得低一些,否则权重就高一些,通常可以将权重设置为距离的倒数。对于连续型的因变量来说,则是将k个最近的已知样本均值用作未知样本的预测。还有一种方法是,采用多重交叉验证法,该方法是

在我们学习了后,我们在实战练习一个例子。你的主要任务:学习如何使用简单的循环神经网络(Vanilla RNN)生成诗歌。亚历山大·谢尔盖耶维奇·普希金的诗体小说《叶甫盖尼·奥涅金》将作为训练的文本语料库。
使用来自“torch.nn”的类更安全、更正确,但是,在专用于“Pytorch”的各种资源上,经常可以找到来自“torch.nn. functional”对象的使用,因此我们认为有必要讲述这种使用激活函数的方法。我们看到图形边缘的近似值存在缺陷,这主要是因为在我们的原始样本中,坐标取自正态分布,因此很少有物体位于 -3 和 +3 的边界之外,这意味着我们的神经网络训练的先例很少。粗略地说,神经网络
你的任务是建立一个用于 CIFAR 图像分类的神经网络,并实现分类质量 > 0.5。:因为我们实战1里只讨论最简单的神经网络构建,所以准确率达到0.5以上就符合我们的目标,后面会不断学习新的模型进行优化CIFAR的数据集如下图所示:下面我们开始构建模型。